BMW Group - Unified Sales Platform
LeSS adoption at a bavarian car manufacturer
Background
Valtech Germany was the selected supplier to help applying agile development to create the new BMW i car direct-sales process of the BMW Group. This required new supporting IT systems, all embedded into an existing IT landscape with more than 80 affected systems. There was a large program spanning many projects to create new supporting systems.
One of these projects was the new Unified Sales Platform (USP) system. USP was implemented from scratch and has integrated more than 30 external system interfaces. Other partner projects for the BMW i rollout remained in their non-agile process models. Therefore common milestones, reporting and collaboration across the projects became a challenge.
After developing for more than 2 years, USP was released in time, with high customer (BeNeLux market) satisfaction and high quality.
Phase 1: Before Multiple Feature Teams
In February 2012 USP development started in a challenging environment:
- high time pressure, because of the already defined launch target date
- the direct sales business process was still under discussion; not defined
- therefore the scope of the USP product was pretty unclear
- the majority of participants were not familiar with BMW Group business/sales processes or agile methodologies
- the USP project was embedded into a traditional program management system (the BMW i program)
Because of the mentioned circumstances the USP project decided to use Scrum and agile engineering practices to get early and continuous feedback about the product progress and the organizational progress. Development started first with one Scrum initial team to create a solid basis by finding and establishing the appropriate agile development process, development infrastructure and collaboration models with the business departments.
This initial team evaluated the tools they needed, set up the development environment and the continuous integration system, experimented with different Sprint lengths, and implemented the first business functionality to verify that the new organization could work.
Since the first Sprint the USP team demonstrated running and tested software after every Sprint.
Over time additional people were added, organized in traditional functional and component-team structures, reflecting the standard model used in the broader BMW i program.
This organization was used up to a USP Release 1.0.
Phase 2: Transition to Multiple Feature Teams & LeSS
The structure for Release 1.0 was adequate, but it was predicted (by us coaches) that it wouldn’t scale well for the next (and bigger) release. There was a need to be more flexible (agile) in the teams because priorities and requirements changed frequently. Different teams needed to be able to select various items from the Product Backlog, and be able to do complete end-to-end features. And there was a desire to reduce total feature cycle time from “time to market”.
In the prior organization, a team could only do one specialized functional or component kind of work. That constrained the ability to change Product Backlog priorities and flexibly “go to where the new work is.” And it lengthened average cycle time with handoff and delay between specialist groups. Plus it increased the coordination and integration effort and problems.
Therefore, in response to our suggestion, it was agreed to reorganize into multiple feature teams, working together in a LeSS adoption.
The goal was to create five new cross-component and cross-functional feature teams.
Due to existing commercial contracts and program-wide policies, the USP project group could not completely be reorganized into just feature teams. For example, there was a UI design governance group for UI consistency across the entire program. And there was a test-management group that coordinated program-wide test activities with other partner projects and provided reports to the overall program. This group did not do testing; that was still done by the implementing teams themselves. But the test-management group contributed to the “undone” department as well, such as organizing penetration (security vulnerability) tests by external companies. Plus, program policy required a project management group, that did reporting up to the (traditional) program management, and staffing, facilities, and equipment management.

Self-Designing Feature Team Workshop
It was also agreed to reorganize into feature teams with a self-designing team workshop, one of the LeSS experiments.
It took the group 3 cycles (each 20 minutes) to come up with an organization matching the vision: all feature teams should be able to work independently on all Product Backlog items across all stakeholders/requestors.
After forming the new teams, they created their new team name, found their team room, elected their Scrum Master and a “lead” developer (still a required role due to policy).
The whole self-designing team workshop lasted about three and a half hours.
