Royal Bank of Scotland
A LeSS Adoption at RBS
How do you scale up Scrum to meet the needs of a large organisation?
That was the problem I faced when given the opportunity to lead the implementation of a vendor platform with a broad range of capabilities that would better help us serve and delight our customers.
I wanted to use Scrum as this would be in the best interest of our customers and users due in part by providing a customer focus and helping implement the platform more efficiently. However the Scrum framework purely as per the Scrum guide was not going to work at such a large scale.
I had other issues to take into account as well:
- This product supports emerging and existing OTC Derivative and Collateral Management regulatory requirements. If we are not able to release updates frequently and with confidence the delivery would be seen as a failure
- We would need multiple Scrum teams in different locations in order to get the delivery over the line.
- We needed to understand how to deal with all of the functionality that we would not be using directly but was part of the vendor package so may have been indirectly dependent upon.
- We were in an evolving organisation that deals with constant change and has to put our customers and users first.
At the same time:
- The code quality of any customisations or extensions to the vendor platform was key to help keep the cost of change low
- We had some great people managers who would also be involved and bringing them along on this journey could prove beneficial
Getting Started with Scrum
There were numerous teams focussing on product delivery agility within the organization, and I spoke to them (via the internal Scrum working group) about the the challenges they faced and the Scrum framework “compromises” they felt were needed in order work across multiple teams and locations. What was clear was that I needed courage by the bucket, some great teams, support from senior management and an approach to scaling that differed from those that had gone before.
I read the Distributed Scrum Primer which provided useful insight and then the LeSS books Scaling Lean and Agile Development: Thinking and Organizational Tools for Large-Scale Scrum and Practices for Scaling Lean and Agile Development: Large, Multisite, and Offshore Product Development with Large-Scale Scrum. It didn’t take me long to realise there was a framework that covered a lot of what I knew was imperative for a large-scale Scrum delivery and could potentially suit our needs, that being LeSS.
Organisational Structure
Our path to adopting LeSS was a gradual one, employing some systems thinking based upon evidence and anecdotes from other teams. One of the first hurdles we knew we had to jump - and jump well - was the organisational structure.
RBS is a global company and this deliver would see three different cities over two continents having to collaborate. Each continent has each own specific skillsets, the United Kingdom with predominantly analysis, project management, infrastructure and back office operations skills. India with predominantly software development, testing and release skills.
The de facto traditional structure for the delivery teams would have been something like:
- 1 Project Manager commanding and controlling:
- Business Analysts writing requirements document/s and handing them over to…
- Technical Business Analysts based in a different location who help decipher the requirements documents handed over from the Business Analysts (BAs) so that…
- Developers based in both locations could create their interpretation of what is required and deliver the components that the…
- group of Testers from the internal testing organisation would then test trying to ensure that the components were stitched together into the features and that these features match their interpretation of what the users and other stakeholders wanted
The de facto structure would have looked like something like this:
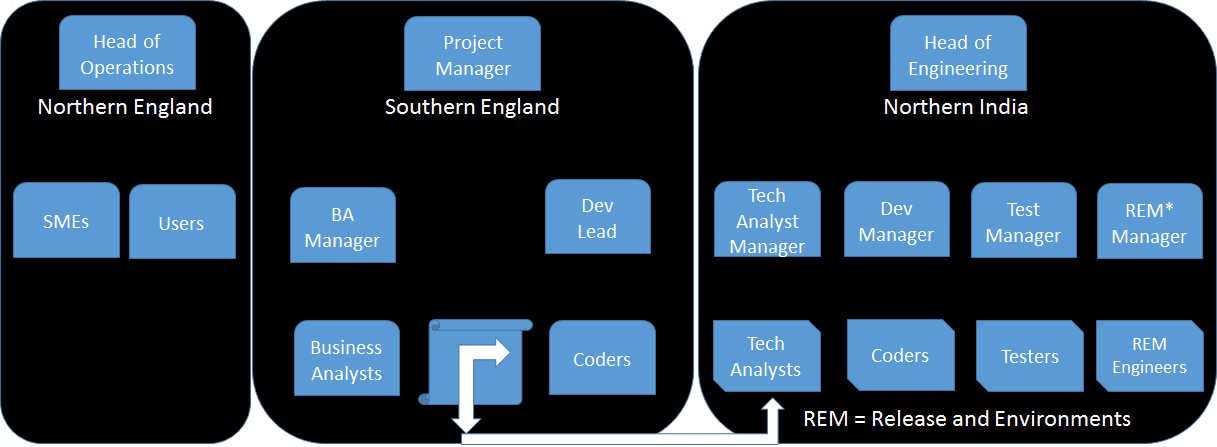
Well, I knew that was not a good idea. We’d seen that movie far too many times, and it was not pretty and rarely had a happy ending.
So, I knew what the structure should not be like, and had a vision for real cross-functional Scrum feature teams of multi-skilled team members, but people had to be convinced. One of the first major debates was…
Component or Feature Teams?
