Large Dutch Bank (pseudo name)
Large Dutch Bank - Our Journey Towards Agility at Scale
This case study is written by Cesario together with a Product Area Lead, a Director, an an IT Area Lead from the Large Dutch Bank. The real name of the people and the bank are left out for legal reasons.
Introduction
This article is about how we improved on the Spotify inspired model in one tribe inside a Large Dutch Bank.
Our Business Lending product is being developed by more than 20 teams spread across 3 sites. Each team contains business, IT and operations skills. In this configuration we are able to deliver valuable product increment to our customers every 2 weeks. We achieved this by adopting LeSS principles to further optimise our existing Spotify inspired way of working.
In this writing we share our story from 4 different perspectives:
- The director of the tribe.
- The consultant.
- The head of IT.
- The Product Owner of the Product Area related to all customer journeys.
Observations: Why did we do this?
Around 1.5 years ago I ( director here ) came to lead the tribe; a 500+ people group where business and IT people work together in squads to create the business lending product, and where the related customer loyalty teams are within our scope. Previously, I was involved in setting up a retail bank from scratch and in the development of mortgages solutions. During my previous job I worked intensively in tuning the agile way of working into a model for the performance organisation.
In the first few weeks I decided to spend my time observing the group.
In my observations I noticed that the teams were having fun and seemed to work in line with the purpose of their squads. The teams were autonomous and organized themselves using lots of sticky notes and standup meetings.
All seemed okay, but this was about to change as we approached our first big product release.
We delivered our product in 6 month releases. Those releases were followed up by 2 months of bug-fixing to stabilize the product so it could be released to the market. We provided lots of functionality in these releases, but not always the right solutions. The long release cycle and the bug fixing period full of surprises made it very hard for us to provide reliable market forecasts to our customers or the board.
I was determined to improve this painful release cycle. I organized various sessions with people from all parts of the tribe to come up with improvement actions. The business people would point out that the IT people were not able to deliver quality code. In turn, the IT people pointed out that the business people did not understand their customer journeys and provided wrong inputs. So we started to work with learning sessions; all people together who wanted to share views, ideas and perspectives to learn from our mistakes. This was the first big step in opening up the mindset of our people. Recognizing we all had to step in to substantially change something.
I invited my newbies (working for less than 6 months in this tribe) to share their views and observations with me. One issue they pointed out was the lack of respect between the business and IT. They also raised the question whether squads (teams) were actually working on the most important functionality to our clients and tribe, when it satisfied their individual squad purpose.
At the same time I had challenges in building a target platform for Belgium and the Netherlands, where I did not have the required capabilities present in each country, and the mindset was still very much “them vs us”. How to bring all of this together?
Helplines: Once Upon a Time…
I did not know what to do, and started looking for help. Luckily, around that time, an IT director visited our learning session, and I shared my situation with him. He pointed out that he might know someone who could help, and who even did a Go See of my teams previously; he introduced me to Cesario.
I ( consultant here ) came into contact with the Bank while giving a talk at a meetup. My talk was about programmers in large scale development. At the end of my talk, a gentleman approached me and shared with me some challenges he was seeing in his group. He later introduced himself as the director of IT in a Dutch Bank.
A couple of days later he called me. He shared that maybe I should come over and have a look at his group. This was in late 2017.
I was not really interested, so I said that I would sent a proposal later this week. He answered, “hmm, I thought Agile was about Customer Collaboration OVER Contract Negotiation?”… His response made me curious, and I decided to go over to the Bank and have a look.
So, a couple of weeks later I went over for a Go See for a couple of days.
Understanding the System Dynamics
I start many engagements with a Go See. I perform Go See sessions to show respect to the teams and leadership, and to understand how the work is working for them at the level of a larger group.
One of the things I look for are recurring events. Patterns that keep coming back over time. Why? Because patterns are often the result of the organizational structure, processes and policies people work with. And these systemic issues can probably only be addressed by improving the organizational design. Contrary to common belief, you cannot make substantial improvement on systemic issues by working exclusively on the people.
Unfortunately, I cannot be there for the duration of many months to see systemic patterns emerge over time. So instead, I rely on stories from people who work there, on personal observations, asking questions and humble inquiry to get insights into the system dynamics.