Details about the self-designing team workshop can be found here
Team-Building Workshops
A self-designing team workshop is a great start. But at the end of the self-designing team workshop there are new formed teams and they have to cope with new dynamics. This transition to feature teams, according to LeSS, was a serious change of the old system. The project group faced two aspects of scaling. At first, cross-team collaboration, working with all teams following the priorities of the one Product Backlog. This was covered and organized by our Sprint ceremonies and synchronized meetings in the LeSS context. The second aspect was related to the available knowledge within the teams. All teams got team members with knowledge of different components. But they represented a kind of bottleneck within the team and therefore this situation was an impediment for scaling. To improve on a systemic level it was needed to improve the knowledge sharing within the team. In addition it was an aim of the project management team to get these new teams as soon as possible effective again. Therefore the project management offered each team the opportunity to do an additional moderated team-building workshop. The purpose of this workshop was to lower social barriers, initiate measures for knowledge sharing, finding working agreements and reflection of team dynamics in a team challenge.
Workshop agenda:
| Duration | Topic |
|---|---|
| 00:05 | Introduction/agenda |
| 00:10 | Ice breaker exercise |
| 00:30 | Team Knowledge Model (agile world 2013) |
| 00:45 | Agree on measures |
| 00:30 | Team Vision/Charter |
| 00:50 | Team challenge (outdoor) “Toxic waste” |
| 00:10 | Closing/Feedback |
| 03:00 | Socializing: Lunch or dinner |
The workshop took about three hours, followed by a lunch or a dinner. Some of the agenda topics are described in the following paragraphs.
“Team-Knowledge-Model” and “Agree on measures”
In this workshop the team members used the Team-Knowledge-Model (TKM) to visualize the knowledge distribution across the team members.
The teams did the Team-Knowledge-Model on a business and on a technical skill level.
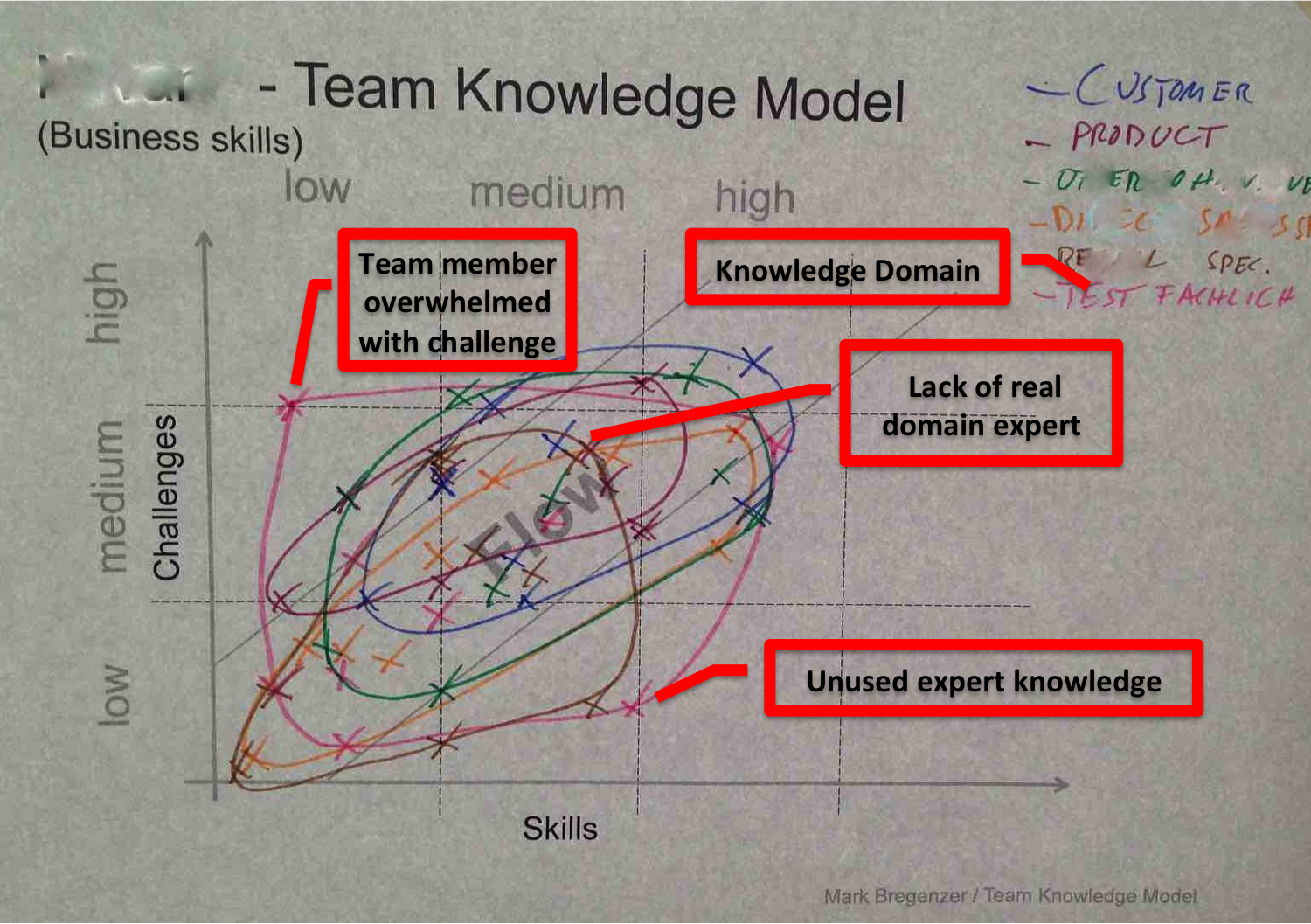
In a TKM model all team members show their balance between skill-level (X-axes) and daily challenges (Y-axes) according to the project related knowledge domains. These axes are split into three areas: low, medium and high. Low means in terms of the challenges the team member has no or very simple tasks to do in that specific knowledge area. High challenges indicate that the team member works on high sophisticated tasks. Low, medium and high at the skill level could be understood and/or replaced by the experience level of Shu, Ha and Rhi as mentioned in LeSS.
