 by Yi Lv
by Yi Lv(Originally published by Lv Yi on June 12, 2019)
In this article, we shall look at the structure of functional and component teams, explore the dynamics around their backlogs, analyze its impact on agility, and find the lever to optimize for agility.
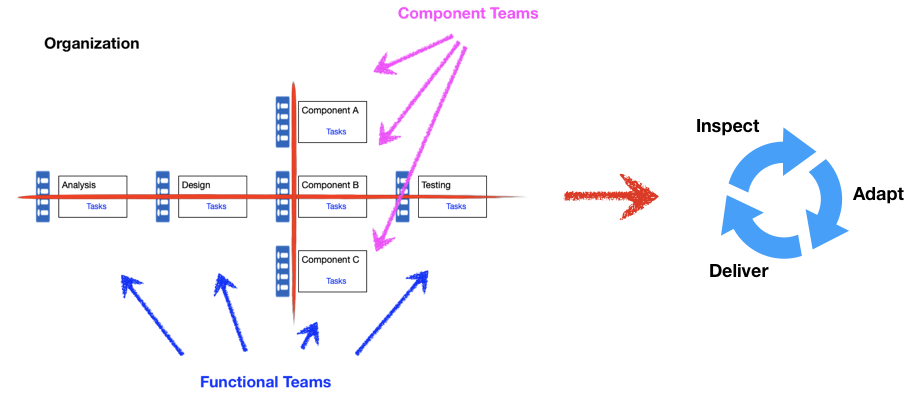
A functional team is responsible for functional work such as analysis, design, implementation, and testing. Component team is responsible for the implementation of various technical components, such as component A, B and C. Each team has its own work and priority, thus, its own backlog. For overall value delivery, it means that the required work is in multiple backlogs which are dependent on one another.
Let’s step back and first ask the question: why more backlogs? The answer lies in “efficiency thinking”.
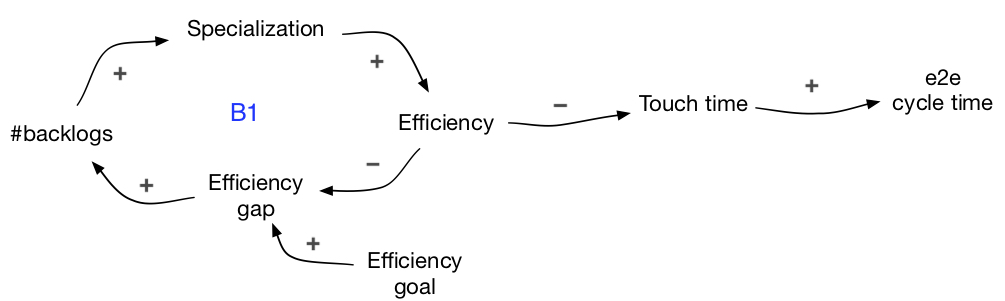
B1-loop: specialization for efficiency
Organizations have either an explicit or implicit efficiency goal. The difference between this goal and reality causes an efficiency gap. Creating more backlogs, leads to specialization and, it theory, to higher efficiency, which reduces the gap.
Higher efficiency should also lead to shorter touch time (i.e. the time used to process the work in a function or a component), thus, shorter end-to-end cycle time. However, we need to understand what percentage touch time accounts for in the whole e2e cycle time, and to see a bigger picture.
Let’s see more factors having impact on cycle time.
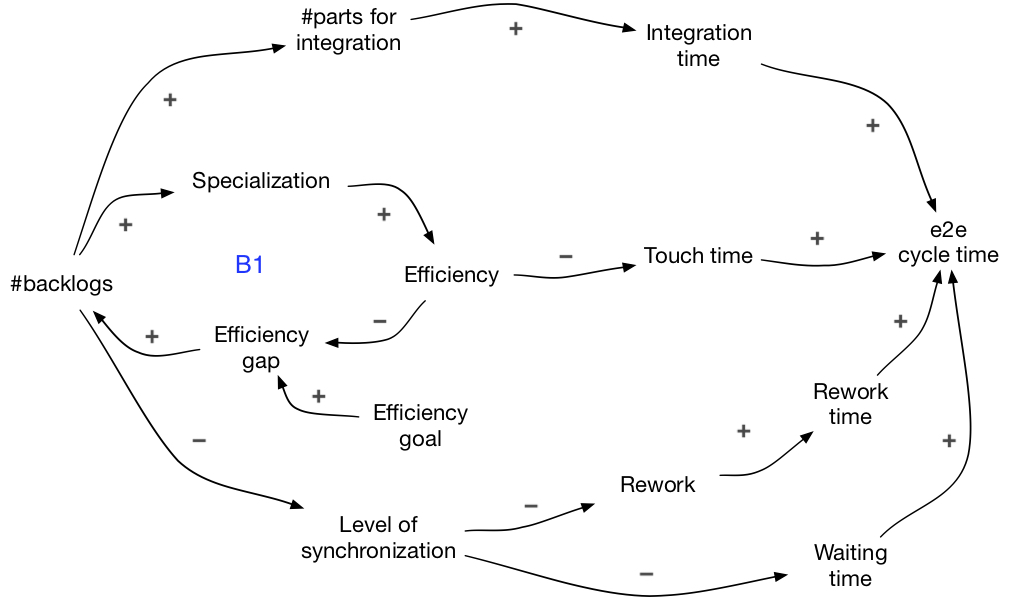
In the upper part, more backlogs lead to more parts for integration, longer integration time, longer e2e cycle time.