I had various conversations and workshops with the development teams and the leadership. I have observed meetings and engineering practices, did pair programming and studied backlogs to understand the work context.
With all this information I created an understanding about how the work works over time, and used that systemic understanding to make the following recommendations.
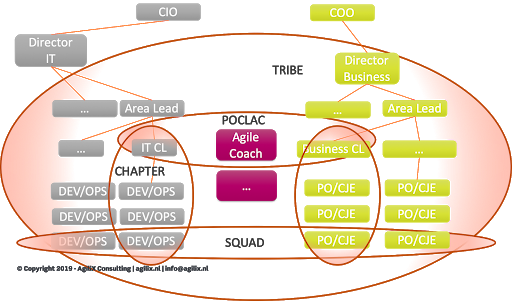
Spotify Inspired Dutch Bank Model
The product group is called a tribe. The director is from the business and is an expert in the Business Lending market. She is called the tribe lead. The teams are called squads, and include business (Customer Journey Expert), IT Engineering skills including DevOps knowledge and background. Each squad has a Product Owner (PO) who manages the squad backlog. Skills and competences development of people is the responsibility of Chapter Leads (CL). There are IT as well as business chapter leads.
Agile coaches support the tribe in working according to the standard Dutch Bank Agile way of working. The Product Owner, Chapter Lead and Agile Coach form a triad called the POCLAC. The POCLAC meets regularly to discuss problems and solutions to issues the squads might have.
The picture below depicts this organizational structure.
Local Optimization of Squads
The tribe consisted of 24 squads. Some squads were dispersed across multiple sites. Most of the squads were what we call component teams in LeSS.
Each squad had a ‘Product Owner’ who were busy with understanding requirements, backlog management, coordinating between teams and team management tasks.
The squad’s PO optimised locally. I found many examples of this. Here is one: Squad 3 needed changes in an API, and Squad 6 was planning to make those changes. Later Squad 6 decided not to make those changes and Squad 3 could not finish their work. The squads found it very hard to align with the tribe’ vision and overall product goals.
Although each squad had a clear purpose, often that purpose was not meaningful to end users. This was clear from the fact that most squads were not able to deliver end-customer value on their own. Separately, these squads were able to do only a part of a complete feature. Feature dependencies existed between most squads and ranged from around 30% to 80%. Dependencies slow down feature development, increase queues between squads, delay the feedback loop from the market, reduce agility at the tribe level , and make it harder to be predictable at the product level. This is a big problem, and it will rise exponentially when you start adding more and more component teams.
I considered their way of working an excellent implementation of Copy Paste scaling. A recurring mental model used for scaling Agile, that does not work very well.
The recurring problems of unreliable forecasts, poor focus at the tribe level and inability to react to incoming ideas are strongly related to working in such a system.
Study how the work works and optimize for what you have most of
When I studied the tribe’s overall work that was expected to be done in the coming year, I identified 3 areas of high dependencies, that for the sake of legal reasons, we call blue, grey and orange in this paper. In the blue area we found that the work required over 7 squads full time, while 3 other squads were needed regularly.
In the graphic below you see the results of the dependency study in the 24 squad tribe. The colour section of the circle indicates the percentage of a squad’s time needed to develop end-customer features in a particular area. A complete blue circle means that a squad is needed 100% of the time in the blue area..
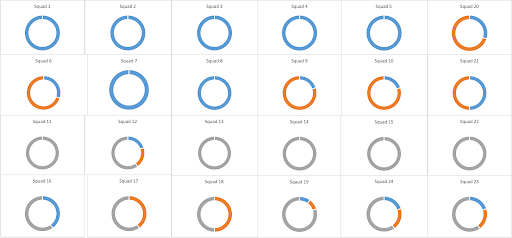
It turned out the blue squads 1, 2, 3, 4 ,5, 7 ,8, 16 and 21 should work together on the same product, because these squads are needed for almost every feature.
Single function managers and the POCLAC
The Chapter Leads acted as single function managers. For example there were IT chapter leads for specific technologies like Pega or Java. Single function managers encouraged people to grow in single-skill career paths. They did not promote mutli-skill growth of people, which is required for creating adaptive teams.