The example above shows two X’s related to the “TEST FACHLICH” domain. One team member indicates, that her/his knowledge is sufficient for their daily work (currently learning by doing). Another team member has quite good knowledge about this domain but doesn’t work on that domain (that’s somehow waste of expert knowledge). If these two team members pair for tasks in that domain, both can benefit and return very fast into the flow area.
Furthermore the model shows that the team has got nearly all the needed knowledge within the team except the brown-colored domain. In this domain the team needs some help from other teams to increase the team knowledge quite fast. Click here to learn more about the Team-Knowledge-Model
After visualizing the knowledge distribution in a TKM, the teams defined based on these models appropriate measures to improve the knowledge distribution within the team e.g., by defining pairs to work on specific topics, organizing team coding dojos, etc. Some raised afterwards the need of cross-team knowledge sharing and initiated therefore Communities of Practices.
By this model the teams could get feedback whether the they have the right knowledge for their work on the Product Backlog or if they have some knowledge gaps. Based on this visualization each team defined and agreed measures to improve, e.g. who will do pair-programming, organize coding or testing Dojos, other training sessions, pair-working, reading books and sharing afterwards… These teams became aware of being self-responsible for individual and team learning as part of continuous improvement.
“Team Vision/Charter”
The team vision or team charter can help the team to focus on the same direction. So during this activity they created a vision e.g. “We are open minded, willing to improve and support each other.” or a team charter, where some teams defined rules like do’s and don’ts or defined other working agreements like: “We do pair-programming at least once a day”, “We keep our regression tests green”.
“Team challenge (outdoor)”
With the outdoor team challenge the team got the possibility to reflect on how they work together. How the team communication works, or how they act under time pressure. There were several iterations possible if a team didn’t succeed within the given time. This is a default procedure and is intended so that the team can reflect on their approach. Then they started another round. Some took three rounds others, while others succeeded in two. After the challenge, they all got a common understanding, that they succeed by good communication, inspect and adapt and involving all team members.
After the workshop the teams went for a sponsored lunch or dinner as they prefered. There the team members shared their insights and experiences about the workshop and deepened their understanding of their team dynamics.
