German Big Insurance (pseudo name)
Attempted LeSS Huge adoption at a German insurance company
Introduction
This case study describes the change in a department from their initial Scrum adoption towards a LeSS Huge adoption. Those steps towards LeSS Huge included, but were not limited to:
- a re-design of the department
- establishing of Requirement Areas
- introducing LeSS events
- introducing a new way to describe requirements
- restructuring the Product Backlog.
This case study begins with a short description of the background of this case, the trial-phase (summer 2016 - December 2016, where I was not present) and the initial Scrum adoption (December 2016-March 2017) during which I already coached the department.
The LeSS Huge Adoption started in April 2017 and is described in more depth. I was present full-time until June 2017. Further, I incorporated the feedback up to summer 2018 from the Head of Development as well as other members.
Purpose
The purpose of this case study is to have a critical view on the attempted LeSS Huge adoption in the department. Even though there were many positive things achieved, the case study purposefully highlights the problems, and discusses the causes and results, because that often leads to more learning about organizational change dynamics than “smooth” adoptions. So don’t take this description as “best practice” ;)
Background
Most people do have insurances of some sorts. In order to better understand the context of this case, I will explain a few relevant aspects with the example of Otto. Otto has several insurances such as life insurance, household insurance, and a travel insurance from his insurance supplier Sampo. Otto wants to buy a new car and goes to the car dealer of his choice. He finds the car of his dreams and buys it. Additionally he is offered by the dealer various car insurances as part of a package deal. This is what I refer to in this case study as product B2B2C, a vehicle insurance. Otto has taken a liability-only insurance and comes happily home. He wants to see all his insurances at one glance and in order to do so, he logs into the insurance company website where this view is provided. The data provided to see this is coming from the (what I call in this case study) “common database”.
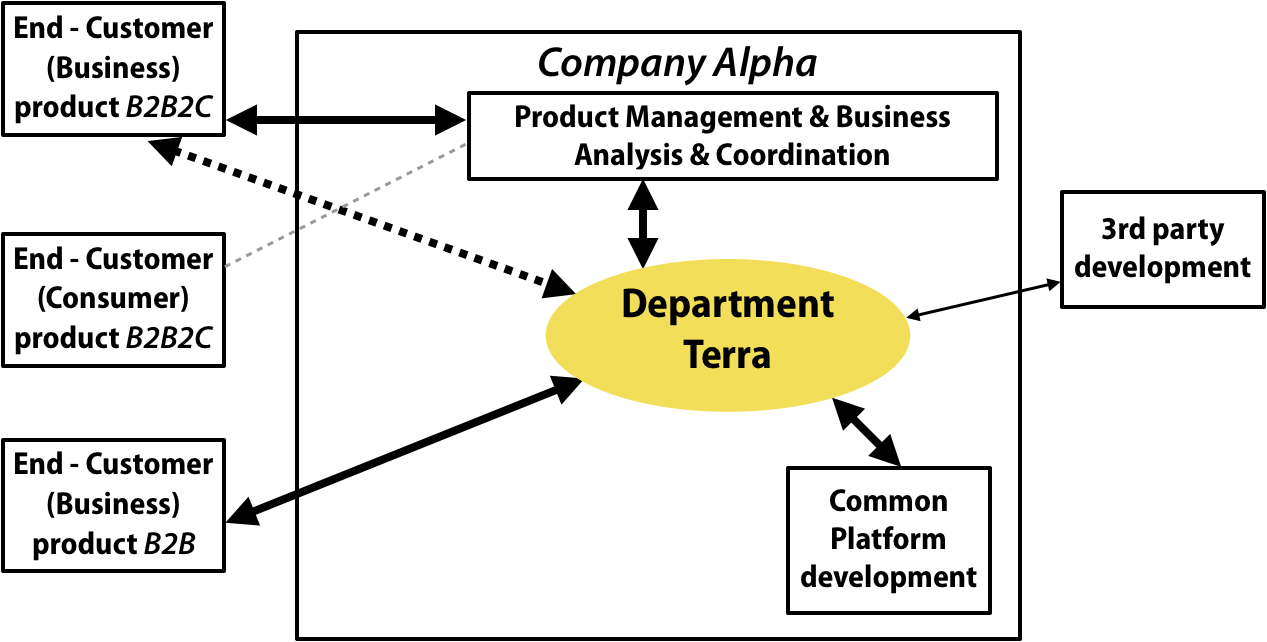
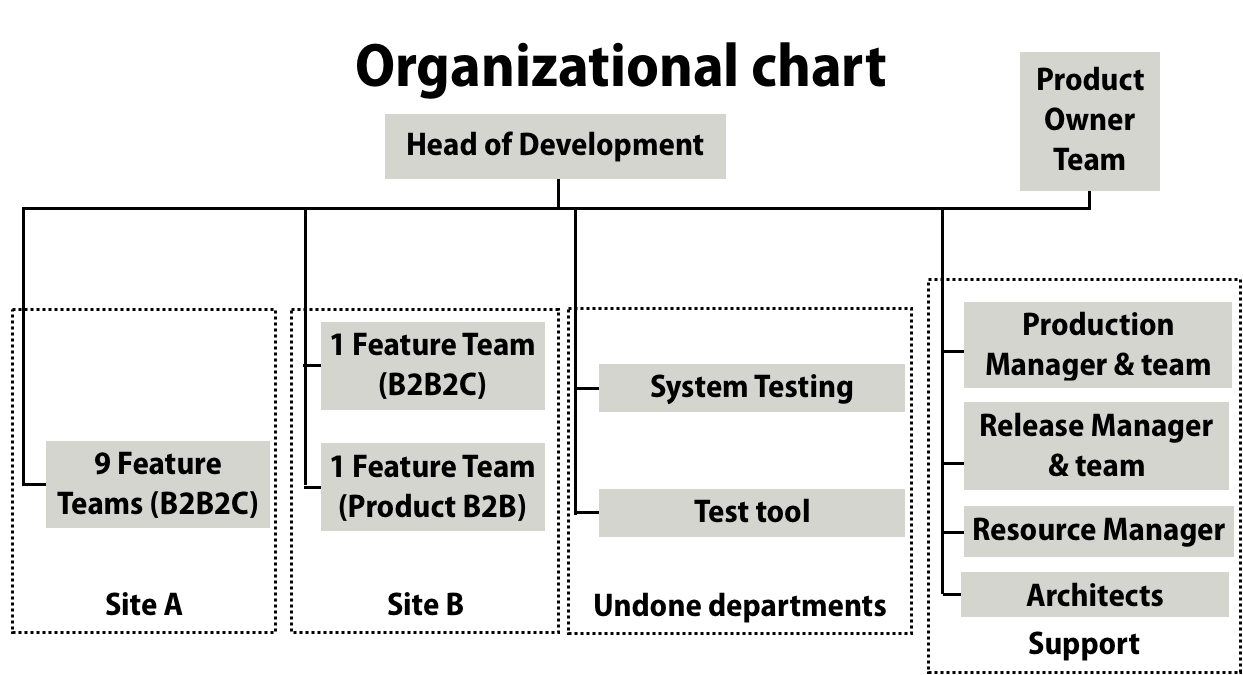
The department Terra belongs to a very large German insurance corporate Alpha1. Terra is responsible for both the development of the product as well as its operation. They create two types of products in their area of responsibility illustrated below as “B2B2C” and “B2B” vehicle insurance.
Product B2B2C was a vehicle insurance for Germany whereas Product B2B was an international insurance service for agents. Product B2B2C was built as a variant of an existing vehicle insurance product and furthermore product B2B2C utilized a common database (with data for businesses and consumers).

The existing (here called “B2C”) vehicle insurance product development as well as the common database are out of scope of this case study.
Terra consisted of about 250 people at two sites i.e., Germany and India. Out of those 250, there were about 150 in product development, and the remaining were in support functions and the “test factory”.
Another department consisted of Product Management, Business Analysis, and Coordination (I call it: PM&BA&CO). Besides market analysis, pricing, defining campaigns, the business analysis section did some high level requirements work and then handing those off to the Coordination section.
To my understanding, this Coordination section was prioritizing the requirements and constructing “Sellable Sets of Features” in the form of releases. Those high-level requirements were handed-off to Terra. Furthermore this section also “accepted” the functionality, features, and corrections coming from Terra. The focus of those activities were on product B2B2C.
The PM&BA&CO department was outside the direct scope of the LeSS adoption. However some changes in the way of working between those departments were made as described later in the case study.
There were deep hierarchies in the company and the first level of common management between PM&BA&CO and Terra was several levels up. The upper management frankly did not care how Terra was organizing itself, thus there was little upper management support for the managers inside Terra.
Customer requirements for product B2B were analyzed and prioritized by Terra itself. The purpose of the department was to develop both of the products.
Trial Phase
The department experimented with one-team Scrum and Engineering Practices on two independent sub-products. Those teams, consisting of one PO, one Scrum Master, and one Development team each, piloted Scrum for about 6 months with positive results. The positive feedback as well as other factors (e.g., need for more flexibility, responsiveness to changes, increase in business value, reduce risk of deployment, improve product quality) led to the decision to start the agile journey for the entire department.
