Sys Store (pseudo name)
(Sys is a fictious name as the company preferred the case study to not be published under their name)
Discovering “Why LeSS?”… the Hard Way, at Sys - a Global Player in the Software Industry
Preface
Business Agility can be defined as an organization’s ability to re-invent itself and to quickly adapt to changing circumstances. In his book Rethinking Agile, Klaus Leopold proposes that in order to achieve business agility you need to optimize the flow for delivering customer value. By doing so, sooner or later, you will notice what changes to the organizational structure are needed to support this flow.
First of all, it is crucial to understand that the actual meaning of agility, as conceived in the Agile Manifesto, is not the speed of an organization to deliver customer value, but the adaptiveness of an organization to respond to changes rapidly at a very low cost. (See the Be Agile chapter in Scaling Lean & Agile Development). Still, Leopold has a point regarding organizational change: that with continuous attention to the system optimizing goal people will notice the elements that stands in the way to make improvements. But with systemic thinking, lots of time observing and working at the place of real hands-on work, and reflection about the existing system dynamics, people can also anticipate the relatively obvious existing organizational impediments that block the ability to adapt quickly. This is a story of the slow and painful path of an organization learning to eventually see the organizational impediments to adaptiveness at scale, made worse by many management attempts to maintain minor variations of traditional management status quo while just re-labeling things as “agile”, rather than anticipating – or being willing to anticipate – the relatively obvious impediments and making the needed changes at the start. In short, this story demonstrates the opposite of the key LeSS adoption rule, “For the product group, establish the complete LeSS structure at the start; this is vital for a LeSS adoption”, and the consequences of that.
So, the following case study demonstrates what happens if you don’t put that organizational design in place from the start. By starting with traditional management and organization, perhaps with some minor faux-Scrum elements mixed in, the organizational design required for LeSS might emerge. But it will be definitely a much longer and a more dangerous journey, as it is likely to not create the benefits intended by adopting LeSS. Why? Because by not immediately installing the new design, the strong organizational forces to remain in the status quo will very likely win (see Larman’s Laws of Organizational Behavior).
A key “counter factual” insight from this case study: If you want to kick-start your journey to Business Agility and save yourself a lot of pain and also quickly get the intended benefits of LeSS for adaptiveness, put the expected organizational structure in place at the beginning of the adoption as expected by the LeSS rules.
Some general remarks before we start
LeSS is Scrum (with multiple teams) and Scrum is one-team LeSS. (See Principle Large-Scale Scrum is Scrum). Still, in order to be precise, in the course of this case study, I will clarify which rules are taken from the Scrum Guide and which rules and guidelines are from LeSS. During my engagement as described in this case study, I was positively influenced by the information on the less.works site, went to Bas Vodde and Craig Larman’s LeSS practitioner courses and spent a lot of time reading the first two LeSS books. The third LeSS book was unfortunately not out at that time. In this case study I have illustrated the LeSS experiments that we tried, and I have also referenced the LeSS principles, rules, and guides that we followed without being aware of them at that time.
Introduction
The following case study covers the time that I spent as an external coach within the IT organization of company Sys from February 2015 to September 2016. Sys, is a German-based global player in the software industry. Due to the signed NDA I’m not allowed to share real names or other company specific information. By the end of 2014, Sys embarked on a journey to replace all existing external partner platforms with a platform that revolutionizes the way the company sells its software. Its launch marked a milestone towards Sys’s move into a new approach of e-commerce, rethinking not only how to sell software directly to customers, but also what to sell (e.g. data in addition to software) and how to charge.
The idea behind the Store was to create a web-shop where customers could discover, try, and buy software, content, or data from Sys and other third-party software with only minimal interaction. The goal was to include different deployments of products (on-premise as well as cloud solutions), to allow different types of payments (credit card and PayPal) while providing an Amazon-like simple process, using the web e-commerce product “SAP Hybris Commerce”.

I was working within the Sys IT department that is responsible for all internal and external platforms, like the Sys Store, in 2011, when the whole department started replacing waterfall development with Scrum. After building a couple of platforms with (one-team) Scrum I left the company to support other clients on their Agile journeys and rejoined early 2015 to support this important endeavour.
The situation before the change
System Architecture
When I joined, four different teams were working in parallel on either new features or enhancing the existing platform, having a fixed timeline for merging the code, weeks of integration testing and user acceptance tests. The system landscape was a complex 3-tier landscape including the main J2EE web application platform SAP Hybris Commerce based on the Spring framework, the SAP Hana DB for data storage, a synchronization with SAP ERP and SAP CRM over SAP PI servers and many additional third party services for analytics, the handling of credit card payments or the integration of user-generated-content.
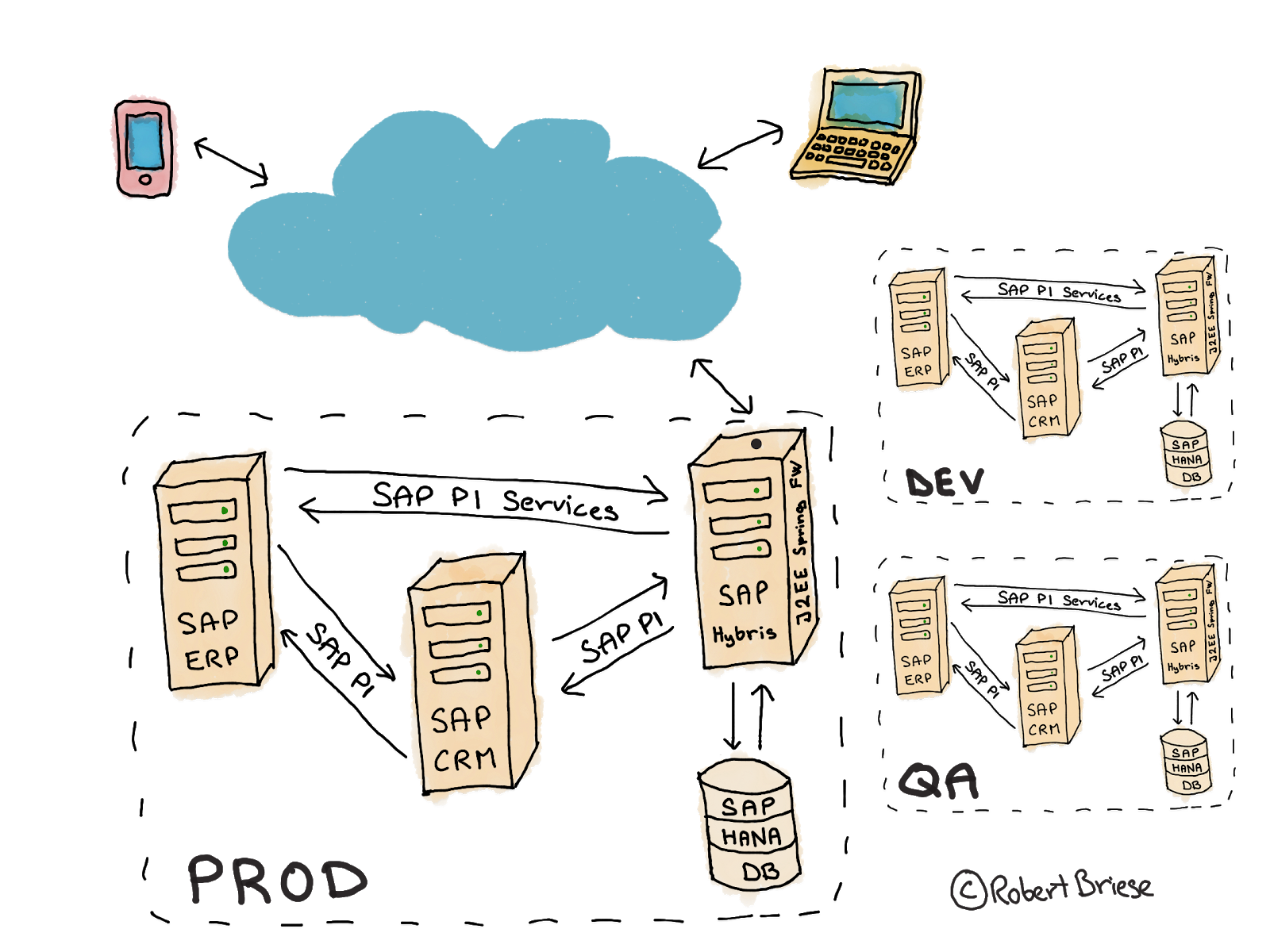
Organizational setup before the change
The organizational setup was as outlined in Figure 3. There were three development teams: two in Europe and one in the US working in parallel on different parts of the system. Besides that, there was an architecture team, that took care of the overall software design for new features and a testing team that performed integration tests once the code from different teams was merged. In addition there were experts in backend development (SAP ERP / CRM), DevOps specialists and UI experts who were not integrated in any team but built a team on their own. The team members in the Europe teams were (randomly) distributed between Germany, Poland, Spain, Ireland and Bulgaria. This was caused by the fact that Sys only had six internal employees involved while all other team members came from a third Party Vendor specialized in SAP Hybris development.