One Product Backlog
As required in LeSS (because it supports whole-product focus, transparency, and simplicity), there was just one Product Backlog, worked on by all the feature teams. And after the transition to feature teams that could do end-to-end customer features (rather than component teams and single-function teams), each item in the Product Backlog represented a complete end-to-end customer feature.
To satisfy traditional project reporting of the overall program, we created an automated reporting solution that extracted data from the one Product Backlog, and presented it in a way familiar to the traditional “waterfall” program management group.
Product Ownership & the Design Governance Group
Complementing the one Product Backlog, in LeSS there is only one Product Owner prioritizing it, so that there is a strong and cohesive vision from someone with a strong sense of product ownership. In contrast, there is a default policy that the BMW Group does content, scoping and prioritizing decisions in a governing board. Many stakeholders across different business departments have to be included, if decisions will be taken. Therefore, a BMW Group project has a “design governance” group. This group does the prioritization work as team. This is of course not the same as the standard LeSS organizational design system, but was the art of the possible, and such organizational compromises are especially common when a new way of working is introduced by an outside group (e.g., Valtech DE) rather than internally.
The ordering of the Product Backlog was done in conversation with all stakeholders. The following criteria influenced the order:
- Legal aspects
- Stakeholder target dates/milestones
- Expected value
- Possible risk reduction
- Remaining project budget per stakeholder
Related to the LeSS principle “Whole Product Focus”, once a Sprint (biweekly) the group did an overall Product Backlog refinement workshop with delegates from feature- and cross-cutting teams.
The design governance group organized the interaction between the different business departments (Subject Matter Experts) and the feature teams. Together with the feature teams they made sure that conflicts of concurrent requirements were solved before the according backlog Items were taken into a Sprint. Design governance group members also organized and participated at the feature team Product Backlog Refinement workshops.
Our Sprint Ceremonies in LeSS
In phase one the USP project started nearly on a green field. The system was build from scratch. The business department, responsible for the new BMW i sales process got just a system proposal, created in a traditional way. Therefore it was reasonable to break down this system proposal into backlog Items, in our case we wrote user stories with acceptance criteria. This was done on a very high level at the beginning of the project. Over time the teams refined these items according to their priority together with the subject matter experts from the business departments. There was a 1:1 relationship between business department/subject matter expert and a team. Coordination of functional aspects was done at governance group and business department level. Technical aspects were coordinated between the teams in a Product Backlog Refinement meeting in the mid of the Sprint as preview of the following Sprint and in a synchronization meeting at the end of Sprint Planning 1. In both meeting delegates from all teams participated.
The project agreed on following “Definition of Ready” (DoR) valid for all teams:
- Technically feasible
- UI mockups designed
- Acceptance criteria available
- Product Owner agreed
- Security, roles and rights defined
- Estimated
The governance group prioritized only Items matching the DoR for the next Sprint. The teams prepared a maximum amount Items for the next one and a half to two Sprints, according to the group’s velocity.
In phase two of USP, after transforming to feature teams the procedure of refinement changed. Now the project had to cope with requirements from different stakeholders, sometimes conflicting with other requirements or existing functionality. User stories as exclusive items were not sufficient anymore. The gap between the desired functionality from a stakeholder and existing functionality had to be expressed. Therefore the project group introduced the term topic, which described the difference between desired and existing functionality. At this level possible conflicts between requirements of stakeholders were solved. The design governance group was responsible for the topic level. They solved upcoming conflicts with the different business departments before they defined conflict free and roughly refined items. Together with the feature teams they did the further refinement of the items, which were handled as was used to be in phase one.
Scaling our Coordination & Integration Techniques
In LeSS, it is recognized that really strong continuous integration practices are critical for scaling success, so much so that it is one of the guides within the “technical excellence” section of LeSS. It enables coordination, internal open source, increased transparency, and whole-product focus. Thus, the USP group invested in improving the developer behaviors of integrating continuously, and also a powerful continuous integration (CI) system and related processes.