The department established an “Agile Guiding Coalition” (AGC)2 which had the purpose to guide and support the department by e.g. define the direction, decide which frameworks to use, help the teams, and remove impediments. It consisted of Terra’s senior management team, agile coaches, an architect, a Scrum master, and a product owner.
Initial “Scrum” Adoption
Organization
Originally, the department was divided into the following functional departments
- Design
- Coding
- Testing
Each team had a team lead (TL3) and a business lead (BL). On top was a program manager (PM). Additionally, there were several support functions like architecture, release management, defect management, operations, and some other groups.
In the beginning of this initial Scrum adoption the functional departments were removed and a new structure was established.
This structure was based on fourteen dispersed Scrum teams (cross-functional but limited to one component) and was designed by management. Each team had their dedicated Product Owner (PO) and one overall Chief Product Owner (CPO)4. Other departments (Production, Architecture etc.) did not change their structure.
This structure was designed without any Large-Scale Scrum expert coaching. This change was introduced in a big-bang5, top-down, without volunteering of the people, without top-down support for the senior management of the department Terra6.
By the time I started my coaching, the newly formed component teams did meet for the first time. In these kick-off meetings, the program manager explained the reasons for the change and communicated a direction.

During this phase, the AGC decided on
- The date when the newly formed teams will work in the new structure
- A 2-week Sprint cadence
- A frame with basic Scrum ceremonies as well as a refinement workshop (per Sprint)
- A product-level Sprint Review in which volunteering teams presented functionality to other teams, senior management, Product Management
- A separate system testing function
- A Scrum of Scrums
The POs created
- A collection of implicit team lists combined into one “Product Backlog” (PB)
The teams created
- A common Definition of Done for all teams
- Various communities7 e.g., Java
The Scrum Masters created
- A Scrum Master community8
What happened then…
At the time the initial faux-Scrum adoption happened, the requirements for this upcoming release (6.5) were already analyzed and “designed”. Following old ways of working, the “remaining” work for Development and Testing was recorded in Jira. Those work items did not have meaningful estimates which made the release planning and tracking of progress practically impossible; i.e. there was a clear lack of transparency. The work items were even called “User Stories” even when they were far away from the original ideas behind User Stories9 – a conversation directly between developers and customers.
In order to compensate, the release management function created a “heatmap” for tracking and forecasting where so-called “POs” (actually, just business analysts) provided their understanding of the situation. The updating happened at first weekly and as it came closer to the release date (and “the heat increased”) the release manager updated it on a daily base.
Since the teams were just component teams rather than real development teams in Scrum that could do everything end-to-end, the dependencies between the teams were stunning, to get a true end-to-end customer feature done10.
The work came frequently to a complete stop due to unsolved development bugs which ping-ponged between the component teams. It was difficult to find a team who could fix the bug and thus the fixing took a long time.
The existing build system did provide delayed feedback and the integration was cumbersome. Regression testing was done manually and system testing was only possible just before the end of the release.
As an attempt to quick-fix the ping-ponging of defect handling the AGC established a central coordination meeting, a Scrum of Scrums (SoS), which helped.
Note: the SoS meeting did not solve the root-cause problem of defect ping-ponging, the component-team structure, it just reacted to it.
As stated in the experiment “Try… Scrum of Scrums” experiment, this meeting helped in the short term to deal with defect handling. The SoS used one physical board from which all teams selected items, and saw what was going on. It was a meeting from the teams for the teams11. Each team did send a representative which was not the Scrum Master12. The team representatives rotated every Sprint or every second Sprint13.
On the other hand, the SoS did not address the root cause of this problem which consisted of
- The structure of the organization with component teams who are dependent on each other.
- The existence of the Defect Management group.14
- The lack of an appropriate information system.
If an organization wants to create a better environment, and thus removing those hindering element, it is suggested to avoid such a central meeting like a SoS15.
Due to the lack of maintaining a stable product, feature development ended with a code-freeze following by a “hardening” period 16 which was in parallel to a user acceptance test period before the new release was allowed to go live.
Each team worked according to their own team backlog17. All those lists were stored in one tool artifact as a so-called “Product Backlog” yet the department did not really have one common backlog in terms of work and teams; that was an illusion. Rather, they had many “implicit backlogs” associated with different teams, stored in one tool.
Due to the component teams, many handoffs, implicit backlogs, many overhead coordinators, and other reasons, it took until around midpoint of the release development that it became obvious that not all the content could be delivered in time.
And so as a response to seeing this delay, the list of customer-centric high-level requirements was finally ranked by the program manager. This action created a common PB (in a simple spreadsheet) and brought focus to the department. Now, also other analysts so-called “POs” and their teams sacrificed “their own” (not-so critical) work and helped out the other teams to fulfill critical requirements.
Towards the end of this release only very basic and critical functionality was delivered.
Overall, when using number of bugs as a proxy measure, the technical debt was growing with this release.
Furthermore some component teams already started to think about the next release, even though they were not finished yet with the implementation of their critical content. This led occasionally to heated discussions.
At this point in time it was clear that we would have a redesign of the organizational structure in the department Terra, starting with an initial Product Backlog Refinement, and yet the Scrum Master of these teams pushed the component scheme further.
Learnings
When reflecting on the current situation in the AGC, and mostly with the program manager, it became obvious that this organizational structure was not sustainable. In fact, many people realized and learned that the coordination effort was huge, work was fragmented due to the usage of implicit lists, and thus the wish was expressed to have a different structure with more independent-working teams.
Furthermore it became obvious that requirements needed to be described in a different way, the PB needed a different structure and a different working model to maintain the PB.
LeSS Huge Adoption
Problems and Context
I believe that with the initial fake and “naive scaling” Scrum adoption, the program manager was pretty frustrated about the lack of transparency and the need for cross-team coordination. I felt that the trigger to adopt towards LeSS Huge was that the “Fear of the unknown was less than the fear of the known”.
As a consequence, the LeSS Huge adoption was not decided as such, crucial LeSS adoption principles were neglected and the first step in the LeSS Guide on getting started was executed with far too little attention.
Thus, I suggested those actions which I saw most meaningful within certain constraints. In this sense, the department made a first step to become more adaptable.
LeSS Adoption principles
There are three LeSS adoption principles18 which are crucial to an organizational LeSS adoption:
- deep and narrow over broad and shallow
- top-down and bottom-up
- use volunteering
Deep and Narrow Over Broad and Shallow
The basic idea is to limit the change to e.g. one Requirement Area (RA19) or about 50 people at once, learn and experiment for some time, and then change the next RA.
This was not done here. In the initial (faux) Scrum adoption, all development in the department was changed at once in a big bang. It was a mess and I considered that the department was in a state of chaos, where one needed to act swiftly. Furthermore, since there was the second product (B2B), the amount of people who were affected by the LeSS Huge adoption were not that many. It remains a border case from this perspective and it should not be regarded as a typical LeSS adoption.
Top-Down and Bottom-Up
Also this principle was not followed as the adoption was purely a bottom-up. Yes, it was the entire department Terra, however the existence of the department PM&BA&CO is proof that there was no top-down support for this change. In fact, there are several decisions made by upper management, in the months after which I had left the organization already, which indicated the lack of their support for this change (see Epilogue).
Use Volunteering
Volunteering was used very little if any at all in the beginning of the “Scrum” adoption. By the time the LeSS Huge adoption started, the department used the concept of volunteering more and more, especially seen in the self-designing teams workshop. This workshop created the required confidence by the senior management to continue and promote volunteering.
LeSS Guide: Getting Started
Step 0 in this guide is to educate everyone and it was pretty much ignored. It was pretty difficult to motivate the program manager to invest in sufficient training as required20.
… and then we started…
As a result of the learnings from the initial (faux) Scrum adoption, the AGC decided to make some fundamental changes. I, as the coach, had a high buy-in from the AGC to create one Product Backlog (PB), and the required clarifications and structural changes was seen as a “necessary but painful operation” to achieve this goal. Thus the resistance for the required structural changes in the department by the AGC were low.
The adoption started with the need to have an initial PB refinement workshop21.
This decision triggered several critical issues which needed clarification upfront, like:
- what is the Product?
- what is the organizational structure?
- what is the initial priority of the high-level customer requirements?
Note: This initial list of high-level customer requirements was ranked by PM&BA&CO, we avoided to create feature priority categories. Those requirements were pretty big and some might be implemented over several releases. Besides PM&BA&CO, also architects22 and teams, each brought in their list of requirements to serve as an input for this workshop.
The preparation of self-designing teams workshop, the definition of the product and their areas, and the initial Product Backlog Refinement workshop took about three weeks. An enthusiastic internal full-time coach facilitated most of the discussions between senior management, members of the department, and other required people.