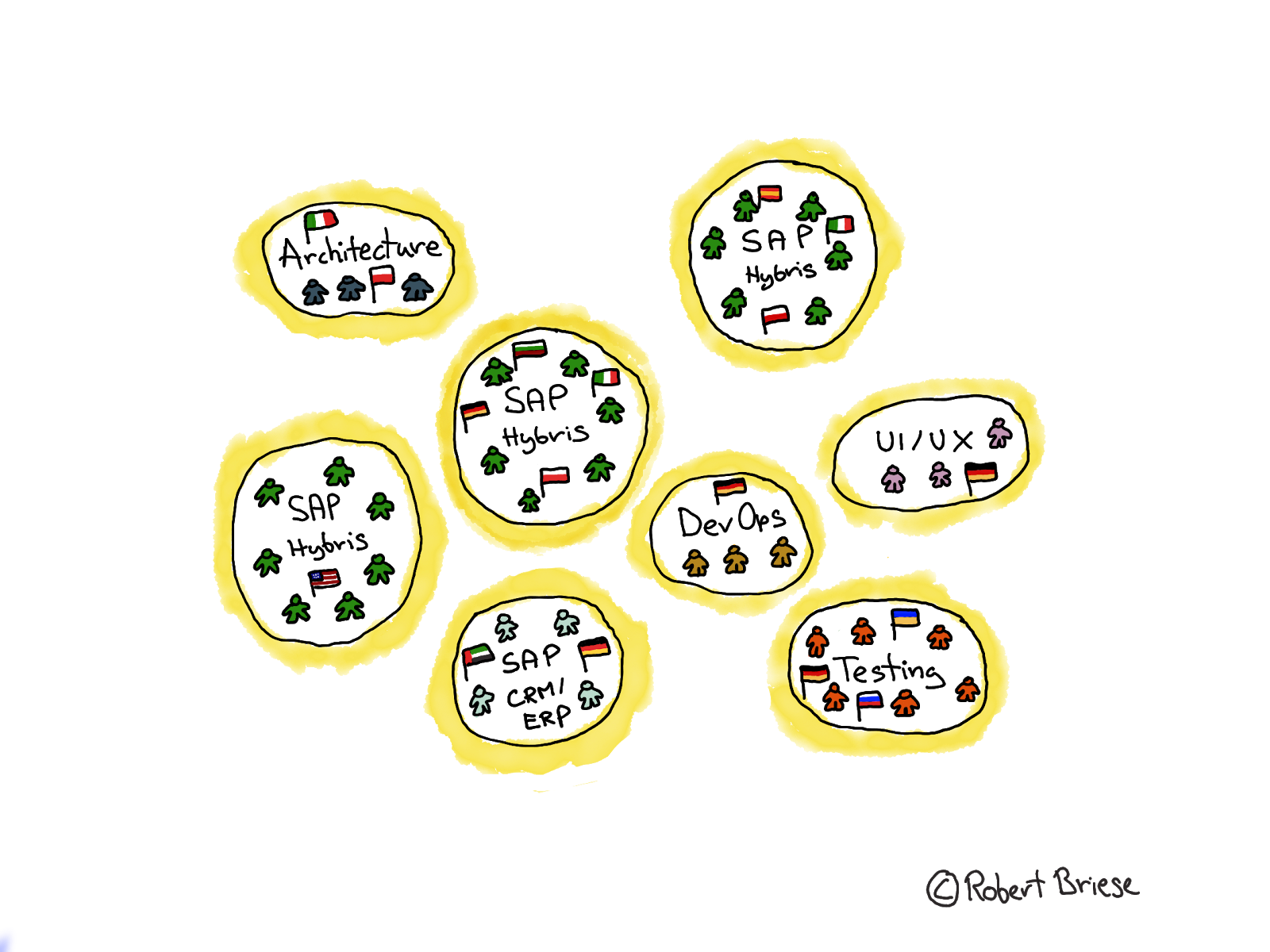
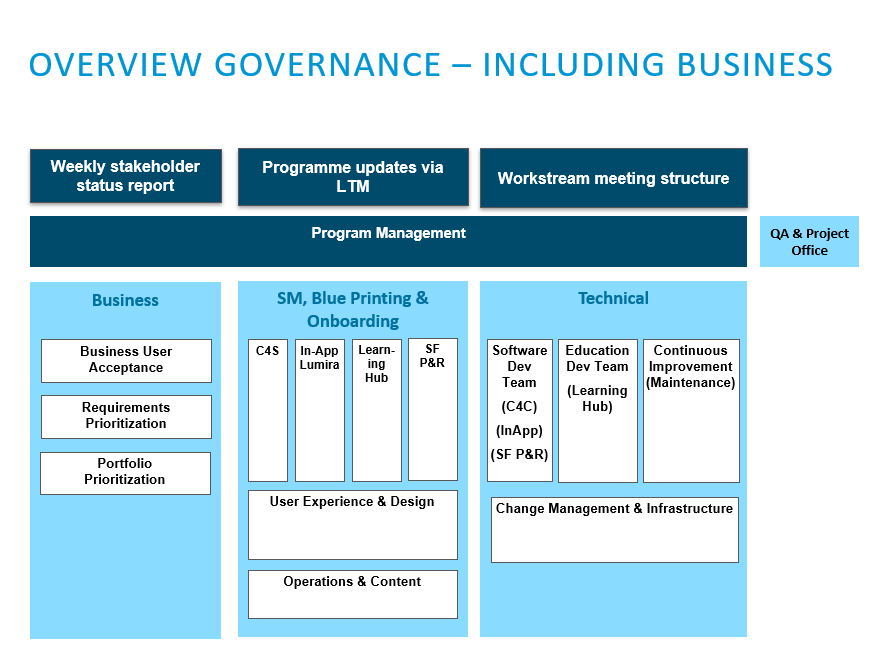
Besides the technical teams, there was also a huge organization on the business side to support the implementation and operation. On a first hierarchical level, managers lead a small team to prioritize features, write blueprints, perform user acceptance tests and onboard the features. On a second level, there was a team responsible for the overall portfolio and requirements prioritization and business user acceptance. On a third level, a program management consisting of three program managers, one from business (Sys Digital), one from Sys IT and one from Sys Education were in charge of the overall success of the project. In addition, a QA & Project (Management) Office was in place to support the program management. To keep track of progress on the development and business side, weekly workstream meetings, weekly stakeholder status reports and written program updates from the project office to the management team were established.
The Painful Deadline and the Need for Change
When I joined, at the end of February 2015, the platform was already accessible but had not yet been officially announced. The teams were in the process of preparing for the official release which had a fixed date: May 5th, 2015. A time when one of the companies biggest conferences, was being held in the United States, and when Sys’s Chief Digital Officer, was supposed to present the platform to the public. All the features that the teams were working on were mandatory for the official release, so the project office had a tight project plan that supported the feasibility of releasing everything on May 2nd. This plan included a development phase, IT testing, user acceptance tests, and regression tests—as we know from waterfall development.