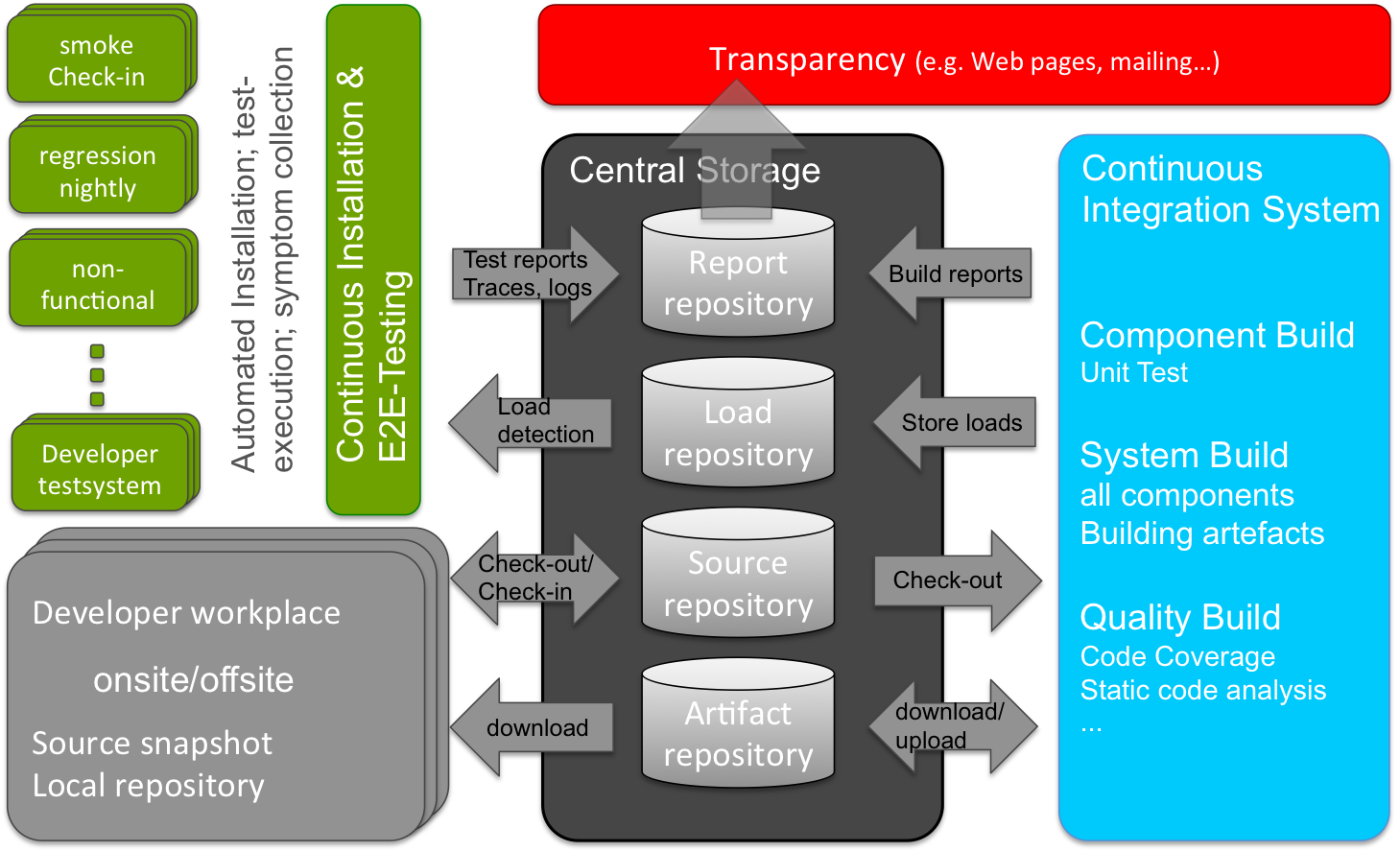
The heart of the CI system is the master-build concept. Every artifact (e.g., JAR files, configuration data, tests, etc.) needed for deployment or verification are bundled with a master-build number. All results (e.g. build artifacts, test results, logs and traces) of this system are stored with reference to it’s related master-build number in a central repository.