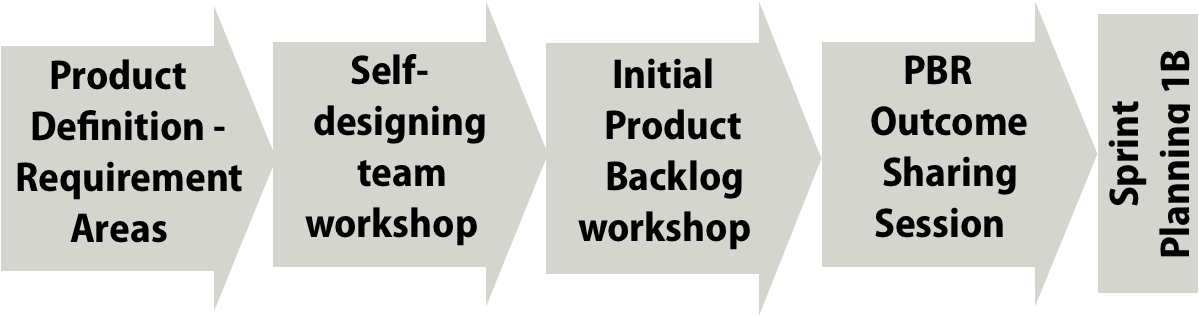
Various member across the department had severe doubts that this change could be done in a few days. Therefore I would like to highlight that the actual events happened swift after each other without days of inertia in between:
- Monday afternoon: Self-designing team workshop
- Tuesday & Wednesday morning: Initial Product Backlog Refinement Workshop in the new structure
- Wednesday afternoon: PBR outcome sharing session with new APOs
- Thursday: Sprint Planning 1 and Sprint Planning 2 in the new structure following the regular Sprint cadence.
Problems with Product Definition and Requirement Areas
The Product Definition workshops revealed that the department had actual two (customer-centric) products:
- Product B2B2C was a vehicle insurance for German market only
- Product B2B was an international vehicle insurance service for agents
Product B2B2C was dominating the department’s workload and focus, whereas Product B2B was in a start-up mode with potential to grow in the international market.
Product B2B followed the started with one feature team with a real Product Owner, and a Scrum Master. The newly formed Scrum team was co-located in India whereas the PO was located in Germany. Thus the Product B2B is mostly excluded from the following discussions.
Note: All products were built on the same code base, and they were based conceptually on the same vehicle insurance product23. In other words, both product B2B2C and B2B maybe could be seen as variants of this underlying product, which was developed in a different department. However, due to the organizational boundary limiting the product definition, those two products were defined.
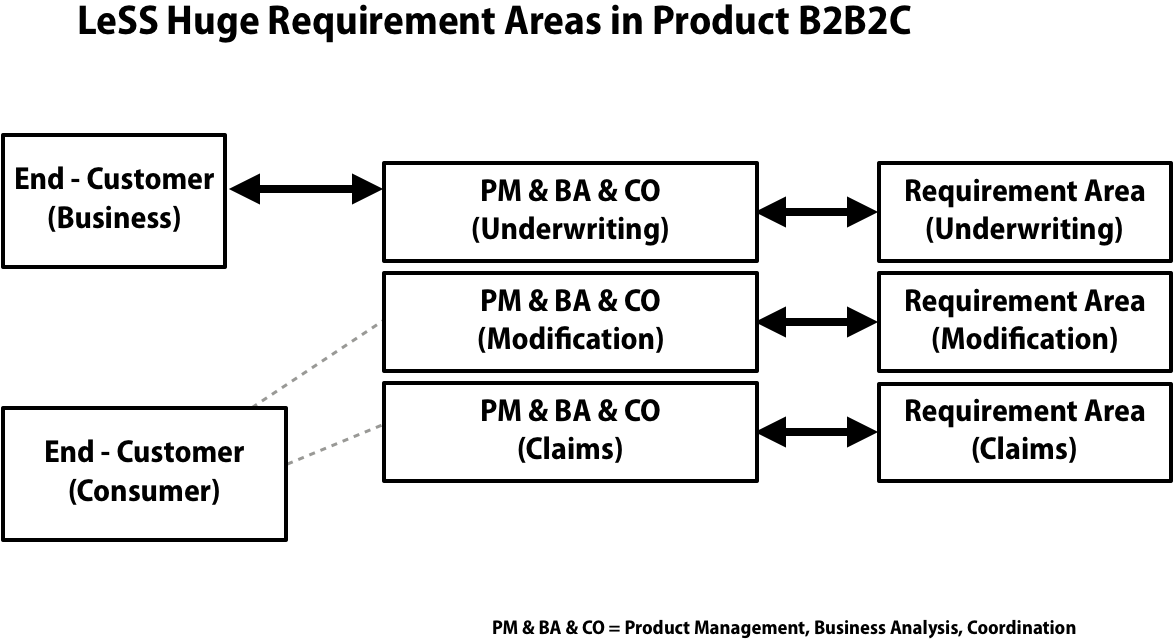
The Product B2B2C consisted of ten teams24 and they were divided into three RAs following roughly the “Insurers’ business model”25:
- Contract Underwriting (five teams)
- Contract Modification (three teams)
- Claims (two teams)
Reflection on the chosen set-up
In order to optimize for adaptiveness and to more likely be working on highest value from a global view, one of the LeSS Huge framework rules is that each RA has between “4-8” teams, so that there are fewer lists (backlogs) in relation to number of teams. The structure in department Terra violated this rule as two RAs were below 4 teams (one RA had three, the other two teams).
Those teams in RA Modification and RA Claims did not know the items in RA Underwriting well or at all. If the PO would want to adapt so that more teams would focus on items in RA Underwriting, Modification, and Claims teams could not do them (without first learning about them), they would not be able to adapt and they would be stuck with the items in their original RAs, which might be lower value from a global view. The issue was understood by the program manager, yet the decision was to start with this structure, for the reasons described next.
One reason was that the choice supported the existing PM&BA&CO department structure which was divided into those three areas and this change ensured a smoother transition in regards to external interfaces. This enabled the APOs to work autonomously in their area. In other words, since a significant part of the product group was still structured in a traditional way (since this was just a partial LeSS adoption), the choice of too-small RAs was a compromise to help alignment with the traditional group, considering political forces.
On the other hand, the program manager saw that there were also reasons to combine those two areas in the future (from an APO view) since firstly he believed that once the APOs might be more firm in their new role, one could handle both areas, and secondly one of the APOs expressed a long-term desire to move on, and thus this position would not need to be filled again, but rather, the two areas in the future will be combined.
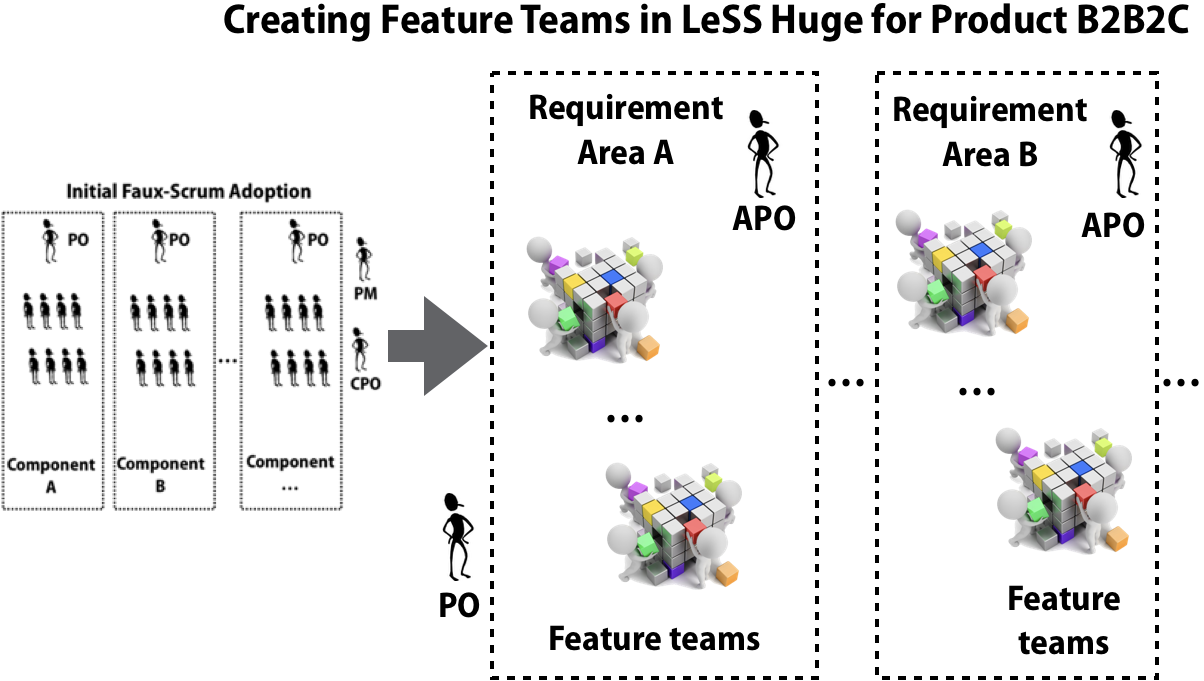
Another issue: To let go of the “doctrine” of one “PO per team” was another huge step for the APO candidates. Thus the discussion to find the APOs took several weeks26. In the end the Product Owner found three suitable APOs which felt comfortable (aspects like cognitive load, willingness to experiment and learn with the new structure) to own an area and have multiple teams working in each area.
Problems with The Self-Designing Team Workshop
The department Terra had successfully challenged the status quo by allowing teams to self organize for the first time in the history of company Alpha. This event gave to many in the department a motivation boost which was still noticeable several months later.
All developers from Terra participated in this event, that includes the India site as well. The developers in India also organized themselves locally at the same time.
