The Hidden Cost of High Performance - Why optimizing teams in isolation can cripple organizational outcomes
_065_%20round%20copy.jpg?preferred_lang=de) by Wolfgang Steffens
by Wolfgang Steffens- 19 May 2025

The Parts vs. System Paradox “Changing parts will have little impact on the system. But changing interactions or purpose can create a massive impact.” — Steven Schuster Systems thinkers have long understood this. So why do many organizations still obsess over optimizing individual teams — driving up local efficiency while...
 by
by 
 by
by 
 by
by 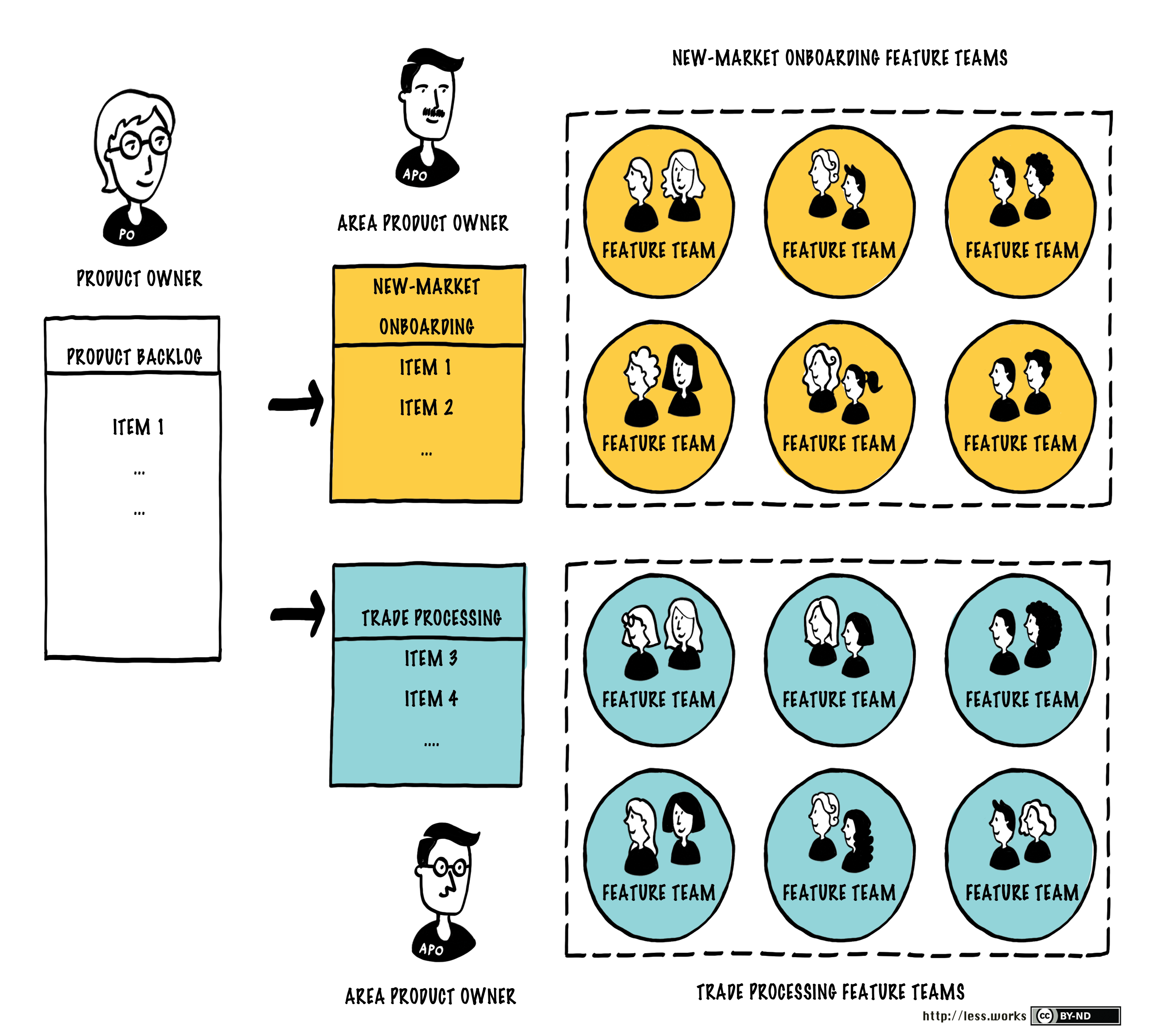
 by
by