In the lower part, more backlogs lead to lower level of synchronization (different parts are being worked on at different times), which leads to: 1) more rework, thus, more rework time, and 2) longer waiting time. In both cases, longer e2e cycle time.
Even though having more backlogs may lead to shorter touch time, other factors create negative effects on the whole cycle time. It is often the case that touch time is not the most significant part, while waiting and integration account for much more.
Let’s return to efficiency. As we analyzed earlier, it is the efficiency goal that drives toward more backlogs. Now we shall see the unintended impact on efficiency.
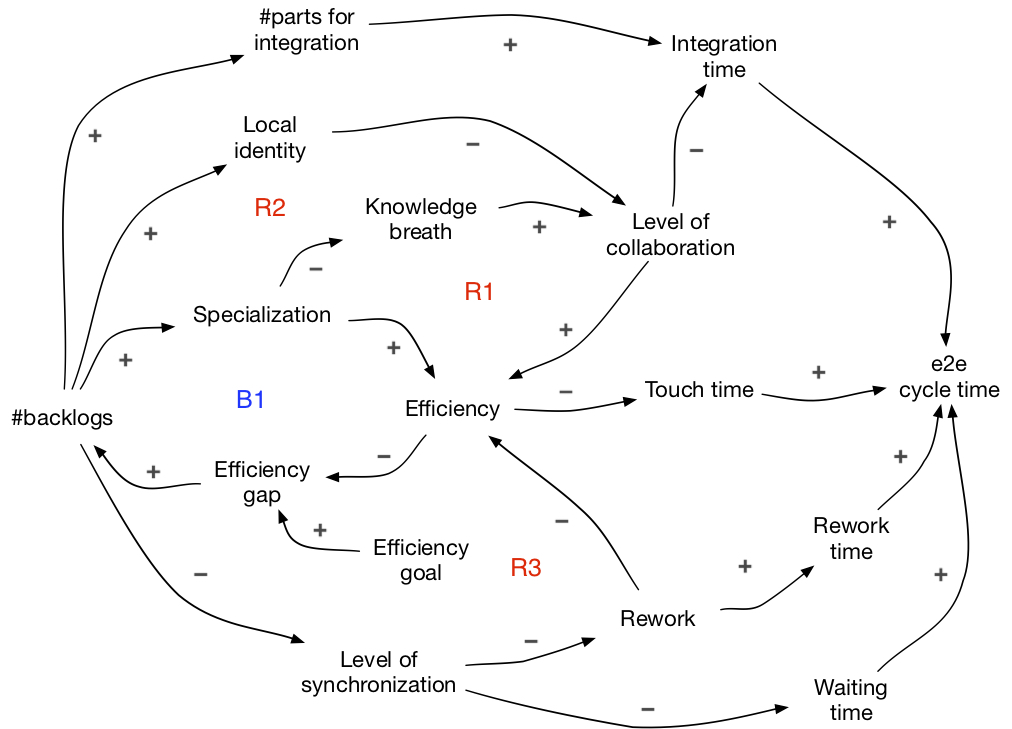
The level of collaboration is one commonly overlooked factor. A unit of work does not stand alone, but needs to be integrated with other units. Integration requires collaboration with others. Thus, the level of collaboration affects both time and efficiency. Let’s see which dynamics create negative effects on collaboration.
R1-loop: Over-specialization hurts collaboration
More specialization leads to deeper but narrower knowledge. The knowledge breadth is important for collaboration. In fact, the overlap in knowledge among collaborators helps a lot in mutual understanding. On one hand, narrow knowledge decreases efficiency, thus, creates the R1-loop. On the other hand, it creates more negative effects on integration time, leading to an even longer e2e cycle time.