With the previously explained prerequisites or constraints established, the program manager supported the development teams to re-organize themselves in a self-organizing manner.
Preparation to the workshop
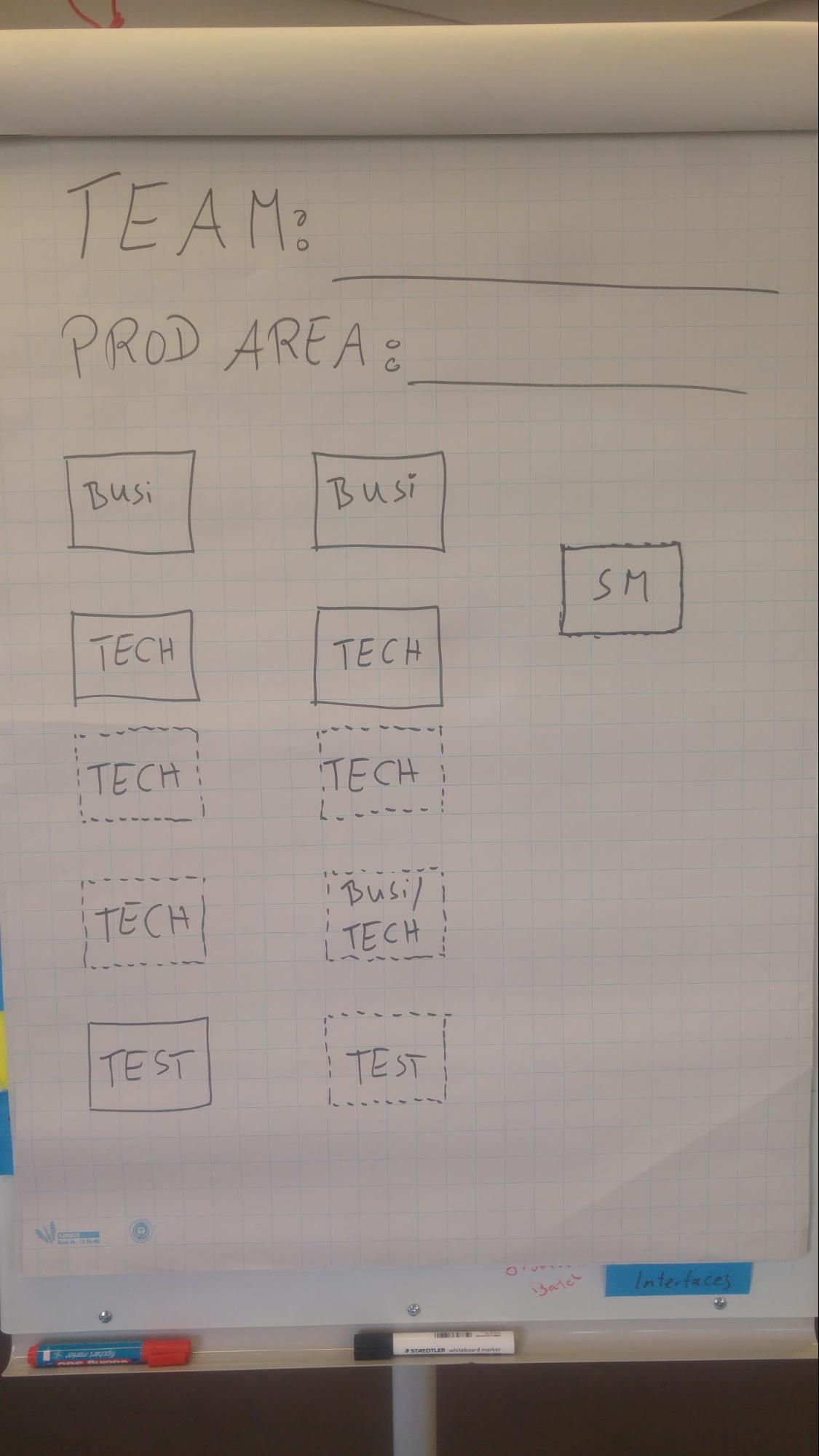
In order to prepare the self-designing team workshop, a small group of representatives and coaches (not only managers) created a list of all the skills required to deliver customer value (see next paragraph), and prepared a set of boundary conditions which would help to achieve the goals of the workshop.
Boundaries
The illustrated team layout template was used to provide boundaries that supports having customer centric feature team
Additionally to the team layout template, the following boundaries were provided:
- Team must be co-located
- Team must be cross-functional (i.e., Business, Technical, Test)
- Team must be cross-component (skills e.g., portal, rich client, documents, orga workflow)
- Team size was 5..9
- Team has a mix of Agile enthusiasts and Agile skeptics
Note: In an ideal case, the team members would be able to do this preparation work all by themselves, they would set their own boundaries, their own schedule, and they would not need a predefined team layout template.
However giving all the constraints and the immaturity of the people at that time, the coaches suggested to provide such boundaries. Those boundaries and the workshop preparations were required to get the AGC’s approval for the workshop.
Workshop execution


The agenda of the workshop looked like this:

Each person got a pre-printed name batch (name, color coded for their core skill - business/technical/testing) and the option to mark the deeper level of competence on the batch. The facilitators ensured that absent colleagues were represented by their teammates. The people were then asked to pin their batch to the team layout template to illustrate the new teams’ set-ups.
The review rounds gave everybody the possibility to review and challenge the other teams’ set-ups.


The workshop ended with almost all the goals achieved. Especially remarkable was that all teams were indeed cross-functional, cross-components, and co-located27. A major difference compared to the previous organizational design!
Parallel to the self-designing workshop in Germany, the developers in India also formed feature teams. One team was formed to create (the tiny) Product B2B and the other one joined the newly formed RA “Underwriting”.
Several major problems were observed.
- The idea was to split the operational work into an own group (outside of the RAs) which would not follow the Scrum cycle (such tasks are e.g. monthly closing of the finance system, answering customer and user questions). However, no team lead was found at the time of the workshop, and the program manager was acting in this position. Since he was purposefully not present during the self-designing workshop, this team was not staffed to a level that it could operate. As a result, the people decided that the operational tasks remained in the development teams (like it was before)28.
- For anybody who would facilitate such a workshop, it might be important to understand that there was another challenge which led almost to an unsuccessful workshop. A handful of people had difficulties to create a team according to the guideline. The people were stuck on their points of view and positions which lead to a deadlock situation. Even after several rounds of letting people try to resolve the conflict by themselves, there was no solution. As it is very common when moving to the self-organizing-team Agile principle expressed in Scrum, the people were not educated or experienced in how to resolve such conflicting situations by themselves, neither did the coaches nor the Scrum Masters come up with ideas. In the prior traditional management model, separate managers made such decisions, so that the regular people did not feel empowered or capable to make their own decisions and work through conflict. It was only through the intensive collaboration of the APOs and coaches that led to a solution in the end.
Problems with the Product Backlog
This section will include two main sections: The Product Backlog and the Product Backlog tool.
Product Backlog
In LeSS Huge there is one Product Backlog where every item in it belongs to exactly one Requirement Area. Therefore, there is one Area Backlog per Requirement Area.29
Since there were three RAs, the PB consisted of those three Area Backlogs, each owned by one Area Product Owner (APO).
It was a huge challenge for the department Terra to create a PB with customer-centric items and which focused on outcome instead of output.
The main focus of this upcoming and the next releases was to provide an insurance solution for a new car manufacturer (let’s call them Porsche). This huge requirement was instantly broken down into the three RAs whereas Underwriting needs to happen first, and both Modification and Claims built on top of that logically.30
Furthermore, it was discussed with ‘Porsche’ that there will be two major steps in the overall solution. The first step would focus on the complex technical integration of the two systems (Porsche’s and the insurance company’s) with a minimal set of features. This would not lead to a commercial launch. The second step would include all the required features for the commercial launch. Pretty soon it became obvious that there will be a third step, as some features and functionalities were not required for the commercial launch yet they must be there later on.31
This led to the following skeleton which represented high-level requirements in the PB:
| PBI | Release | Underwriting | Modification | Claims |
|---|---|---|---|---|
| Porsche: integrate | 6.5 | Porsche: integrate | Porsche: integrate | Porsche: integrate |
| Porsche: launch | 6.6 | Porsche: launch | Porsche: launch | Porsche: launch |
| Porsche: rest | 7.x | Porsche: rest | Porsche: rest | N/A |
Each of those high level items (of 6.5) was pretty big and in order to get to the level where about four items could be done per team per sprint, there was a need to introduce an intermediate level.
It is important to note that e.g. “Porsche: integrate” was mainly a coarse-grained and gigantic category or ‘bucket’ item and not a fixed set of requirements i.e. it was not an undesirable “big batch” which needed to be done all. Instead if during the splitting the parties realized that some functionality is not needed now, but later, it was moved into the later bucket e.g. Porsche: launch.32
Thus the PBIs were divided into three levels (see section Requirement Handling for a more detailed illustration on the content).
- Level 1: Large, coarse-grained requirements or buckets (idea: can mostly be done within release, if initially it might go over several releases, somebody creates buckets)
- Level 2: Medium requirements (idea: can be done within release)
- Level 3: Small (fine grained) requirements (idea: can be done within Sprint)
Product Backlog Tool
The LeSS guide Tools for Large Product Backlogs is to “Use nothing more complicated than a spreadsheet and wiki.” So, no “ticket tools” (such as Jira) or so-called “agile management tools” (such as Rally). Why?