The last couple of weeks in March and the whole month of April was a turbulent time. The timeline was slowly slipping away. When the teams that worked in parallel on different software enhancements merged their code into the main code repository, many of the features that had been tested before stopped working or behaved differently. Fixing new bugs constantly resulted in creating new ones and suddenly new burning requirements had to be fixed right away. On top, topics like security or load testing had to be tackled that had not been taken in consideration to that extend before. The management become anxious and everyone had to work long hours to get everything on track. For the last two weeks of April a “war room” was established, where all managers, team leads and architects worked in the same room from morning to evening to sort out any impediments and make sure everything is ready for the release. Finally, after many escalation meetings and hundreds of overtime hours the teams were able to release the new version of the platform on the first day of the conference.
There was no doubt at the management level, after this painful release, that the current way of development was not supporting the company’s ambitious goal to exponentially increase sales, try new business models and introduce totally different product offerings at a very fast pace. Scrum, with its focus on delivering the highest business value item first, and continuous attention to transparency, inspection and adaptation, all on the foundations of empirical process control theory, was a natural choice as an agile development framework. Adopting Scrum or LeSS though was preset to be extremely difficult, not only because of the hierarchical organizational setup and the dependence on technology experts in many distributed locations, but also because of the huge influence of the biggest marketing channels, namely the important conferences twice a year, that were creating two big non-moveable milestones.
Introducing change
With my background as a seasoned Agile and Scrum Coach with an affection for Large-Scale Scrum, I was asked to come up with a proposal on how the “Development department” could change its way of working to overcome the challenges it had faced. My challenge was therefore to (1) help everyone involved understand that in order to overcome the challenges experienced not only the Development department needs to change but the whole organization, and to (2) help the people involved own the ideas behind the change by understanding the why, instead of just following my advice and renting my ideas. In a meeting with the upper management (including Sys’s Chief Digital Officer), I presented a summary of the challenges that I gathered from conversations with business and development representatives. It included:
- Business Challenges (excerpted)
- Unclear priority of single features and product capabilities
- Apparently done work show bugs later in the process
- Technical Challenges (excerpted)
- Availability and infrastructure faults (performance, closed ports, etc.) block daily operations
- Entire deployment process takes too long. Often some parts (templates, post-processes, etc.) are missing
- “architects” are busy with manual tasks around the build process, code merge, and infrastructure setup/configuration
- The use of branches rather than trunk-based development, resulting in a high effort of code line merging, resulting in low code quality and many defects/bugs
- Setup of test data is a highly time-consuming process and is highly influenced by knowledge gaps
In preparation for the meeting, I also gathered the overall change goals as perceived by the management team. I summarized these items based upon one-on-one conversations and interviews with members of the management team:
- Optimize the system to faster delivery of customer value by waste removal
- Enable the organization to better understand the customer and respond more quickly to new requirements, and to learning and adapting from inadequate existing deliveries
- Improve the delivery code quality and reduce the number of defects/bugs
- Create visibility on the order of the customer-centric requirements with the focus on the whole product
- Increase visibility of what each team is working on
The second goal matches the overall system optimizing goal of LeSS, highest-level adaptiveness for learning and delivering most “value” to paying customers, while the others can be achieved with special attention to the LeSS principles (e.g. Queueing Theory and Lean Thinking for the first one), so I was happy when I noticed that not only the teams but also the management were in favor of using Scrum as a framework for developing software while staying close to the agile principles and values. I personally felt that in order to be successful we not only need motivated individuals that have a clear purpose and goal but also support from the highest organizational level to remove impediments and enable the change. This has been reflected in the LeSS Guide Three Adoption Principles (Top-down and bottom-up).
But I also noticed that there was no common understanding of Scrum and a workshop was needed to educate everyone and agree on some organizational change, which reflects the LeSS Guide: Getting Started.
I concluded my presentation in the management meeting with some prerequisites before starting the transition:
- Business and Development need to come to a shared agreement on a working model that will help achieve the above-mentioned goals
- We need (1) self-managing, (2) cross-functional, (3) co-located, and (4) long-lived team(s). (See LeSS Structure Rule)
- The teams need to be educated in Scrum and set up working agreement definitions and agree on a common Definition of Done
- A Product Backlog needs to be set-up, including technical items and business items
Management agreed with the above points and with a period of one month to perform the prerequisites needed for a transition to the new way of working.
Getting started
The following paragraph describes the steps we took to kick-start the adoption with the limited knowledge that we had at that time about such organizational changes. I’m making references to LeSS rules and guides when what we did matches with those and most importantly, I’m highlighting the things we should have done differently.
One of the first things that we did was to organize a workshop with representatives from the Development and Business Group for two days. This workshop, prepared by myself and a second coach, had a strong focus on teaching Scrum. This practice coincides with an adoption guide in LeSS: LeSS Guide: Getting Started 0. Educate Everyone.
At the end of the workshop, the participants understood that Scrum is not a practice or a definitive method but rather that organizational design changes are needed if they wanted to be agile rather than just “do agile”. The workshop also created a greater bonding between the Development Group and the Business Group.
Key learnings in retrospect for next time would be to include all senior management stakeholders (not just a few) in such a workshop. By having the senior management reflect on the organizational design implications of LeSS for example on group structures, hierarchy, site strategy, roles, processes, and policies, there would be not only support to change structure and policies through the adoption but you could also put the right structure in place from the beginning and save yourself a lot of pain—as we encountered during our adoption.
The second key learning would be to keep the focus on having the participants explore and understand the motivation, ideas, and organizational design change implications that Scrum and LeSS bring instead of focusing solely on teaching Scrum or LeSS. To focus on the Why, with the support of the LeSS principles (e.g. Systems Thinking, Lean Thinking) and let the participants derive their own working model from that. This would lead to greater engagement as the focus would be less on copying “best practices” or a methodology and instead understand the system optimization goal, how the current system dynamics meet (or don’t meet) that purpose at the moment and how the system can be changed to better meet it.
Define “Product”
As mentioned in the Guide: Getting Started 1. Define “Product” the product definition is “one of the most important decisions you make” because it determines the scope of the adoption, the content of the Product Backlog, and who is the most suitable Product Owner. In our case, the product definition was restrained through a product vision and existing structures. You can read more about the restraining forces that narrow a product definition in the LeSS Guide: What is Your Product?
The product vision was “to create a simple and connected digital experience for finding, trying, buying and consuming Sys software and partner solutions” and to “simplify the digital buying journey and experience for customers, to provide them with exactly what they want and need, when and where they need it”. The goal was to achieve this with one e-commerce product that was owned by the Sys Digital department and headed by Sys’s then CDO (Chief Digital Officer). The e-commerce site was to offer products from different Sys departments and also other companies. Ideally the product definition would be expanded over time (see LeSS Rule: The definition of product should be as broad and end-user / customer centric as is practical. Over time, the definition of product might increase. Broader definitions are preferred). To start however, a limited range of offerings provided us with a clear definition of the product.
One existing constraint that was hard to deal with was that Sys IT did not have any experienced SAP Hybris Commerce Suite developers. So they hired a company specialized in this product that provided developers who were distributed in different locations in Europe. This had, as we will see, a huge impact on the setup of teams.
Team setup
As a third step, we focused on the team setup and the first organizational change.
As mentioned before, we initially had a separation between teams working on specific components (such as SAP CRM backend or SAP Hybris Commerce) and single functional teams (such as the architecture team or the testing team). During the education part, we stressed that if we want to improve our ability to deliver the most important customer-centric features, we would need to create cross-functional, cross-component, stable and long-lived feature teams. This reflects the second LeSS Structure Rule and the reasoning behind it is explained as a summary in the LeSS Guide: Understanding Feature Teams and in detail in the first LeSS book: Scaling Lean & Agile Development: Thinking and Organizational Tools for Large-Scale Scrum. Two experiments from the second LeSS book also suggest this: Avoid… Single Functional Teams and Avoid… Component Teams.
The new teams were organized by grouping together specialists with different skills in feature teams. We ended up with four teams, each having three to four SAP Hybris developers, a SAP backend developer, an UI expert, two QA specialists and an architect specialized in continuous delivery. We eliminated the special testing team and the architecture team (by integrating these people into the feature teams) and created communities, where the experts would regularly meet and align the way of working. I will talk more about this in the section “Communities”. While we still had people with specialist titles (e.g. “Solution Architect” or ”Tester”), something that was unfortunately needed for contracting purposes, we made sure from the start that team members “would leave their titles at the door”, learn the needed skills and help each other to create one integrated product increment at the end of each Sprint.