The CI system executes in 3 steps, by 3 major components:
- Compile and build the executables.
- Deploy and test, which deploys master-builds on target systems, executes end to end tests, and stores the according results, logs and traces in the central repository.
- Report on the results, creating a master-build history table, which shows the master-build numbers and all corresponding results. And then email interested people with a link to the reports.
The technical view on this concept shows that it is highly scalable and it doesn’t matter if developers work onsite, offsite or even offshore.
Each system build, created every 15 minutes, was tagged with a dedicated ordered version number. The latest successful (non-failing unit and module tests) system build was deployed on a target-similar environment.
Afterwards the end-to-end tests on smoke level were executed. The smoke level describes a subset of the automated regression tests reflecting the most important test scenarios to get fast feedback for developers on integration level. The test results were connected to the master-build number and documented in the master-build history table.
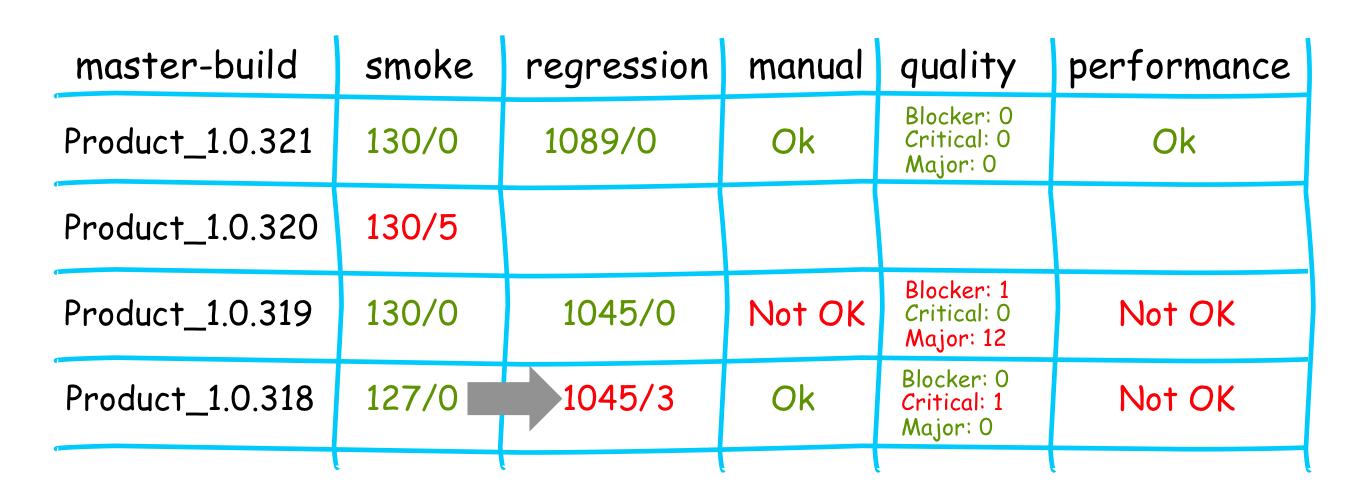
Only master-builds with successful smoke test run results were taken into the next stage. The next stage was the automated regression runs. As part of the “Definition of Done” the teams implemented the acceptance criteria of an Item into an automated regression test (“executable requirements”). All available regression tests were executed in this stage. In parallel some quality runs, such as Sonar runs or performance measuring were executed as well. These results were documented in the build history table of the corresponding master-build.
All tests were tagged with a reference to the related Product Backlog item and therefore to the functional structure of the USP areas. So it was possible to see in which functional area of the product a problem exists and which was fine.