- These tools contain and promote reporting features, reinforcing traditional management-reporting and control behaviors.
- These tools support and reinforce traditional big-batch to little-batch work breakdown structures and processes, where an old separate business group decides major items (of large size and bigger batches) that are then pushed into the development group to do in smaller sizes and batches; this is just traditional non-lean management usually with a facade new jargon, such as “epics” and “stories”.
- They convey a facade of improvement or agile adoption, when nothing meaningful has changed; “agile-jargon” tools have nothing to do with being agile.
- They often impose inflexible terminology and workflows to the teams, taking away process ownership and restricting improvement.
- These tools enable complexifying rather than simplifying.
- They often require significant tasks of customization, integration, and ongoing updating which drives the creation of another overhead wasteful role such as a “Jira secretary” ala a fake “Scrum Master” or “Product Owner.”
Instead of following this guide, the department Terra decided to use
- A spreadsheet for level 1 items
- Jira for level 2 and 3 items
This spreadsheet was also used in communication (also re-planning, reporting) with PM&BA&CO group, since they were still operating in a traditional model. Over time, the cooperation between both departments Terra and PM&BA&CO improved, resulting that this idea of the buckets was working, and the conversation shifted to align common views and understand the “big picture”.
One of the biggest problems was that one of the senior managers of PM&BA&CO did not understand this concept (and way of working) with buckets. This led to frequent arguments and wasteful discussions, even though all other parties in the room agreed and knew what was the situation with the items.
Another self-created problem was to keep this spreadsheet and Jira in synch, and to keep the data in Jira maintainable and consistent. This required a lot of manual work and basically justified the existence of the entire release management support function (see chapter Release Management).
The reasons for using Jira are vague and I can only guess. Firstly, one would be that Jira already was in place from the traditional management approach, it was used for bugs, and various sorts of other things. Secondly, Jira allowed the type of “control” driven by traditional management thinking33, meaning the program manager might not have trusted the people enough and wanted to have the option to control.
Since Jira was non-negotiable (so much for Inspect & Adapt), the coaches’ aim was to minimize the damage caused by the tool. As a result, the Product Owner Team, coaches, and support people were involved in introducing a new Jira project with a drastically simplified workflow including a new structure only with the extensive help of a costly Jira tool expert.
The Jira list (which can’t be called a real LeSS Product Backlog) contained only medium and small sized PBIs, their estimates, ancestor info, links to design info, comments etc.
The release burn-up chart which was created by Jira per RA offered only mediocre reports.
Further, there was a risk that release management function would collect data via the tool instead of getting the data from the APOs. This caused some additional friction initially, especially when release management acted as a “controller” of the APO status reports. However, the risk was eliminated after a few sprints and release management function let go of this “controlling” activity.
Although the program manager insisted to use Jira, Jira was clearly a fake and inadequate “PB” tool. Plenty of effort would have been avoided if the department had simply started with a spreadsheet.
And besides all that, Jira was useless during Product Backlog Refinement (PBR) and Sprint Planning. At least one of the APOs printed out relevant items or wrote them on cards which were pinned on a board (see chapter Sprint Planning).
Problems with Initial Product Backlog Refinement
The creation of the initial PB was a tremendous challenge for the department as everybody needed to learn how to split requirements in the new way34. There were doubts that the initial PBR workshop could ever produce anything meaningful with little or no upfront design.
Architects and representatives from PM&BA&CO participated in the workshop to support the teams in the refinement, define acceptance criteria, and clarify questions right away. The coaches and most of the Scrum Masters co-facilitated the event.
In a desired scenario, customers/users and the teams clarify the PBIs together. In this initial PBR the customers/users were not present, instead they were represented by members from PM&BA&CO35. Those are “middlemen analysts” which stood between the teams and the real customers/users.
However, compared to the earlier releases, where specifications were handed over, this common session in which people talked to each was a first step in a better direction.
Nevertheless, the dysfunctions of this set-up were the waste of hand-offs (and related loss of information), building up of inventory, and reinforced the existence of the dysfunctional role/department.
During this initial PBR, the teams refined items mostly together with other teams within their RA. After 1.5 days, the initial PB was created with flip-charts and post-its on the wall. Some items had acceptance criteria. There were enough PBIs (almost all were end-to-end) to fill at least one Sprint fully for each of the teams. Progress!
In the end of the initial PBR, the teams estimated the items using “Magic estimation”36 method with relative story points37.


Problems with the PBR Outcome Sharing Session
After the initial PBR workshop was finished, the ranked list of items (post-its) were visualized on the walls. In a sharing session, the APOs presented their lists with the purpose to get a common understanding between the Product Owner Team, PM&BA&CO, the test manager, test tool lead, production manager, release manager, and chief architects38.
The goal was to get transparency on:
- which items can be delivered with high certainty
- which items might come
- which items are clearly out
Note that there is no such “sharing” event normally in LeSS, because the people with whom the information was shared after initial PBR should have been actively in initial PBR; the fact a separate sharing had to happen was a sign of not having an effective top-down change in which traditional groups and roles were eliminated.
On the other hand, LeSS Huge describes the possibility for the Product Owner Team (POT) to synch before Sprint Planning and I think a lot of this synch happened here, so it was useful, but also contained wasteful activities with traditional groups.
This sharing meeting did build trust and confidence within the POT, within the department, and to PM&BA&CO. Furthermore, the seeds were planted to keep on re-planning and re-prioritization on a regular base. Progress!

Problems with the new Organizational Structure
Larman’s Laws of Organizational Behavior
- Organizations are implicitly optimized to avoid changing the status quo middle- and first-level manager and “specialist” positions & power structures.
- As a corollary to (1), any change initiative will be reduced to redefining or overloading the new terminology to mean basically the same as status quo.
- As a corollary to (1), any change initiative will be derided as “purist”, “theoretical”, “revolutionary”, “religion”, and “needing pragmatic customization for local concerns” — which deflects from addressing weaknesses and manager/specialist status quo.
- As a corollary to (1), if after changing the change some managers and single-specialists are still displaced, they become “coaches/trainers” for the change, frequently reinforcing (2) and (3).
All of those laws were observed in this case. The following paragraphs describe the organizational set-up in more depth as well as dysfunctions of the various groups and functions.
Product Management, Business Analysis, and Coordination (PM&BA&CO)
The fact that PM&BA&CO was indeed a separate department in company Alpha, made it harder to involve them in the adoption. In a change with both top-down and bottom-up support, the two departments PM&BA&CO and Terra would have been integrated into one department.
Thus the existence of this dysfunctional setup created especially in the beginning misalignment regarding how things need to be done, for example:
- They kept on delivering big requirement definitions.
- Expected commitment for content of release (see the contract game)
Through coaching, educating, and having common workshops, the cooperation improved over time. But due to the missing support from the top management, other practices e.g. budgets, incentive system, target setting might outweigh those improvements in the long run.
Head of Development and Product Owner
A fundamental LeSS rule is to have one and only one Product Owner. Several options were considered to answer the question who would fulfil the role of the one Product Owner. It became clear that she could not come from the existing PM&BA&CO39 department because they were only involved in Product B2B2C and not at all in Product B2B.
When the LeSS Huge adoption was kicked-off it became obvious that the program manager was both the real Product Owner40 and at the same time the “Head of Development” i.e. leading the entire organization (one person with two different roles).
Product Owner Team
The Product Owner Team (POT) consisted of the PO and the three APOs.
The POT met frequently to re-plan and re-prioritize the PB for short- and long term. As it was hard to get hold of the PO, the Product Owner Team established a 15 minutes daily stand-up to be able to synchronize daily issues with the PO if needed.
Later on, the POT realized that the need for regular re-prioritizing of the PB. This was done together with representatives of PM&BA&CO. It took several rounds before the participants were able to have focused discussions on either short term (1-2 Sprints) and medium term items (next 2-3 months).
Instead of continuing the contract game, the conversation slowly moved towards a more collaborative nature and focused on the exchange of information, and findings ways together to make the next release as valuable as possible.
Feature Teams
Another of the LeSS rules defines that each team is self-managing, cross-functional, co-located, and long-lived.
After many years of working in a command & control environment, the feature teams started to learn to be self-managing. The developers swiftly reseated themselves so that all members of a feature team were sitting together within an arm’s length. The RA “contract underwriting” had 5 teams, from which four were at the same site as the APO, and one team was in India.
After the self-designing teams workshop, all feature teams were cross-functional, and cross component, being able to generate customer centric features, i.e. outcome instead of output.
The teams were stable in the sense that team members were not pulled out to be staffed in task-forces. Due to the fact that the majority of the team members came from partners, there happened an exchange of members every 1.5-3 years.
Many of the team members (and managers) were partners (or sub-contractors), and sometimes even competitors. This fact limited the amount of self-management in the teams significantly.
The fact that members change as often as here, is another dysfunction which prevents the organization and the teams to learn as a whole. Individuals do learn and then they leave to another company and take all their knowledge with them.