We started with a dedicated Scrum Master for each team, because most Scrum Masters and teams had yet no experiences with LeSS. In an effort to lead by example I took on the Scrum Master role for one of the teams. Through my teaching and coaching a former project manager was able to fill out the role of the Scrum Master and he took over my team after three months.
For the first year, a Scrum Master supported only one team; later some Scrum Masters also supported two teams. Their focus moved from helping the teams improve their way of working to surfacing organizational dysfunctions that hold the teams back from increasing their performance. This reflects the LeSS Guide: Scrum Master Focus.
System operations
The Sys IT department had a long history of projects implementations, where a system was built over a couple of months or years, but where at some point, the budget wasn’t extended and any further investment was only to continue operations and maintain the system by allocating an offshore group. In the past, this lead to introducing a “hand-over” phase shortly before the “implementation budget” ran out. This involved knowledge transfer sessions to the offshore group. This “hand-over” phase was always a painful situation where the focus was mostly on the creation of “just-enough” documentation for the maintenance team and this led to the system deteriorating, as the maintenance team didn’t have enough understanding of the initial reasons behind each feature and were also usually budgeted to add small features but not to improve the system.
We managed to tackle this topic during the “education workshop” and secured some of the “maintenance budget” to integrate offshore developers into the feature teams from the beginning. They had little knowledge about the SAP Hybris Commerce system or the SAP backend systems initially, but with pair- and mob-programming they gradually moved from “just fixing bugs” to implementing new parts of the system. This had a tremendous impact on the system’s code quality, because the team members were paying special attention to technical debt and to the fact that the necessary documentation grew together with the system, as they were the ones that would remain in charge when the “implementation budget” ran out, so they were usually the ones to remind the other team members about system quality topics.
Open organizational challenges at the start
After the initial setup of the teams, two challenges remained unaddressed: dispersed teams, and the integration of business people. Although this led to bigger problems initially, they were addressed at a later point in time.
The first challenge was our dispersed teams. As mentioned before, the Development department had no access to internal SAP Hybris developers to allocate to the project, so they were totally dependent on an external company to provide developers with SAP Hybris knowledge. This company had all their developers dispersed across Europe, many of them working from home offices. Investing money to temporarily move all team members to one location for a longer period of time was unthinkable at the time, so we proposed a 2-week kick-off and an onsite event every six months. The difference made in having people work together in the same location was so powerful that it didn’t remain unnoticed for long. Changes to the teams’ setup were performed to improve the situation dramatically. After less than one year the teams were reorganized to allow having most of the team members in one location.
The new organizational setup now changed as indicated in Figure 6.
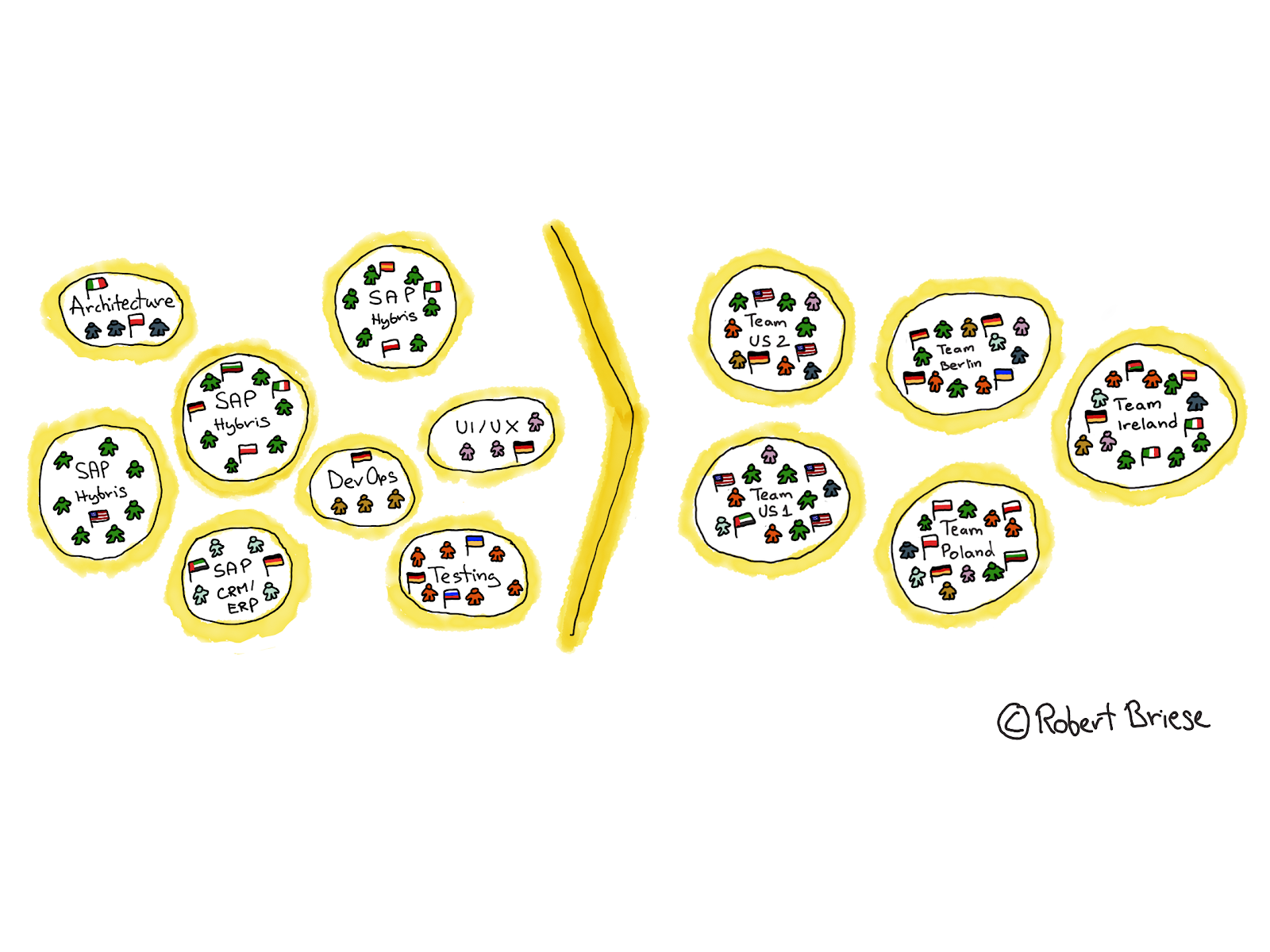
The second big challenge was the integration of business people. As mentioned earlier, next to real product managers doing market research or partner management, the organization consisted of many intermediaries in between the real developers and real business people, that were busy with traditional waterfall tasks, like identifying what should be developed next, writing blueprints and performing end-user tests. Also, the development department was used to working in Scrum with their own (fake) Product Owner who was actually just a middleman project manager. In the past, this person functioned as an interface for the teams towards the business. There was usually a fake middleman “Product Owner” business analyst on the development side focused on writing requirements and following up on clarifications from the development team and a fake “Product Owner” project manager in a layer between the real business people and the developers, who was the single point of contact for each development team to the real business organization. While we addressed this topic in the “education workshop”, it was clear that there were management constraints and lack of management support to change the setup directly from the start. But as we will see in the section “One Product Owner”, this situation led to many dysfunctions, and after about eight months we changed the setup to have only one Product Owner in charge of the whole product with support from other product managers.
Kick-off
Two weeks after the “education workshop” with development and business representatives, we organized a larger workshop to include all team members for the initial kick-off. Within a 2-week span, all team members had a chance to get to know each other, discuss, reflect and agree on the way they wanted to work together.
The workshop included a couple of days training of Scrum (this time for all team members), the creation of the initial Definition of Done (DoD), establishing team and overall working agreements, and most of all helping the teams to gel.
One important part for me as a coach and for the team of Scrum Masters was to get the teams from the “Forming” stage towards the “Norming” and “Performing” stage as quickly as possible. This is of course not achievable in two weeks, but understanding the dynamics of team development, we knew that our main focus for the two weeks was to establish a common goal as well as trust between the team members. We had great success here with running many team-building activities.