Team issues were often not discussed by the teams or with the teams directly. Instead, the issues were discussed by the Product Owner, Agile Coach and Chapter lead in POCLAC meetings. Such meetings take away ownership of the process, autonomy of decisions, and self-organization on how to do things, from the teams. Exactly the opposite effect in case you want to have continuously improving teams. It was no surprise that team ownership decreased over time and ‘POCLAC’ activities increased a lot.
Continuous Integration
Seventeen squads were working in feature branches. That is, they were working for weeks and sometimes months in isolation without integrating their code with the other squads. I found that there was no good reason for having so many branches other than “ this is the way things are done over here.”
Branching inhibits coordination and introduces delays, integration problems, reduces refactoring possibilities and causes long lasting, painful stabilisation phases full of surprises.
When there is no Continuous Integration there is poor coordination.It was no surprise that releases were recurrently painful and forecasts unpredictable. (See also Why Isn’t Your Current Approach to Scaling Agility Working?
Output driven development
The last observation I want to share is that of output driven development. Every quarter there was a Quarterly Business Review session where the squads were given Epics consisting of stories that needed to be done. Performance was tracked against a number of Epics and stories done. The goal was to deliver all the stories as promised at the beginning of a quarter. The more predictable you were the better the scores.
There are two main points to be aware of when using this approach. First, the Epics that you want done at the beginning of the quarter might not really solve the customer problem or achieve your business goals. Why? Because you might not know if your solution actually solves a customer problem. Evenmore important, you might be solving the wrong problem for your customers in the first place.
So, the goal was to deliver a set of Epics or solutions instead of achieving a specific outcome. The teams were given work to do, instead of problems to solve.
Second, with output driven development teams have no incentive to validate any of these assumptions, nor are they encouraged to do so. You run the risk of delivering a lot of solutions but for the wrong problems. The tribe used predictive planning instead of adaptive planning which is required when developing complex software.
Leadership Challenges & Organizational Design
The approach to redesigning the tribe was two-fold. First, the leadership worked on aligning their goals. What challenges need to be addressed? Second, what organizational design is needed to deal with the challenges.
Some of the main challenges were:
- How can we become more reliable as a tribe?
- How to increase focus and alignment within the tribe?
- How to deal with development across sites?
The insights we got from the Go See sessions led us in the following direction
How can we become more reliable as a tribe?
Reliability would probably improve if we had a better understanding of where the tribe was at any point in time with respect to their quarterly goals.
We concluded that transparency would increase if we would know every 2 weeks what was done, and was not done at the overall product level.
To achieve this we decided to:
- Try giving the teams problems, instead of telling them what ‘solution’ to implement.
- Try to have all squads take responsibility for a working product at the end of every Sprint. Instead of only feeling responsible for their part.
- Try to gradually eliminate all branches. All teams commit to the mainline. Use branches only for product release. This increases coordination, reduces interruptions and increases speed. (At first, the people were very surprised to even consider eliminating all branches to say the least. Doing CI with the current setup and technology seemed close to impossible.)
How to increase focus and alignment within the tribe?
Based on the Go See results we considered that focus and alignment at the tribe level would probably increase if we reduced the autonomy of the squads by asking them to reach for a common goal every Sprint.
To achieve this we decided to:
- Try to form ( the blue squads ) squads focusing on the Customer Proposition area. Have them work from the same backlog etc; this focus increased speed and adaptability.
- Try to introduce new LeSS areas for the other squads after we verified that the first area would work.
- Try to do outcome driven planning instead of output driven planning. For example, do not ask the teams to deliver ‘5 Epics’. Instead, ask them to find a solution for reducing the time to approve a loan.
- Try to integrate the code from all the squads into mainline at least 2 times a day for all squads. This reduces risks of discovering bugs late in development, or even after delivery.
How to deal with development across sites?
The squads historically had worked independently across 2 sites, but now we needed to develop a single product. At each site, people only had understanding about their specific product details, specific systems, specific customers and market dynamics. Because of all this there was plenty of duplication in systems, data and processes that needed to migrate into a single place.
So, we needed a way to further develop the product while keeping focus and maintaining reliability at the tribe level. And, we also needed to ensure that the migration of systems and data from one site to the other would keep everybody on board.
To achieve this we decided to:
- Try to work temporarily with so-called dispersed teams. This means that the squads would consist of people from both sites.
- Accept the pain of dispersed teams working in a distributed manner for the gain of growing cross tribe understanding and alignment.