Scrum Master
None of Scrum Masters had experience with Large-Scale Scrum and LeSS in particular. All had great ideas on how to support 1-2 teams Scrum transformation but did not have the needed knowledge and understanding to support a larger scale adoption. Neither did they have extensive experience on the basic Scrum Master role of coaching the PO, management, and the organization or in other words, to “create the environment for people to succeed”.41
Unfortunately the LeSS rules about the Scrum Master were only partially fulfilled.
The biggest gaps were the lack of knowledge on LeSS, and their inability to focus on the organization, development practices, and the overall organizational system. With the LeSS Huge adoption, all Scrum Masters were dedicated in this role and served 1-2 teams within one RA.
During my time, the Scrum Masters started to learn about LeSS rules, principles, guides, and the experiments. In particular they learned to support LeSS events, their APO, and the overall organization as a complex system. Focusing on development practices was not yet in the focus of the Scrum Masters.
The Scrum Masters formed a community across all RAs which helped a lot to develop their skills, mindsets, and where they could support each other42. Furthermore, they learned to facilitate large-group events43.

One of the Scrum Masters had a SAFe background and he resisted all structural changes we planned. It became clear to the program manager that this situation needed to be resolved. Thus the contract of this Scrum Master (he was as many others also external) was terminated early.
Undone Departments
In general, Undone Departments are a dysfunction. They should be avoided in the first place, and certainly eliminated over time as the Undone Work is done more and more by the teams.
In the department Terra the “Undone Department” consisted of:
- System and Acceptance Testing
- Test tool
System and Acceptance Testing
System Testing for new functionality was done by the teams, however the regression testing on system level was done mostly by the “Test-factory” in India44 which was “supervised” by the test manager. Most of the tests were executed manually.
This dysfunction leads to long feedback cycles, hand-offs, communicating through tools, us versus them, less learning, splitting responsibility from action, and an unclear view on how ready the product increment is for shipping.
Furthermore, the “test-factory” came from a strategic partner and this partner was swapped against another partner who promised also more speed in automating regression tests. This change delayed the start of most of the needed experiments. In short, this was pretty messy and chaotic and far from optimal for a LeSS adoption, yet it was a first step towards an potentially improved situation.
In general, the goal was to automate the regression and system tests in the long run, and either eliminate this function completely or at least reduce it significantly. However, I assume that this goal was actually in contradiction to the goals and interests of the partner as the partner earned pretty well by providing the “bodies” to perform the tests manually. This was another dysfunction when looking at it holistically and it was ignored by management.
Test tool
The Test Tool team was responsible for building and developing one part of the acceptance testing framework, maintaining the servers to run this framework, and perform some of the acceptance tests when the product was planned for release. The Test Tool team participated in many Sprint events together with the feature teams.
This dysfunctional setup prohibited (or at least hindered) teams to learn about acceptance test driven development and the required tool development. Furthermore, the situation created hand-offs, longer feedback cycles, dependencies, and the need for coordination.
This group existed because of historical reasons, i.e., the test tool was always done by X. Furthermore, the tool’s architecture was built in the head of X, and as far as I know there was not sufficient documentation that the teams would be able to continue the development of the tool by themselves. Management allowed that situation as I assume that the risk of delay the development was perceived greater as the adverse effects of this setup. To my knowledge this group kept on existing with no plans to eliminate it.
Customer Documentation
With the LeSS Huge Adoption, the local45 CuDo group was dissolved and integrated into the teams.
Support Functions
The support functions consisted of: Production Management, Release Management, Architects, and a Resource Manager.
In general, support functions are a dysfunction in a LeSS adoption. They should be avoided in the first place, and certainly eliminated over time as the wasteful work is either eliminated, useful work is owned by the teams, and the competencies are created in the teams.
Generally those functions hinder teams to become self-managed, create hand-offs, and delay the flow of information.
Production Management
Production Management consisted of two groups: defect management and set-up.
Defect Management
The product B2B2C had a huge amount of accumulated defects. Those were caused by the structure of department Terra, the fact that there was the “test factory” in India, and the fact that the communication between the test factory and the development teams was done through the defect handling tool. So, when the testers in India found a defect in either system test or regression test, they wrote a ticket in the system and they saw their job as “finished”. The development teams could then figure out how to fix it.
The department Terra had an own group to coordinate the defects coming from the test factory, end-customers, production system, and other users of the product. This group provided first level support as well as coordination for those issues beyond first level support across the teams.
The coordination did not work well as they acted like a “shadow to the APOs” by trying to inject work to the feature teams. The miscommunication to APOs and teams was a constant point of friction.
As one of the key persons from that group left the company, we discussed the option to move the defect management responsibility into the teams. However, the ideas were shot down by the Head of Production and unfortunately those ideas were lost for good. A few months later the Head of Production left the department.
The biggest dysfunctions were first of all in the root cause of the problem i.e. the existence of the System and Acceptance Testing group, as well as in the communication through the tool, and the attempt to inject work into the teams from the side.
Set-Up Team
The set-up team was responsible for the build system as well as getting the final software into production46. They also were responsible for parts of the operation thus they required a close cooperation to both, the Test tool team and the feature teams. The details about the cooperation and work split are not known to me. Anyway, it added complexity to the work and variability to the workload of the feature teams.
The existence of this group created hand-offs, limited the learning of the teams to build the system they really need, created long feedback cycles, and moved the responsibility to outside the team, so that forecasts became even less predictable. This responsibility should be in the teams.
Release Management
The role of the Release Management function was to help the PO, APOs, instead of the regular teams47, and teams to maintain the troublesome PB in Jira, check for data consistency, support teams, APOs with entering data to Jira, create and maintain the link between the spreadsheet and Jira, make reports to upper management, help the APOs to create burn-up charts, and other information needed for PB ranking.
In terms of a LeSS adoption, the work of this function was clearly waste and the biggest reason why the function existed was because of the usage of Jira (of course nobody calculated the value added neither the costs for that). With a more appropriate PB tool, this function could have been eliminated quickly.
In fact, since the demand for “release management” i.e., coordination went down significantly with the start of the LeSS Huge adoption, the function was downsized, the head of function left and was not replaced.
Resource Manager
The Resource Manager was responsible to support the program manager to create and maintain an overview who works in the department, establish a competence matrix, identify strategic future needs, and potential problem areas.
The old line management structure was eliminated completely, and the program manager did not have free cognitive capacity to handle all the line people aspects (as in the LeSS organizational design system where the Head of Development would be in this position), and as a quick fix, a resource manager was introduced.
Architects
In a real LeSS adoption, the architects are integrated into the teams and do not form a separate function of their own.
As this function, consisting of 4 architects48, helped the APOs to split the very high-level requirements (into RAs) it took away the responsibility which belongs to the teams. This dysfunctional setup leads to e.g., upfront design decisions which cause unnecessary constraints and burden to the teams, and it might lead to suboptimal solutions in the implementation. Hand-offs and delays/waiting are just some of the typical waste types.
Additionally I would like to stress that the existence of such a group supports the Theory X model, in which “some think, others only do” i.e., architects think, teams “only execute” - a major issue in many organizations.
Nevertheless the architects acted mostly like mentors towards the teams49, participated refinement workshops50, and hosted the architecture community51. The teams had already enough basic architectural competence to refine most of the requirements by themselves. Yet the support from the architects was often appreciated in the start of the adoption.
The reason for the existence were in my understanding as follows:
- The program manager believed that integrating architects into the teams would be too high of a risk
- The product was part of a larger system52, which had a crucial interfaces to the other systems, and the program manager did not want to change anything in this setup towards the outer world
- The architects did not feel that they need to change
In the end of my assignment the chief architect came to me and asked whether it would make more sense that this group of architects would dissolved and go closer towards the teams i.e. into the Requirement Areas in the first step. So there was a light in the tunnel.
Problems with Operational Tasks
Department Terra was also responsible for running the software and had different kinds of operational tasks. Those tasks consisted mostly of answering customer clarification questions on how to use the software, early analysis related questions by PM&BA&CO, monitoring of data (and up-times), and supporting product related reports (not status) to other parts of company Alpha.
An analysis workshop aimed at identifying those operational tasks in more detail, making those transparent, and identifying if there would be other ways to deal with them (e.g. move some of the clarification work into refinement workshops, like in the principle “More with LeSS” through eliminating extra processes).
Basically there were two options identified at the time:
A. The same team who develops the software is responsible for operational issues.
B. A dedicated team would be responsible for operational tasks
Another solution, which is recommended by LeSS, would be to have a rotating role, which means that one of the teams (maybe one rotating team per RA is needed in LeSS Huge) is the “fast response team” so that the variability in the remaining teams is reduced. This role is rotated e.g. every 1-2 Sprints.
Those individual tasks themselves were not big, it was rather the big number having many small tasks53. Putting them individually into the PB would blur and explode the PB. Another way to deal with this is to examine (in hindsight) how much time those tasks would take, and then the PO and the team would reserve some percentage of the team’s time for those activities (see Guide: Handling Special Items).
Solution (A) was in place before54 and during the LeSS adoption. This caused some unpleasant and disturbing variance in the work scope of the teams and impacted Sprint forecasts.