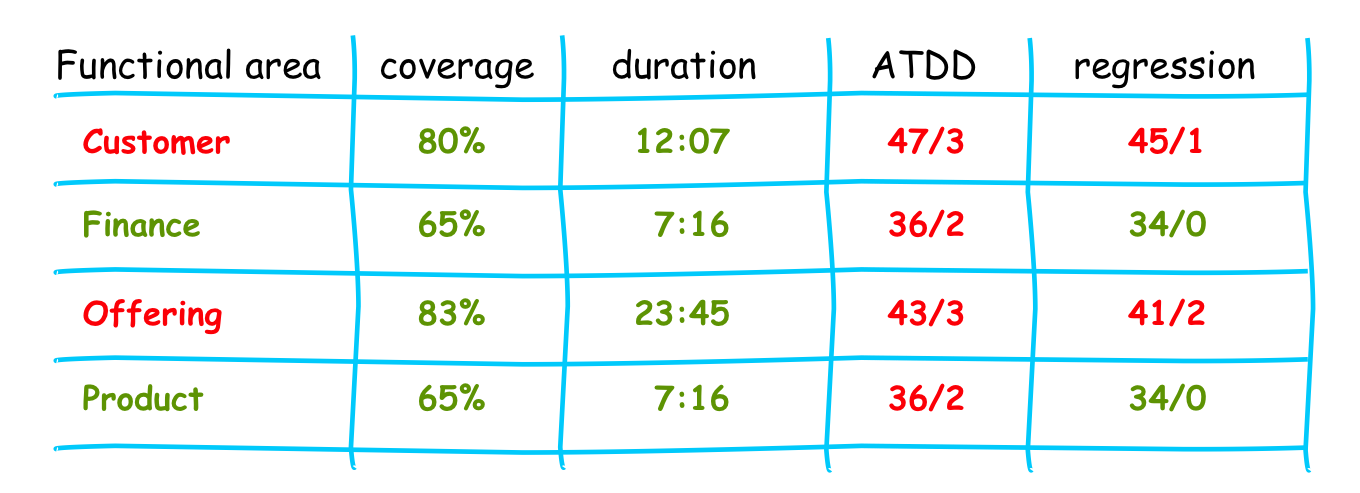
By clicking through the areas all group members were able to drill down to the problematic item and could analyze the problem from a functional perspective i.e. which acceptance criteria was broken. Of course at the lowest level (not shown) the connection to the technical/code level was provided e.g. expected amount of list entries was <2> and received <0>, or exceptions details….
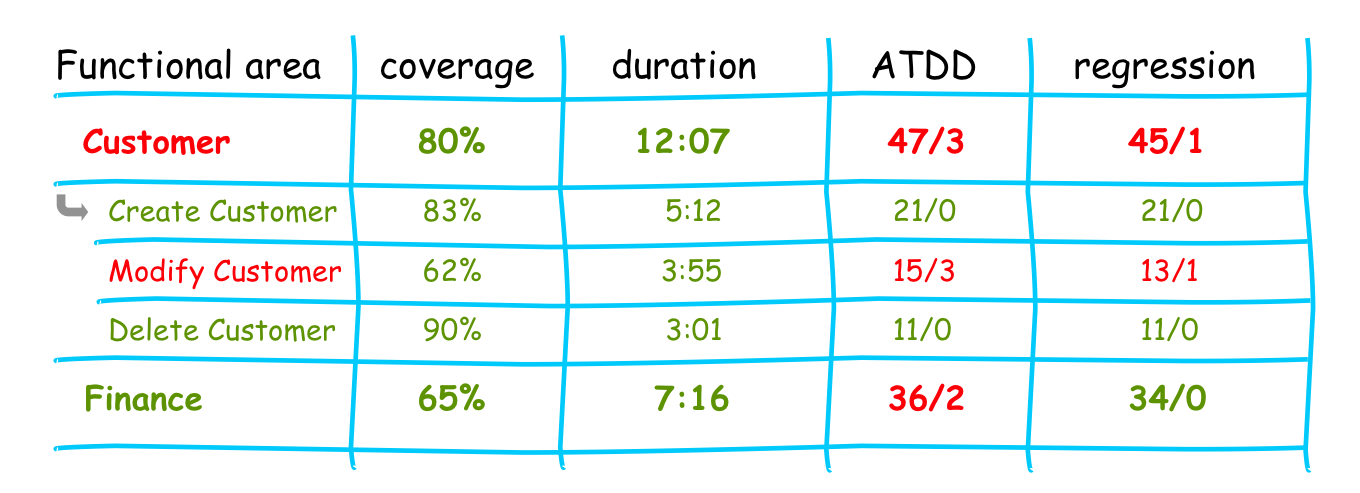
So everyone could immediately get an overview about the current functional quality of a dedicated master-build.