R2-loop: Local identity hurts collaboration
More backlogs leads to stronger local identity, which means that one group only works on a specific function or component, while another group is not allowed to touch it. These are functional and component silos, and they hurt collaboration. This both decreases efficiency and worsens the integration time, thus even longer e2e cycle time.
Another dynamic comes from rework, which also creates a negative effect on efficiency.
R3-loop: Rework hurts efficiency
When work is done asynchronously, hidden problems are commonly discovered during integration and often require redoing parts that were considered complete. So, the rework caused by the asynchrony (i.e. low level of synchronization), which is caused by having different backlogs, decreases efficiency. This creates the R3-loop.
Overall, B1-loop aims to increase efficiency, but it creates unintended consequences on collaboration and rework and worsen the e2e cycle time. B1-loop and R1..R3-loop form the system archetype called “fixes that backfire”.
Let’s see how to drive toward fewer backlogs.
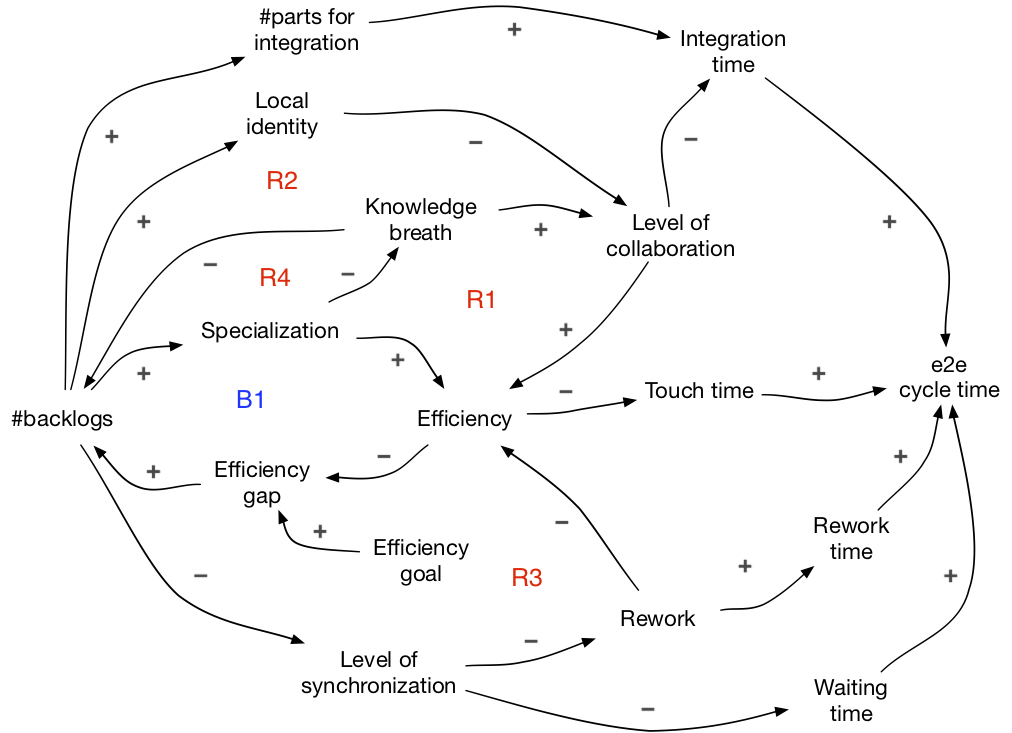
R4-loop: fewer backlogs drive broad learning
More backlogs lead to more specialization and narrower knowledge. Then, the narrow knowledge becomes the cause for more backlogs creating a reinforcing R4-loop. It is easier to work in the direction of more backlogs. How could we turn this around?
Take the same reinforcing loop and read it like this: fewer backlogs, less specialization, broader knowledge, even fewer backlogs… The challenge is that less specialization does not lead to broader knowledge by itself. We need multi-learning to increase the knowledge breadth.
Fewer backlogs drives multi-learning; multi-learning enables fewer backlogs. They are mutually reinforcing. Therefore, the number of backlogs itself is an important lever - have one backlog by creating a real cross-functional and cross-component feature team.
What do we mean by multi-learning? The backlogs are based on functions and components here, thus, we do cross-functional and cross-component learning.
What are the techniques enabling cross-functional and cross-component learning? Below is a list of well-known techniques, and many of them are in LeSS guides:
In summary, separate backlogs for functional and component teams are created for higher efficiency, but they create unintended negative impact on the overall e2e cycle time, and even worse, overall efficiency itself. Multi-learning enables fewer backlogs, while fewer backlogs in turn drives multi-learning and improves delivery capability.