The advantages of this solution were as follows:
- The teams get to feel the pulse of reality on how their product really performs
- Reduced number of hand-offs and queues
- Provides the opportunity to the teams to learn and improve the current customer-facing challenges
- Making the problems transparent so they can be dealt with
Note1: In the case that those tasks were wasteful and unnecessary, Solution (A) might be in contradiction to the “More with LeSS” principle as it increases the complexity, supports this existing process instead of asking why do we need this at all. However, giving those special work items to a specialist team would make the collaboration more complex. Thus the solution (A) appeared more meaningful at that time.
Note2: In hindsight, it appears that reaching the Sprint forecast was of a high importance i.e. the “need to be predictable”. This would support the concept of “contract game”55. This concept was certainly in place in the beginning of the initial (faux) Scrum adoption however it had weakened during my presence as a coach.
The department Terra tried to establish solution (B) during the self-designing team workshop but failed, and thus solution (A) was continued.
Problems with Sprint Events
A LeSS Huge rule is that there is one product-level Sprint, not a different Sprint for each Requirement Area. It ends in one integrated whole product. Implying also the LeSS rule that there is one product-level Sprint, not a different Sprint for each Team. Each Team starts and ends the Sprint at the same time. Each Sprint results in an integrated whole product.
The entire department followed the same two-week cadence56.
Prior to the Sprint Planning part one, the POT had a short meeting to share their situation and díscuss opportunities to align57.
Sprint Planning was divided into part one and two58 in each of the RAs. Typically each of the teams sent two representatives to the Sprint Planning part one and selected several items from the PB.
Typically, each item was well refined and there were no surprises at this event. The team representatives went back to their teams for Sprint Planning part two59. The PBIs as a result of the Sprint Planning two were forecasted to the APO.
When there was a possibility to share work during sprint Planning, teams coordinated themselves.

The APO started to write the PBIs on cards in order to speed-up the Sprint planning. This method evolved and included a tracking system, so that the APO knew which team selected which item until the data was entered into the Jira tool.
The board was then installed permanently and provided a visualization of the ongoing and upcoming work in this RA. The APO did double “bookkeeping”, the master was kept on the physical boards and the data in Jira was entered afterwards.

The Sprint Review was done per RA for all teams61. A product demo was organized after each Sprint with PM&BA&CO, and other stakeholders.
The Sprint Retro were held at team level62. Small improvements were often done instantly without waiting for the retro to happen. Instead of an Overall Retro63 per RA, the department had a monthly retro for the entire department across all RAs including the functions64. A few months later, the overall Retro per RA was established.
Impediments and improvement topics were identified at the department-wide retrospective with management, POT, Scrum Masters, team representatives as well as participants from other functions. Some of the impediments were forwarded to the AGC for handling, others could be tackled by the participants. Generally, improvements were done on many areas like daily Scrums (cross team learning), cooperation PO - APOs, how to handle defects, and several communities were established.

PBR sessions were typically multi-team refinements65 in which PM&BA&CO66 participated frequently. For requirements which covered multiple RAs, the refinement was organized across several RAs.
Only in some rare cases, the end customer were invited as well following the LeSS rule that clarification is done as much as possible between the teams, customers/users and stakeholders.
Cross-team coordination was done either by team asking other teams for support informally67 and by the common Scrum of Scrums session for bugs. The central meeting appeared to be a quick way to bring issues to the teams’ attentions.
Furthermore, the APOs together with architects met daily to synchronize, discuss together with others (e.g. coaches, Head of departments) to solve issues towards a common product.
Sprint Backlog
Each Team had their own Sprint Backlog68. It was a physical board whereas at least one team wanted it to be also in Jira. The boards were nearby the teams.
Definition of Done
Already during the initial (faux) Scrum adoption, the teams agreed together with the APOs and representatives of required functions on a common Definition of Done (DoD)69. This was done in two common workshops70. The common DoD remained the same as long as I was present. Nevertheless, the department was aware that enhancing the DoD was one of the possibilities to improve71. Some of the teams did enhance their team level DoD72.
At the start of the LeSS adoption customer documentation was integrated into the teams, the teams’ DoDs were enhanced with this element.
Unit and System Testing were regarded as critical since the current setup generated long feedback cycles and communication was done awkwardly via Jira. There were significant changes going on to create the environment so that the DoD could be improved in the area of testing.
Engineering Practices
All teams integrated into one product. The department already had an automatic build system by the time the initial “Scrum” adoption started. The unit test coverage was low and many defects were found during system testing phase. System and regression tests were often done manually. The situation improved over time as more and more tests were automated.
It was one of the major efforts in the department to improve overall testing situation by increasing unit test coverage as well as significantly increasing the amount of automated tests. Coaching was provided to spread competence for Test-Driven-Development and Acceptance Test Driven Development73 across all teams (and all team members). Concrete steps (which I am not fully aware of in detail) were taken to bring the missing competencies into the teams.
However, especially for the developers who programmed in the “old” language this was a real challenge which we did not master during my time there.
Pair- and mob-programming was promoted as a way to learn to gain competence. Common coding events were held to improve code quality in general.
Requirement Handling
The ways to refine requirements changed fundamentally with the adoption of LeSS from component view towards customer centric74 splitting.
Without having the skill to split requirements in such a way it would not be possible to work independent in a structure based on RAs.
APOs, architects, Scrum Master and of course team members needed to be trained and it was a steep learning curve with many hurdles. To be capable to stay in the customer problem space by understanding the nature of the product and Requirement Area was essential and the gained understanding of how to formulate and split requirements was crucial for the success of the Initial PBR workshop.

In the case a new client (e.g. Porsche) wanted to offer vehicle insurance, all three Requirement Areas were involved. Typically Underwriting was the first area to start the work, the other RAs build logically on top of that.
The requirements had always ancestors in the PB tool (remember Jira!), which was mandatory to get some kind of information on the readiness of the product functionality as a whole.
Sometimes the PB (level 1 in the spreadsheet) contained also medium grained items which were a result of splitting bigger items, e.g., when you create a new client e.g. ‘Porsche’, you do not need all the bells and whistles which belong to underwriting in the first place.
Some functionality you need only after one year of getting a contract signed. Those features were then split up and ranked lower in the PB, by splitting the ancestor and then it was a cell-based splitting.
At this time the splitting followed mostly the treelike splitting and not the preferred cell-like splitting75 for the reason of getting started with this (for the department Terra) already radical new way of thinking. It was a method which was good enough to start the LeSS adoption, and where the relevant people could work with.
Additionally, in rare cases small PBIs did appear in the spreadsheet PB, providing a cell-like splitting. Those items were proof for the PM&BA&CO department that “agile” seems to work in regards to creating adaptability. It created a positive momentum and built trust between the departments.
Problems with Management Culture
Prior to the initial “Scrum” adoption
The typical scenario for developers, POs, architects, and managers was as follows: a person had up to three superiors for: disciplinary, functional, and project. The majority of the people came from outsourcing companies and only a smaller part were directly employed by Alpha. The employees from Alpha seldom belonged to Terra but were given to Terra on a (long-term) “loan” basis.
Here is a description of the responsibilities as witnessed by me:
- Disciplinary: This superior was responsible for salary, official sign-off for vacation, and long term development.
- Functional: This person was responsible for all issues to functional competence e.g. business analysis, programming language/domain, testing
- Project: This person gave people the actual tasks on which they should work.
Sometimes, one person was at the same time functional and project manager.
Initial “Scrum” Adoption
The functional and project dimension were removed. Instead the tasks were done partly by having self-managing teams and by a “fake PO” who was mostly a Technical Output Owner (i.o.w. still some kind of sub-project manager). The disciplinary dimension remained.
LeSS Huge adoption
The situation changed drastically. Due to the LeSS Huge structure, the APOs grew up from their earlier fake “analyst” and “director” PO role by reducing their involvement in team work. The teams increased their degree of self-managing. The disciplinary superior remained untouched for most of the people. All people who came from a strategic partner had their disciplinary superior in their home company.
It became evident that the statement “Culture follows structure” was confirmed in this case. The new culture was clearly notable.
A Few Sprints Later
Two months after this reorganization two of the three RAs needed to re-organize again since several people left the department. This was again done by volunteering in form of a self-designing team workshop where the facilitator (a Scrum Master) and the affected APOs explained the issue. Within two short and smooth rounds the issues were solved and new feature teams formed. Progress!
This first phase of the LeSS adoption ended with the Release 6.6 going live. The event still had a similar flavor as the old style of releasing with people being in the office on Saturday, management serving food and observing that the software went smoothly into production.
Yet, one week after the “release live day” while writing the first version of this report, the expected storm of defects did not come. Could the quality already have been improved? Progress!
Coaching Approach
It might be important to note, that the department did not decide to officially move towards LeSS Huge. Yet, the department learned from the faux Scrum adoption, and started to follow to a large extent the LeSS organizational design system and structures - basically without having made that conscious choice. Yet, there is a long way ahead of continuous improvement and learning.
Right away from the beginning, I76 paired up with an “internal” coach77 78.
“Somebody might get hurt”79: My coaching period ended rather abrupt after a total of 6 months. Obviously I was yet again too pushy in my approach, or the department was not ready for a real change and my views were too uncomfortable. Several junior coaches came after me (and went). More appropriate senior coaching would have been needed to continuously improve.