Definition of Done
During the two “Kick-Off” weeks, where all teams were onsite, we performed a workshop for defining the initial Definition of Done for all teams, as described in the LeSS Guide: Creating the Definition of Done. In this workshop, we explored with all team members what activities are required to ship the product (Potentially Shippable Product Increment) and separated the activities that, at that time, could be performed by the all teams during the regular Sprint from all other activities necessary for the production release. This was also the first time we had deep discussions about the different types of testing and documentation, and we managed to get a shared understanding on how we wanted to work.

The items underlined in Figure 7 are the items that participants agreed to include in the initial Definition of Done. All other items are Undone Work, so items that are not part of the Definition of Done but have to be fulfilled to ship the product. We started with a long list of Undone Work, understanding that our perfection goal was to eventually include all items from Undone Work in the Definition of Done. I’ll explain later in the “Release Sprint” section how we dealt with Undone Work. Over time, we expanded this initial Definition of Done through agreements in Overall Retrospectives.
One Product Backlog
One factor that was important for us to start with was to have one Product Backlog from the beginning. This is in line with the LeSS Rule: There is one Product Backlog for the whole shippable product.
This was quite challenging at the beginning because of the organizational structure and the responsibilities that the different product managers on the business side had. Different product managers were responsible for launching different Sys products on the e-commerce site and this created a conflict of prioritization. In the past, each team had their own so-called “Product Backlog” and a fake “Product Owner” project manager in a layer between the real business people and the developers who was in charge of ordering the items in the teams’ backlog. This led to local optimization because every team “Product Owner” was focused on delivering parts of the product, but without a whole-product focus. What happened is that every team “Product Owner” pushed for more of their features while each expected that “the other teams” would improve the product and the delivery process, which of course did not happen.
Our goal was to create visibility on all the items that were truly globally important (because they were planned for a milestone) including the technical items. One approach we tried was to introduce User Story Mapping. The idea was to get a visualization of all the important items on the roadmap and structure them so that it was possible to have a discussion and prioritize items together as a group. Usually a couple of days after the Product Backlog Refinements and a couple of days before the Sprint Planning—so once every two weeks—the product manager group (including the fake POs) spent around two hours to present and discuss the outcome of the different refinement sessions and to agree on the scope that should be presented in the next Sprint Planning Meeting. The advantage of this approach was that it created visibility on all the items that the business wanted to implement for the next milestone, and with the estimates that the teams created during the PBRs, also visibility on how likely it was to be able to implement everything in one Sprint. The challenge with the approach was that it led to many heated discussions, as each product manager had some “personal goals” to achieve and it was almost impossible to come to an agreement because of that. After some time this led to a change regarding who was in charge of the prioritization of the items in the backlog.
One Product Owner
As I mentioned above, we started with a fake middleman “Product Owner” business analyst on the development side and a fake “Product Owner” project manager in a layer between the real business people and the developers per team, and I will share here some background on why that was the case. When starting to adopt (one-team) Scrum as a software development framework in early 2011, project managers from the Sys IT organization were asked – due to not understanding Scrum and what a real Scrum Master or Product Owner is – to choose if they wanted to develop themselves as so-called “Scrum Masters” or so-called “Product Owners” in order to fit the terminology of the new working model, but of course without actually changing much (See Larman’s Laws of Organizational Behavior #1 and #2). Some former project managers chose to become “Scrum Masters” and others “Product Owners”. This turned out to be a huge challenge for most of the former project managers. The difficult part turned out to be not the learning of unknown skills (such as personal and team coaching) but more the unlearning of beliefs and behavioral patterns when working with software development teams (such as how to behave when self-organization does not occur). This led to the fact that in our teams, only one previous project manager remained as Scrum Master (and this person become a servant leader incredibly fast). And because the labels changed but the structures and policies did not, there was no real owner of the product that became the real Product Owner, but just a re-badging of project managers into fake “Product Owners.”
The extraordinary setup, based on not understanding or adopting Scrum as intended, of having two fake Product Owners in every team felt very good at the beginning because the development team had the false feeling that the business was now close to development and there was an illusion of an “efficient channel” of getting customer wishes to the development team. But this led to two major problems. First, having team “POs” in charge of the team “Product Backlog” led to local optimization as mentioned above. Second, the team “POs” (business analysts) became the bottleneck and intermediary for teams to understand requirements. This created many wastes, including handoff problems, delay, over-processing, WIP, and defects, by having the fake PO writing the specifications and handing them to the team to “implement”.
By introducing a single Product Backlog for the whole product, and by discussing it regularly (every Sprint) we made sure that the team “PO”-project managers could change the order of some items but that someone else could overrule the order of all items that the teams would work on. Sometimes the order defined by the team “POs” was meaningless because the team ended up working on other items that were more important for the overall product focus. Finally at some point, only one person very close to the CDO was in charge of the ordering of all items refined by the teams, and all other members of the project management department spent less and less time dealing with the prioritization.
Dealing with the second problem (team POs as information bottlenecks) was much more difficult, mostly because of company constraints. The fact that team members were uncomfortable doing clarification work with customers or were lacking the skills to do so, or that there was the belief that it is more (locally) “efficient” if one person does the clarification work while others focus on development, or that the team of fake POs (project managers and business analysts) have a different status and salary—all of these things made it a huge challenge.
Technical excellence
Technical excellence was a very important part of our adoption. As mentioned in the “Introducing Change” section, our success was measured by how well we could reduce the number of bugs as well as by how fast we could release new features and by that deliver customer value or at least learn and better understand the customer and change direction. Introducing and continuously improving the following agile engineering practices is what allowed us to make huge improvements in both of those goals.
Baby Steps Towards Continuous Integrations & Delivery
Moving from a situation where each team worked on a separate branch for a couple of weeks or even months until it was merged with the master branch to continuous integration was, in our case, a very long process with many coaching sessions, conversations and/or meetings, and discussions. Of course, it was not arguable that the initial way of working introduced too many problems such as breaking the system, introducing bugs that had been fixed before, and wasting a lot of time on things that were not related to new improvements but rather maintenance and stabilizing the system. See: Avoid… Large batches of changes. So there was a high acceptance on the developer side to move away from big releases. Unfortunately, there was not enough knowledge on how to do that. What helped in our case was to connect with other people in the IT department who had good knowledge of continuous integration and continuous delivery as these people had previously been involved in building an internal cloud system at Sys for automating the deployments of all Sys IT systems.
Each team was joined by a build expert who was focused mainly on two things: to build (together with his other peers) the continuous delivery pipeline and to teach other team members how to automate every system change and to put everything in the version control system (in our case Github). But continuous integration is not about having everything in version control and an automated build; continuous integration is a development practice. See: Avoid… Believing CI is a tool. It requires commitment and discipline from the team to check in small incremental changes frequently to mainline and agree that the highest priority task is to fix any change that breaks the application. So as coaches we were focused on introducing and living this mindset, and on continuously addressing opportunities to improve the following things:
- Decrease mainline code checking intervals
- Increase the comprehensiveness of the automated test suite
- Decrease the time it takes to run the build on the server
- Decrease the time it takes for each developer to execute tests on their development workplace
Working with developers that were used to managing the complexity of component teams and sequential life-cycles only through branching, and who could not imagine working with other inexperienced colleagues on the mainline, it was considered impossible to move away from branches right away. What we did then was to challenge the duration of branches. The teams started to work with only two types of branches: a long-lived release branch and “short-lived” feature branches. It took quite some time to reduce the duration of the feature branches, starting with periods longer than a Sprint (if the feature was not included in the product increment) to a couple of hours. Two things helped us here tremendously. One was the continuous discussions about the disadvantages of branching and showing alternatives such as hiding new functionality or doing changes incrementally. The other was to make the “living time” of branches transparent. The developers introduced a code review process whenever a small feature increment was developed in a feature branch, in order to merge this branch to the mainline and delete the branch, another developer had to review the changes in the branch and do the merging. Usually, a developer discussed this step with the other team members when starting to work on a new feature increment over our main communication tool (Slack) and also requested a code review once the change was implemented and tested on the developer’s machine. While this has a big disadvantage from a lean product development perspective, as it increases the cost of delay and introduces hand-over, this approach at least was in the direction of improving, and increased the visibility of branch duration as well as the helping atmosphere within the teams.