So, at first, we did not use co-located teams. Instead, we used dispersed teams with people from multiple sites to accelerate learning about cross-country systems, business processes and customers.
Breaking the Rules
You can learn from the things you expect to be correct, and you can learn from doing things you expect to be incorrect. When, for example, you try something that you expect to work and it actually works, you confirm your current assumptions and values. When, on the other hand, you do something you think will not work, but it does work, you just learned that one of your assumptions, values or thinking patterns are incorrect.
The issue is that in general we prefer to avoid doing things that we expect not to work.
During this adoption we did lots of things I thought would not work,
So, we did not follow the conventional ideas on how to approach this. We broke a lot of ‘rules’:
- Did not educate everyone about LeSS, actually did not educate anyone. Instead, people learned about the way of working while doing it. By starting every session explaining why, the goal and the tactics. By providing small workshops where people could discuss real life problems they face.
- Did not use volunteering. Instead, people got invited, and volunteering was possible after experiencing the work for some sprints.
- Did not eliminate the role of team PO. Instead, teams’ POs volunteered to eliminate their own role after the first Sprint.
- Did not prepare CI system before flip. Instead, we put Continuous Integration on top of the overall backlog for months. This was now possible because we moved to a single Product Owner.
- Did not use co-located teams. Instead we used dispersed teams with BE-NL people to accelerate learning about Cross-country systems, business processes and customers.
- Did not use a Scrum Master for 1..3 teams, actually we did not use any Scrum Masters. Instead, we had 4 full time agile coaches, and brought in help during multi-team events.
- Did not use the word LeSS. Instead, focused on the challenges. After some months I mentioned that what we are doing is LeSS, and they said, “yeah we know, we are not stupid :) ”.
How do we work?
Our ( Product Owner here ) improvement Goals are:
- Improve Epic Completion ratio
- By increasing focus with 1 product backlog prioritised by the highest customer value
- Deliver value in every sprint
- By cross functional/component teams to be able to deliver shippable products
- Improve happiness and Improve/broaden skills
- By investing in skills and expertise of our people to contribute to target solutions
The first step of Dutch Bank Business Lending was having 7 squads working with one Product Owner. The squads work in the standard LeSS process. The only thing worth mentioning is the following.
All squads participate in multiple synchronous Multi-team Backlog Refinement workshops every Sprint. This increases knowledge sharing & reduces dependencies between teams. People opt-in to share what they know e.g. on Pega development.
All squads travel between countries for Sprint Review. With 2 week Sprints, this means that once a month all NL people travel to Belgium and vice versa. While we are all together we use the whole day to close the Sprint and start the next Sprint.
A typical agenda for the Sprint Review includes: Product vision, sprint goal(s), multiple demonstrations in parallel, converge to work through feedback and outlook for the next Sprints.

It was hard!
In the past, the squads worked for a long time on their own piece of the product, process or customer domain. This all changed from one day to the other and brought some great opportunities for learning to see the world from a different perspective. It also was hard for people to let go of their old habits and sub optimized improvements. Below are some of our challenges that we want to share:
Why do we need to refine. I already know what I need to do?
In the first Sprints some people thought all the multi-team refinements were a waste of time. They argued that they already know exactly what needed to be done. So why do we need to discuss this again with all these people that might not even work on it. This is not efficient and feels very wasteful.
I would say, “I understand that you already know all about this Product Backlog Item, but what about your team members?”
“How is you knowing everything while others do not, add to our goal that all squads need to be able to pick any item from the Product Backlog?” If you are an expert on topic A and all your team members are experts in topic B, what would happen if we only have topic A in our backlog? That is not what we want.
What is the plan?
Traditionally people worked with long term plans, and these plans were detailed. In this new way of working the plan for the coming quarter was detailed, but beyond that only business outcomes were planned.
I would say, “We make business impact estimations, but cannot estimate which functionality (stories) will be delivered when. The exact functionality emerges as we learn and get feedback about useage and business outcomes.”
On top of that, people were not used to being asked to solve problems, but where asked to do tasks. In this new mindset, they got the opportunity to use their skills and creativity to define beautiful solutions for our customers.
This was super hard for people in the squads, as well as for the leadership outside the tribe to understand. We are still struggling with this.
Prioritize, “why do I need to work on this?”