Epilogue
During December 2017 I had a discussion with the program manager as well as other members of the department. The program manager told that…
“Even though he was not yet happy with the throughput of new functionality, he admitted that their product quality had noticeably improved and that for the last three consecutive releases in a row, the previously expected typical spike of defects when a new release came to the market did not occur. The department moved to another building and the premises there did not support teamwork as well as the old ones. The corporate also faced some layoffs during summer 2017 and more development work was moved to India. The basic structure with the RAs were kept however some of the focus was lost. The engineering practices, and especially testing (code coverage, and automation of regression tests) had improved.”
After this point of time, I have basically lost contact with the group. Thus any statements whether the LeSS Huge adoption failed or succeeded in the longer run would be speculative.
The change from the initial “Scrum” adoption towards the LeSS Huge adoption was mind-blowing. Suddenly “things” started to happen and made sense to the people. People were happier and they liked to take on the challenges and responsibilities. Outcome was produced and the quality improved. It was an overwhelming positive experience to witness this shift in a workplace. Progress!
Acknowledgement
I like to thank Ran Nyman, who came up with the idea to use this case as a case study, for his support in this case and for his initial comments. I also like to thank ME for his permission to publish this case. Furthermore I like to thank Ran Nyman, Elad Sofer, Bas Vodde, and Craig Larman for their valuable inputs and comments.
-
Due to NDA I am not allowed to mention the company name. ↩
-
The AGC was mostly following experiment “Try… Impediments service rather than change management”. AGC did do a few crucial decisions e.g. initiating the “initial PBR” which actually triggered the LeSS Huge adoption ↩
-
Actually, a sub-project manager. ↩
-
Experiment Coordinator try/see below for avoid. ↩
-
Not following experiment “Try…Transition from component to feature teams gradually.” ↩
-
Avoid/Try…Adoption with top-down management support. ↩
-
Try… Communities. ↩
-
Try… Community for Scrum Masters. ↩
-
This approach was more “do agile” which of course should be avoided. ↩
-
I note here that some of the senior managers had a “fake Scrum” picture in their mind and wanted the SMs to be manager-coordinators. Due to coaching, we avoided this situation (Avoid…Scrum Master coordinates). ↩
-
Avoid… Scrum of Scrums being a status meeting to management. ↩
-
Avoid… Scrum of Scrums being a Scrum Master meeting. ↩
-
Try… Rotate Scrum of Scrums representatives and Avoid… Frequently rotating representatives. ↩
-
This group is described later in the chapter Organization. ↩
-
Guide: Maybe Don’t Do Scrum of Scrums. ↩
-
This should be avoided (see Avoid… Needing to ‘harden’); however since System Testing was lagging behind, there opened up a time window within which the correction of bug fixes had top priority. ↩
-
Avoid… Fake team-level “Product Backlogs.” ↩
-
See Guide: Three Adoption Principles. ↩
-
See also section Problems with Product Definition and Requirement Areas. ↩
-
I guess the reason was deeply rooted in the thinking of using external partners instead of own people. The externals would need to come with all competences required thus no training needed. ↩
-
see Guide: Initial Product Backlog Refinement. ↩
-
Note: at this starting point, the architects saw the need for some fundamental architectural changes which were not seen by the individual teams, as they went across several teams. ↩
-
See diagram on in Background section ↩
-
Note: The exact amount of teams for Product B2B2C were only known after the redesigning workshop which affected all development teams of Terra ↩
-
Source: https://en.wikipedia.org/wiki/Insurance#Insurers%27_business_model ↩
-
Unfortunally the APO candidates did not attend any CLP class, so I needed to teach the basics of the LeSS Huge framework. ↩
-
See chapter Feature Team later on in the document ↩
-
Deeper discussion happens later in the paragraph Operational Tasks. ↩
-
In the case here, the Area Backlog provided a filtered view to the one Product Backlog. ↩
-
At first there must be an insurance contract in place, before you can make either changes to it, or report an incident and want some money exchanged. ↩
-
Insurance experts will know what those are, as I do not. ↩
-
This followed pretty much the described approach of “generalizing” several smaller artifacts into one bigger one. ↩
-
Note: Sprint Backlog were almost all on the wall and not in Jira. ↩
-
See the part on Requirement Handling later on ↩
-
PM&BA&CO are not real stakeholders. LeSS rule that clarification is done as much as possible between the teams, customers/users and stakeholders. ↩
-
Source e.g. https://campey.blogspot.com/2010/09/magic-estimation.html ↩
-
See Guide “Scaling Estimation” and Experiment “Try…Estimate with story points” ↩
-
PM&BA&CO, the test manager, test tool lead, production manager, release manager, and chief architects form a dysfunctional setup which is discussed more in the chapter “Problems with the new Organizational Structure” ↩
-
As far as I know, later on both departments considered to move into the direction that the APO comes from PM&BA&CO. ↩
-
The PO worked pretty much according to the Guide “Five Relationships” and had a close cooperation with the APOs. ↩
-
See book Large-Scale Scrum More with LeSS p.135. ↩
-
See Guide: Community Work ↩
-
See Guide: Large-Group Facilitation ↩
-
See experiments: Avoid…Separating development and testing; Avoid…Test department. ↩
-
The local CuDo consisted of three experts supported by need-base only team in Ireland. ↩
-
I was not involved in the coaching of this team, so I have very limited knowledge about it ↩
-
See Guide: “Product Owner Helpers” ↩
-
See also chapter Requirement handling; Terra’s senior management did not dare to let go of the architect group See “Avoid…Separate architecture group” ↩
-
Avoid…Architecture astronauts (PowerPoint architects); ↩
-
Try…Experts participate in ongoing design workshops rather than late approval reviews ↩
-
Try…Design/architecture community of practice, team members who started to learn more about architecture joined here. ↩
-
The Product Definition could potentially expanded over time see Guide: Define Your Product and Guide: Expanding Product Definition. ↩
-
And thus causing a lot of task-switching. ↩
-
“You build it - you run it” concept. ↩
-
Avoid… Product management negotiating a “release contract” (scope & date) with R&D ↩
-
Sprint Planning on Thursday, Sprint Review & Retro, POT meeting on Wednesday. ↩
-
See LeSS rule (The Product Owner and Area Product Owners synchronize frequently. Before Sprint Planning they ensure that the Teams work on the most valuable items. After the Sprint Review, they further enable product-level adaptations.) and Guide: Product Owner Team meeting. ↩
-
See LeSS rules (Sprint Planning consists of two parts: Sprint Planning One is common for all teams, whereas Sprint Planning Two is usually done separately for each team. Do multi-team Sprint Planning Two in a shared space for closely related items.) ↩
-
See LeSS rule (Sprint Planning Two is for Teams to decide how they will do the selected items. That usually involves design and the creation of their Sprint Backlogs). ↩
-
The visualization of PBIs in Jira were pretty poor. One of the APOs realized that and did her own visualization with cards as seen “Try…Visual management for the Product or Release Backlog”. This was done in parallel to Jira and even though it did not follow the idea of the experiment to banish such tools like Jira, it was an experiment into this direction to be able to compare the differences. Furthermore the amount of fine-grained PBIs was small “Try…Maintain only a small queue of fine-grained PBIs”. ↩
-
See LeSS rule (There is one product Sprint Review; it is common for all teams. Ensure that suitable stakeholders join to contribute the informa- tion needed for effective inspection and adaptation). ↩
-
See LeSS rule (Each Team has its own Sprint Retrospective). ↩
-
See LeSS rule (An Overall Retrospective is held after the Team Retrospectives to discuss cross-team and systemwide issues and to create improve- ment experiments. In attendance are Product Owner, Scrum Masters, Team Representatives, and managers (if any)). ↩
-
See LeSS Guide: Multi-Area Reviews & Retrospectives. ↩
-
See LeSS rule (Product Backlog Refinement (PBR) is done per team for the items they will likely do in the future. Do multi-team and/or overall PBR to increase shared understanding, and exploit coordination opportunities when having closely related items or a need for broader input/learning.) ↩
-
Remembering that those were still “middlemen analysts” and this setup was dysfunctional. ↩
-
See LeSS rule (Cross-team coordination is decided by the teams. Prefer decentralized and informal coordination over centralized coordination. Emphasize Just Talk and informal networks through communicating in code, cross-team meetings, component mentors, travelers, scouts, and open spaces.) ↩
-
See LeSS rule (Each Team has its own Sprint Backlog). ↩
-
See LeSS rule (There is one Definition of Done for the whole product, common for all teams.) ↩
-
See Avoid…Definition of Done defined by quality group ↩
-
See LeSS Guide: Expanding Product Definition ↩
-
See LeSS rule: Each team can have its own stronger Definition of Done by expanding the common one. ↩
-
See Experiment: Try…Acceptance test-driven development. ↩
-
See Experiment: Try…Write customer-centric requirements. ↩
-
See: Try… Prefer cell-like splitting over treelike splitting. ↩
-
I was fully external. See Experiment: Try… External agile coaches. ↩
-
I put internal into parentheses because the person did come from a partner organization and was only here on hire. ↩
-
See Try… Internal and external coaches; even though the subject is in TDD chapter, I think it also applies to coaching in general. ↩
-
Leading Teams: Setting the Stage for Great Performances by J. Richard Hackman. ↩