When I left the average living time of a branch was one day (with many branches living only for a couple of hours), which is far from optimal, but a huge improvement to how everyone worked before.
Automated Testing
Without automated tests, a passing build only means that the application could be compiled and assembled. So developing a comprehensive automated test suite including unit tests and acceptance tests is crucial for providing the fast feedback that is the core outcome of continuous integration. See Try… Unit testing. Try… Acceptance test-driven development.
Having an experienced team member with knowledge and passion about testing in one of the teams, who understood that testing in agile software development is about test independence in spirit without separating testing from development, helped us tremendously. The best way to achieve this test independence in spirit is to define the tests before the implementation, and this can be best achieved through discussing and clarifying the testing requirements in workshops attended by the cross-functional team, the Product Owner or representative, and any other stakeholder who potentially has information about the requirements. See Try… Requirements workshops. I will discuss the flow of our requirements workshops under Product Backlog Refinement in “The LeSS Events” section.
In the beginning, we started creating the test automation suite by having test specialists with coding experience automate the scripts for manual testing as (Selenium) UI tests. After some time people realized that this wasn’t such a great idea, because even though there now was some feedback after each build, the feedback was very slow and the tests extremely brittle, requiring a high maintenance effort. See Avoid… Test through the UI. We constantly had issues with the tests because some UI or some functionality was changed, and because team members needed to constantly check if the new behavior was the desired behavior or not. But that was not our biggest problem. The critical lesson that we learned here was that by having a group of team members responsible for the automation of the tests and another for implementing new functionality was a recipe for disaster - it caused additional complexity, the wastes of handoff, and knowledge scatter. See Avoid… Separate test automation team. We addressed this separation of single specialized team members and introduced working in pairs, so that team members with testing as primary specialization gradually broaden their knowledge on coding and team members with coding as primary specialization started writing automated tests. This allowed us to make a shift of testing less through the UI and more through the API, while also improving code coverage.
Another important factor for us in order to reduce one of the initial key pain points — the high amount of defects — besides the test automation was to introduce a stop-and-fix rule. See Try… all tests pass - stop and fix. We connected our build pipeline with our messaging tool (Slack), so that every time a branch was merged with the mainline, a build started and at the end of the build, a test notification was sent to the “General” Slack channel. If an automated test from the suite failed, the information about this test was published together with the information about the merge that triggered the build. It soon became part of our team’s culture to immediately react to this message by volunteering to fix the issue, most of the time by the person who felt responsible for introducing the tests that failed.
One other behavior that the teams adopted was to first write a new acceptance test for each newly identified bug before implementing a fix. With that, our automated test suite grew, and with that our confidence that the product increment created with every build was releasable. After one year we had more than 1000 tests in the automated test suite and the regression testing time before a release was reduced from weeks to only a couple of hours.
Another positive impact to writing (or updating) acceptance tests first before fixing a bug, or implementing a feature, was that we replaced the often outdated and fragmented documentation in Wiki or Jira with a living documentation as described in Specification by Example. The acceptance tests become executable specifications and then a living documentation that was always up-to-date, saved and updated with the code in the same repository.
Communities
Having people that are extremely passionate about an important topic in LeSS can have a huge impact on the adoption. Natascha, our most experienced person in testing, is a huge fan of Specification by Example and she saw it as her mission to bring the focus of the teams towards test validation and designing tests, and away from test execution. On top of that, she refused to become something like a QA lead because she didn’t see the point in becoming the bottleneck of testing. Therefore, she did what she could to cultivate the understanding of effective testing in the teams and distribute her knowledge. In order to effectively do that, she created regular meetings where team members with the main focus on quality assurance and exploratory testing participated (and everyone else was invited to join too), and where testing topics were discussed. Outcome of those meetings were often a shared understanding about, for example, how to create specifications using the Gherkin language, or how to focus the specification on what to test and not how to test, which was then documented in the wiki to share with other team members. Another great thing she did was to distribute books about testing to community members. More and more people became passionate about this “new way of” testing and started to inject this passion into the teams. Such practices are also reflected in the LeSS Guide: Community Work
Besides the Testing Community, we had a Scrum Master Community and an Architecture Community.
The Scrum Master Community was a great chance for the Scrum Masters to align, to learn from each other but also to share and ease their frustration during the adoption. Like the other two communities there was a special Slack channel for this group, but it was also a very small group of only three Scrum Masters and one coach, later growing to five SMs. Having such a small group, it allowed us to become pretty bonded with each other, a team in its own. We had a short sync daily, after all teams’ Daily Scrum, but it had nothing to do with a Scrum of Scrum meeting. We didn’t talk about which team progress but rather about new impediments mentioned during Daily Scrum, aligned on the next LeSS events and who is facilitating them. Most of the time we shared observations and amplified our learning. We often exchanged Scrum literature with each other and had sessions where we discussed it. Especially in the beginning, when the new Scrum Masters started, I paired a lot with them, first facilitating the meetings myself and discussing them afterwards, later letting them facilitate the meetings and reflect the observations subsequently. Even after the Scrum Masters become more experienced we continued pair-coaching in regular coaching conversations meetings with team members. These were an experiment that the Scrum Masters started in order to create a trusting relationship between team members and Scrum Masters, to allow the Scrum Master a better understanding of each person in the team, and help them to cope with the new way of working. This 1-hour conversation every two Sprints turned out to be valuable considering the distribution of the teams, not only for the team members but also for the Scrum Masters.
The community that was put in place last was the Architecture Community.
Design/Architecture Community in LeSS is a strongly recommended community so it was quite strange that this was put in place only after more than half a year. But considering the understanding of architecture in the organisation at that time, it feels very predictable to me now that people miss to see the need for this community in the first place.
For a department that is used to waterfall development and offshore/nearshore the maintenance of existing systems to “cheaper” developers, there was this understanding that software can be “architected” by experienced architects and later implemented as designed by “regular” developers. One critical mindset change that we adopted in our teams is the understanding that “agile architecture comes from the behavior of agile architecting—hands-on master programmer architects, a culture of excellence in code, an emphasis on pair-programming, coaching for high-quality code/design, agile modeling design workshops, test-driven development and refactoring, and other hands-on-the-code behaviors”. See LeSS Experiment: Try… Think ‘gardening’ over ‘architecting’ - Create a culture of living, growing design.
This was a very long process, that started with many discussions with the managers responsible for the system maintenance, a completely different department in the organization. While visualizing the system dynamics that occur when experienced architects hand-over designs to developers to implement (See LeSS Experiment: Avoid… Architects hand off to ‘coders’) we convinced them to integrate the nearshore developers in the teams. They started doing bug-fixes first, but were integrated into all the teams’ meetings, taking part in pair-programming sessions and with the code review process in place, were encouraged to take over any type of implementation, regardless of it being a new or existing functionality. That was indeed a huge shift from having clear responsibilities of who is responsible for what, to the whole team(s) being responsible for the quality and design of the product. Besides regular pair-programming sessions that were scheduled on demand, and the mentioned code review process, a key factor that helped each developer to get a better understanding of the system architecture were the speculative design workshops that were held in each Sprint Planning meeting. I will describe the way we did them in the “LeSS Sprint Planning Meeting” section below.
Once the understanding was there, that real software architecture evolved with every act of programming; there was suddenly a need for a different architectural integrity approach in place than the prior creation of designs documents before every implementation. The most senior developers from each team wanted to get together regularly and share the speculative designs created in the design workshops and the architectural patterns used (See LeSS Experiment: Try… Architectural and design patterns). With time, some additional meetings emerged, that were not part of the LeSS events but could be seen as architecture community meetings. An “Architectural Alignment” meeting was scheduled a couple of days after each Product Backlog Refinement that allowed the senior developers to explore and discuss large-scale architectural implications of the new requirements. This turned out to help tremendously for the planning of the next Sprint. Another meeting we called “Solution Design Alignment” was scheduled the next day after the Sprint Planning meeting and was primarily used to align the outcomes of the speculative designs from the individual teams’ Sprint Planning Meeting Part 2. I believe that if we would have all been in one location and done joint design workshops (See LeSS Experiment: Try… Joint design workshops for broader design issues) when needed, the meetings wouldn’t have been necessary at all. However, with the difficulties of having effective meetings as one disperse team let alone multiple teams, those meetings were seen as very valuable as additional meetings.