Feedback Cycles
Especially in large-scale development in LeSS, short CI system feedback cycles are critical because it is not possible for everyone to be talking together all the time, so the CI system needs to become a signalling tool that tells the group quickly when there are problems. Then people can figure out who to talk with to coordinate on solving the problem. In this way, a CI system with fast feedback becomes a tool for coordination.
Calculated from the check-in the continuous integration team was able to keep the fast feedback cycle time for smoke runs between one and one and a half hour. Regression results were available two to three times a day, approximately duration of three to five hours
By a growing functionality of the system the amount of tests increases as well. To keep the cycle times low it’s necessary to parallelize the test runs. This requires more virtual servers and of course more hardware, too. A master-build was deployed on several servers. Tests were split into functional areas according to their tagging (e.g., “finance tests”) and executed on different servers at the same time. Afterwards the test results were merged to a single report.
Structural Aspects
In addition to the environments for automated testing, there were two environments fully integrated with all other relevant BMW Group IT systems for manual testing. Acceptance of item, as required by the “Definition of Done” (DoD), was only possible on these two systems. Also, each feature team got their own test environment for internal exploratory testing. They were able to add new functionality on these test servers and run the test automation against it. Benefit: fast integration feedback before check-in. All these servers were deployed according to the BMW Group staging process via a central Jenkins server.
All other stakeholder could see the displayed master-build number and look in the build history table the functional quality of the current installed software very easily. Green smoke and regression runs were conditions of the overall DoD. Therefore everyone could verify if an implementation had side effects on existing functionality.
Coordination on Failed Builds
The CI system sent out an email with a functional result overview to people after each build/test run. This email contained additionally links to the functional and technical build details provided by the CI system. A so-called “regression daily”, short stand up meeting with delegates from each team was used to coordinate the activities in case the regression run overnight failed.
System Integration
The BMW i program planned an overall six month system integration test phase. There was a fixed code freeze for all related projects announced. Because the USP project was able to deliver high quality software, the BMW i program requested more features and changes as last minute wishes of the markets. So they skipped the code freeze for the USP project. Until two weeks before technical “Go Live” the USP delivered new functionality every week (still having
bi weekly Sprints) into the overall system integration environment. During this period the overall test management, incl. test units in the markets found 95% less defects than in one other comparable BMW Group project. And one-third of those small number of defects were not related to the USP functionality. No critical issues related to USP functionality, which blocked the business and / or couldn’t be solved within very short time periods were discovered in the first five weeks after the “Business Go-Live”.
So the automated test and integration practices of this group strongly contributed to the overall success.
Conclusion
In our coaching of USP we followed the LeSS principles. Very important was the “whole product focus” so we integrated all relevant partner systems in the own development process. As part of the “Definition of Done”, the project defined and executed integration tests of the overall program BMW i from the beginning. Together with the functional test automation, it was a major contribution to the successful launch in autumn 2014. According to my experience with comparable projects the USP project reached an outstanding quality.
Furthermore the project’s transparency and customer centric (LeSS principles) approach, by showing them (as per LeSS) running software every common-to-all-teams single Sprint and on demand throughout the project and adjusting the Product Backlog according to the customers feedback, ensured the high customer satisfaction.
Through empirical process control the project was able to provide realistic, fact-based, concrete-running-features progress forecasts (versus the illusion of “Gantt chart progress”), improving predictability and reliability. The high quality created trust by the overall program and traditional test management, customer and partner system. While other partner systems had to stick to their traditional integration test phase, the USP project was allowed and able to deliver new features (“late” changes) until two weeks before technical GoLive!
LeSS and agile principles provided an excellent guidance throughout the project and they were in many cases the basis for critical project decisions.