The squads worked from the same Product Backlog. The prioritization was based on what is of most value to the tribe. This was different in the past, where the backlog was prioritised to keep the squads busy and being locally efficient.
The mindset on local efficiency became clear during Sprint Planning. During Sprint Planning the squads can choose the Product Backlog Items they want to work on. Naturally the squads choose the item they are more comfortable with. The squads did not choose the items in order of prioritization. See the picture of the backlog after the squads had picked their items.
The picture shows the the squads choose the top and the bottom items to work on. They choose bottom lower value items over the middle higher value items.

When the coaches asked about this the squads said it was inefficient to pick up middle items because they understood the lower item better.
On many occasions, I stayed with the middle items in my hand asking the squads to pick these. Repeatedly saying that it is okay to learn and to broaden the understanding of the whole product. The goal is that any squads can pick up any item from the Product Backlog. It was hard and took a long time before the squads become comfortable with this new idea. After 1 squad had the courage to pick up these kind of items, soon other squads followed. Especially when the squads who avoided picking up items out of their expertise zone were confronted by the squads who did.
To much work for PO
In the early Sprints I was very eager and did everything to make it work; a period of long days and short nights. Answering questions, talking to lots of users, stakeholders, writing stories, epics, preparing meetings and so on. It was unbearable. This could not be the way to go forward; how could I be the PO for 7 squads?
I understood that in order to fix this, the squads needed to refine the items by themselves with the customers. I needed to focus on overall planning, work with customers and stakeholders, think about the prioritization of Epics, worry about the expected outcomes of Epics, and express the acceptance criteria from a business point of view. I needed to work more at the strategic level.
This changed when we asked people to create story maps to solve our top challenges. The solution became their plan, and this really helped to make the refinings easier and much more effective.
Ownership and Continuous Improvement
Process improvement used to be driven by the team product owners and Agile Coach. And because of their limited reach, the improvements had been mostly local to their teams. Bigger improvements across multiple squads were much harder to realize.
Introduction of the overall retrospective changed this dynamic radically. At the end of every Sprint, squad representatives and management come together to discuss problems. The squads are completely free to try improving on anything they want. This has led to numerous improvement actions like having mob-programming sessions to share knowledge, introduce all kinds of standards, change the way the refinements sessions are done, change in squads compositions and even changes to the way the overall retrospectives are done.
Key Results
We have been working in this configuration for over 6 months now, and we got some interesting results as you can see below.
- Epic Completion
- Steady increase in achieving planned outcome. From 55% to 80% in 3 quarters.
- Deliver value in every sprint
- Over 50 reviews of valuable functionality to our users / customers. In contrast to less than 10 previously.
- Improve happiness and Improve/broaden skills
- Slight increase in employee satisfaction too. From 5.85 to 6.04.
Key Insights we want to share
The key insights we think are essential to have achieved what we have now are:
- 1 shared vision, 1 goal is very powerful
- Co-creating the product vision with people over time.
- Repeating the product vision over and over again
- Understanding purpose increases intrinsic motivation.
- Reduction of dependencies between squads
- We have more autonomous squads because more teams can work on customer facing item independently.
- The work of the squads has become more meaningful because their work contributes directly to customer value.
- Create ownership, do not tell people what to do, ask them to solve problems!
- Use all the intelligence that is available in the group. Set ambitious goals and have people come up with solutions.
- Instead of making false predictions , first become more reliable.
- Multi Skilled people and cross-component feature teams increase reliability because the squads are better tuned. Measure of progress is transparent because progress is measured at the level of the feature.
- Forecasts are hard to make. But having reliable quality of the product reduce the surprises during the stabilization phase.
- Continuous integration with automated tests is essential to increase predictability.
- Working in feature teams revealed that people formerly known as heros were actually preventing others from developing.
- It is not about autonomy, but about tuning the teams.
- Working together with lots of teams might look the squads have less autonomy. But actually this is a false assumption. Autonomy is about being able to do your work without dependencies. Our configuration reduced the dependencies between the squads.
- The key insight is that autonomy is about how the squads are tuned with respect to each other. Moving all autonomous in the same direction requires constant tuning and being aware of the whole product.
We are still struggling and working hard to improve. An important difference is that improvement became everybody’s concern. It feels like the whole group is taking ownership of the process and taking initiatives to improve. This has made work challenging, meaningful and more fun.