Communities in LeSS not only put in place a support system for learning and knowledge sharing but also provide an ideal environment for decision making in an organization where managers don’t impede the agility of decision making (by becoming bottlenecks) and decisions are made by the domain experts (no matter in which team they are). LeSS suggests that communities agree on how they work and make decisions (See LeSS Guide: Communities). In our three communities I was astounded to see how great they worked in this aspect without a formal decision making protocol. I am convinced that this was related to the fact that the team members participating in the communities established a high level of trust and respect to and for each other very early on. In such environments it is easy for communities to make decisions based on everyone’s consent. (Consent means that no one would be opposed to the idea, in contrast to consensus, where everyone supports the same idea, which, even in such environments, is not more likely to happen).
The LeSS events
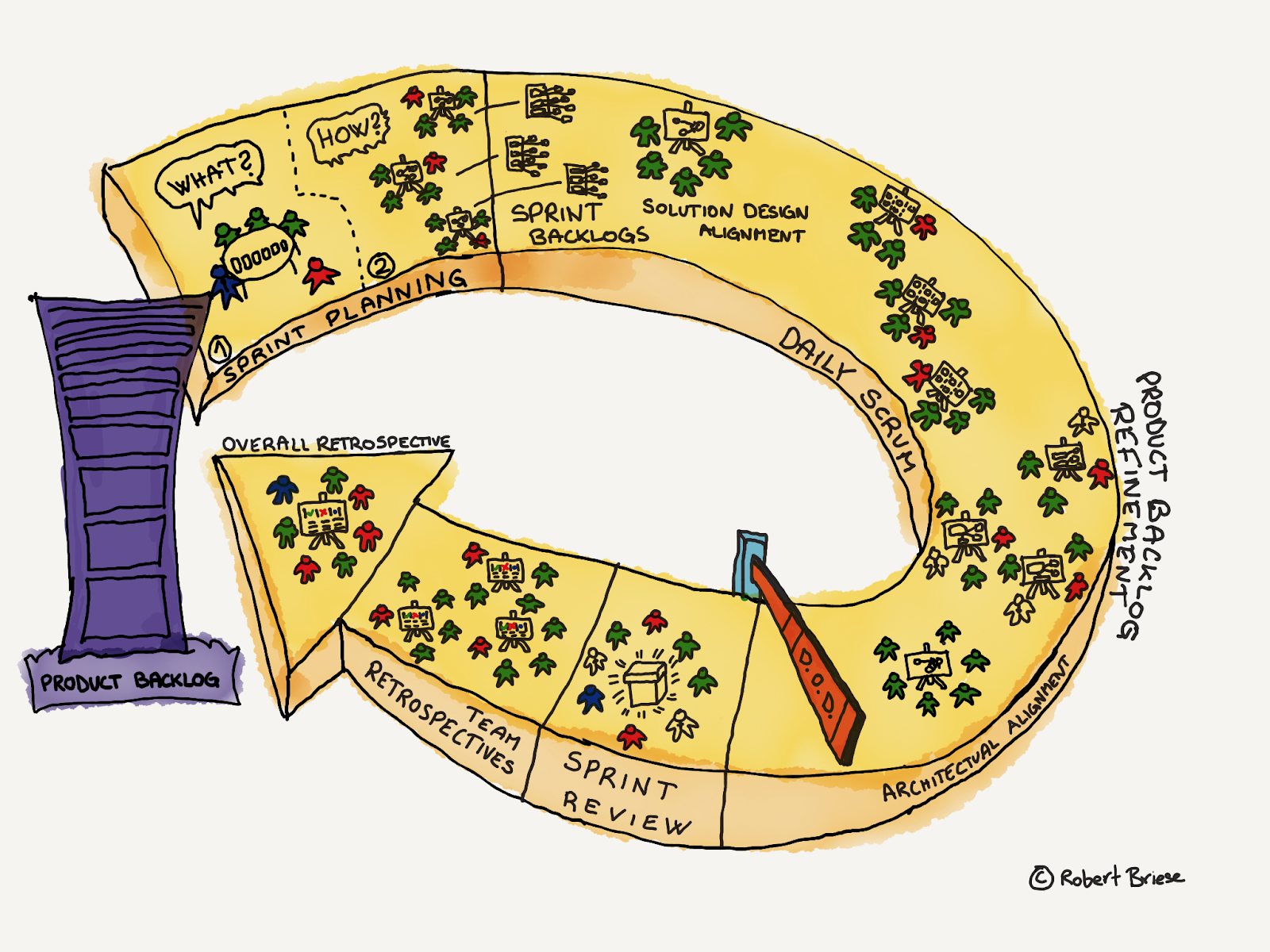
Our LeSS Sprint ceremonies
We established all LeSS events from the beginning but, as you will see, because of the fact that we had such dispersed teams, it proved extremely difficult for us to enable the critical transparency and inspection that those events were designed for.
We started with bi-weekly Sprints for all teams: one Sprint for all teams starting and ending at the same time (See LeSS Rule: One Product-level Sprint).
LeSS Sprint Planning Meeting
Like most of the LeSS events for us, Sprint Planning Meeting was quite challenging due to our remote participants. In the beginning, all team members joined the Sprint Planning Meeting One, which usually didn’t take more than 30 minutes. However, with a growing number of teams, only team representatives joined. See LeSS Guide: Sprint Planning One. As I mentioned in the “One Product Backlog” chapter, we always had a “Business Alignment” meeting prior to the Sprint Planning meeting, where business representatives, the “Business POs”, and stakeholders discussed and aligned the outcome of the Product Backlog Refinement sessions. Ultimately, the (later) Product Owner decided the order of all items and this was the list that was presented in the Sprint Planning One by him or a representative. Usually, this went pretty fast, as most of the time teams were volunteering for the items that they had refined, but in some cases, when those items were not on top of the list, and if other teams had no capacity, teams would also pick unfamiliar items. In such cases, team representatives explored the opportunity for cross-team collaboration in Sprint Planning Meeting Two and during the Sprint. They would do have a Multi-Team Sprint Planning Meeting Two where the teams would have a shared design session and coordinate shared work.
Because of the dispersed teams, Sprint Planning Meeting Two also had to be done via a conference call, which was even tougher. After the restructuring of the teams, the situation improved here tremendously, having most of the team members sitting in one room in front of a whiteboard and only a few participants joining remotely. The teams had experimented with many different approaches over time, such as how to improve Sprint Planning Meeting Two, and in the end, I observed that each team had a different favorite approach of running the meeting. Some teams preferred to split into groups of two to three people and break down each PBI into tasks. Afterwards, they got together and presented all tasks, followed by a reestimation by the whole team to check if the sum of all items still fit in one Sprint. Other teams would go each PBI one by one and identify together the tasks to be done, while also estimating those in hours, working their way down until they are “full”. While each team had their own approach of running this meeting—which is encouraged in LeSS, as teams should own their processes instead of renting them—they all focused on getting a really good understanding of the agreed Sprint Backlog as a team. No matter what approached was used, we realized as Scrum Master and Coaches, how critical it was for teams to feel confident with their “forecast” and always leave some buffer for unforeseen work. We noticed a powerful, positive influence when teams took less work into the Sprint than they initially forecasted, which resulted in an increase in motivation and performance.
Product Backlog Refinement
I am convinced that the Product Backlog Refinement is the LeSS event that changed the most over the course of the adoption. In the beginning, we (incorrectly) scheduled 2-hour sessions every two weeks, that were joined only by team members and the “Business PO”. The business analyst (called IT “Product Owner”) prepared the PBIs with the “Business PO” in advance. Each item was then presented in the PBR and the main focus of the team was on asking clarifying questions and estimating the size of the items.
All teams had not one but many left-overs in each Sprint, and it was often discussed in Team Retrospectives that one of the main root causes for this was the used refinement approach. We introduced a fixed structure for PBIs—a user story and epics template including business value and user success scenarios, assumptions, acceptance tests, and open questions—following suggestions made by a consulting coach. A Definition of Ready (DoR) was also introduced to make sure no incomplete items were presented in the Sprint Planning Meeting. In addition, the business analyst agreed to write down the acceptance tests as examples in Gherkin syntax (Given… When… Then… ). Still, this didn’t improve the situation much. Many PBIs or user stories were not completed by the end of the Sprint because they were not fully understood. We also had many so-called “boomerangs” (a PBI that comes back into the process within less than two months after it was released). With time, people started realizing that no matter how good the template was filled in advance, the real understanding about the item was best acquired through discussion and reflection while writing things down. Not only that, but we also noticed that we could design better solutions as a team, than the business analyst could alone together with the business; an opportunity to have everyone understand the real problem and collaborate on the solution. In light of this, we gradually moved from discussing technical feature specifications and estimating the work in the Product Backlog Refinement to discussing the goal or the problem that the business is trying to solve, collaborating on defining the scope that could help achieve the goal in one Sprint or help us move towards the goal and determine potential solutions. The business analyst was still in charge of running through the PBR session, but with time, we integrated more and more opportunities for team members to collaborate on scope definition and solution design, instead of just asking questions to the key example identified beforehand. One approach that helped here was to have breakout sessions after the business analyst presented one clear example (the “happy path”) so that team members in groups would look for boundaries and try to come up with other examples. Ideally the groups were people sitting in the same location, but in some situations, we had people writing in an online tool (e.g. wiki page) together over a video conference call. Afterwards, we would review the different examples and agree on key examples that would be later used for automation together.
With this shift and different approach, we also realized that the business analyst and the “Business PO” didn’t have all the answers to the questions that came up during the discussion so we started to invite experts from the business to these sessions.
It is important to remember that the entire model of having these fake “POs” was a mistake, but was both forced on us, and a reflection of our many misunderstandings of Scrum and LeSS.
The LeSS Sprint Review
As prescribed in LeSS we setup one product Sprint Review for all teams. Due to our organizational constraints of dispersed teams and multiple locations, we performed this event via video conferencing, so that all team members and business representatives from all locations could join. As coaches and Scrum Masters we were excited about having only one common Sprint Review for all teams, in order to establish the whole product focus for all participants. Practicing continuous integration, the teams let their stakeholders review their done items during the Sprint to get as fast as possible feedback. Therefore most of the PBIs have been reviewed by the Product Owner and business representatives during the Sprint. In the Sprint Review we focused on the overall product overview having discussions on what was achieved and what we missed. Unfortunately, due to the mentioned organizational constraints, our Sprint Review had less of a hands-on inspection character.
In LeSS, like in Scrum, the Sprint Review is about a hands-on inspection of the product and an in-depth conversation between the Team, the Product Owner and Stakeholders to learn together about the product, the profit drivers, the strategic customers, business risks, new problems and opportunities, and so forth. An important area of improvement here, when I left, was to find ways to allow stakeholders, Product Owner, and team members to interact with the running software and inspect the new product in a multi-site environment, for example in the form of a multi-site Review Bazar as well as allow for discussions about the learnings from the inspection and the directions of the next Sprint.
The LeSS Retrospectives
The other impactful opportunity to improve was by making use of an Overall Retrospective as described in the third LeSS book: See LeSS Guide: Improve the System. For a long time, there were only Team Retrospectives at the end of each Sprint as no one could see any value in an additional meeting. But with time people realized that systemic issues can only be addressed when everyone from every team buys in. Things like improving code quality or better involvement of business had a different impact if all teams worked on them together. At first, the Scrum Masters had a sync meeting after all Team Retrospectives to align the improvement experiments that the different teams had committed to, but with time they realized that they couldn’t necessarily convince their team members to apply experiments that other teams had decided, and they struggled with this for some time. Finally, we introduced the “Overall Retrospective” where team members from all teams would participate, and sometime (but unfortunately not always) managers would join. Many important improvements have been discussed and addressed in the “Overall Retrospective”, like the improvements of the Product Backlog Refinements with the introduction of Specification by Example. Also the lack of architectural integrity was addressed in an Overall Retrospective and the Design/Architecture Community was coined with the “Solution Design Alignment” and “Architectural Alignment” as a support to get joined design alignments. In order to address system wide issues there is a need to look at the whole and discuss system dynamics and mental models as a group together with the management, a step we started but were still far on establishing as a standard in the Overall Retrospectives.
Release Sprint
As we didn’t have a separate “Undone Department”, all the work that was not part of the Definition of Done (DoD) had to be performed by the development teams before a release. At the beginning we released to production every two months, so every fourth sprint was a Release Sprint, where almost all work done in the Sprint was related to Undone Work. This is in accordance to the LeSS Experiment: Try… Include Scrum teams in a Release Sprint. But of course the goal is to reduce the Undone Work and improve the DoD so that there is no need for a Release Sprint anymore. When I left, the Undone Work was reduced to occupy only one full team during the Release Sprint, and each release a new team took over the work, while all other teams were working mostly on removing technical debt.
Conclusion
This story shows that applying LeSS principles, rules, guidelines, and experiments improved the way of working and formed a more adaptive organization at Sys IT, which led to a successful implementation of the Sys Store, even under some organizational constraints that prevented to adopt LeSS as recommended. As mentioned in the opening chapter, it is not about how to introduce LeSS properly. By (1) introducing LeSS rules that eliminate the anti-adaptive elements when many teams are creating a product and (2) gradually changing the organization by removing structure and policies, we were able to achieve major improvements in adaptability. This was supported and guided by continuous reflection about system dynamics and the management support to make the necessary changes for continuous improvements towards the system optimizing goal of adaptiveness at a low switching cost.
Applying the LeSS organizational design system rules, such as implementing one Product Backlog, one Product Owner and a shared Sprint Planning Meeting for all teams helped to keep whole product focus and also to create visibility over what the teams were working on while supporting self-organization and intrinsic motivation. The shared review meeting was extremely challenging with five dispersed teams and many stakeholders in different locations, but it helped to keep the focus on the whole product even though it lacked the in-deep conversation and alignment a real Sprint Review meetings brings. The Overall Retrospectives allowed us to address bigger organizational changes that at team level wouldn’t have gotten as much attention. On top of the LeSS events, the adoption of many of the LeSS recommended guides and experiments is what had a huge positive impact on the software development effort.
Establishing rules such as “stop & fix”, making them our culture, in my opinion, had the greatest impact on our ability to deliver a better product with fewer bugs in a shorter time-frames. The basis for that, of this I am convinced, is building up the technical excellence (like test automation, continuous integration, etc.) without which it is not possible to make changes to the product in an easy, fast, and flexible way and get fast feedback. Without this, “stop & fix” is not possible.
There were three critical organizational aspects that enabled a cultural shift during my time on board: removing structural barriers and hierarchies, eliminating roles within the teams (all team members worked together to create one integrated product increment at the end of the Sprint) and abandoning any special meetings for “special groups of people” which brought everyone closer together and closer to the goal of delivering a quality product at the end of each iteration. Removing policies and meetings and focusing on the overall product and the overall system is the main factor that allowed us to change the culture. See LeSS Guide: Culture Follows Structure. The other two factors that helped here in my opinion were Communities and Coaching (Conversations).
My biggest learning in retrospect is regarding the way to perform a LeSS adoption. Our gradual approach to introduce the LeSS structure was forced through our organizational constraints and we were lucky to have achieved the above-mentioned improvements and not create more problems. In most cases having the wrong structure at the start reinforces the dynamics described in Larman’s Law of Organizational Behaviors mentioned through the case study. By (1) educating everyone at the beginning of the adoption on the why, (2) putting the organizational design in place from the start as expected, and (3) having strong alignment, agreement, and united support from a senior management team that deeply understands organizational implications of LeSS and don’t follow Larman’s Law of Organizational Behaviors, we could have made more progress faster and easier for everyone involved.
Acknowledgment
I would like to express my utmost gratitude to Mark Bregenzer, the first German LeSS Trainer, who was my mentor since the first day I met him, and helped me not only craft and structure this case study, but also had a huge impact on my development as a Large-Scale Scrum practitioner, coach and trainer. I also would like to thank Craig and Bas for their valuable feedback and support to write this case study. And last by not least, everyone who was involved and accompanied me on this journey of transformation, especially my wife, Oksana. Without all of you, I could not write any of this.