We were not going to transform to fully-blown feature teams in the short term. Why? Because to complete real customer-centric end-to-end features
- The number of dependencies on other teams and components within the organisation was high
- Their desire to change the way they deliver to a shared code (or “internal open source model”), which was our intention with our platform, was unknown
- The people available to enact this change given the timeframe, made it a step too far. This left the question how far could we go?
Common Component Group Structure
The platform was intended to be used for other business functions in the future, so we had to do everything we could to ensure that any components or features that could potentially be shared were of a good quality (meaning robust, scalable, well designed) and as a result easy to understand.
I was approached with the concept of having a common-components transitory group whose membership would be created by rotating members of feature teams, led by a non-rotating long-term component mentor (steward).
This would enable common components of the system to be delivered and understood by some members of multiple feature teams. Once their rotation time was up they would then return to their feature teams and do their best to impart any new knowledge onto them. This is what was in mind:
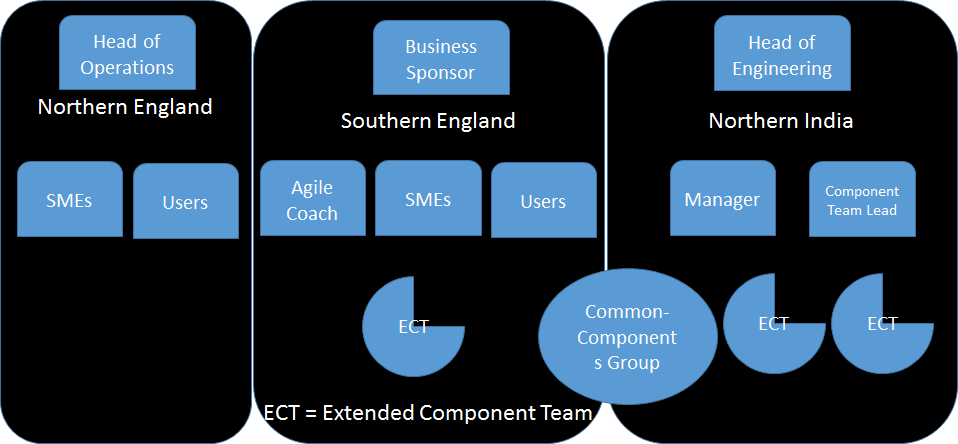
The issues with having teams organized around components are well documented and although some in the organization felt it a worthwhile experiment once the wastes, risks and ineffectiveness of this model were made clear it was agreed it would set us off on the wrong foot. We decided not to try the experiment with a common-components transitory group.
Initial Structure of new group
By focussing on using teams as the organisational building blocks, minimising waste and being cognisant of the aforementioned points the structure we put in place was so:
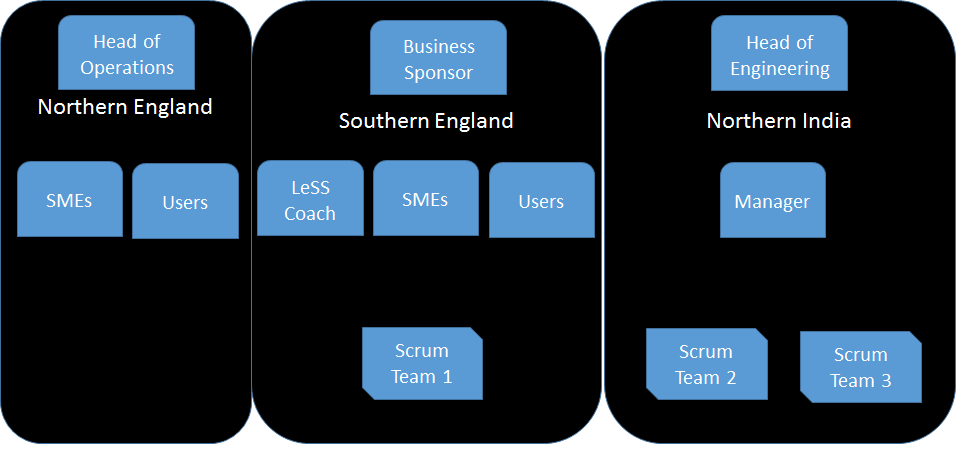
A Rolling Stone Gathers No Moss - Let’s Build Some Momentum
We were now in position where the feature teams were gelling, and multi-team design workshops to design shared components and features were the norm and increasing in effectiveness.
Multi-Team Design Workshops & Product Backlog Refinement
One pattern we have noticed is that the fewer multi-team design workshops, the longer Product Backlog refinement is, as invariably we end up undertaking the design when we should be clarifying the requirements of Product Backlog Items in preparation for upcoming Sprints.
We struggled with getting a good balance of representatives to partake in Overall Product Backlog Refinement. One of the main reasons for this was choosing to do it via video conferencing (the lesser of many evils), which made whiteboarding ideas, examples, modelling (and more importantly the conversations that are had during the modelling) much harder.
Sprint Review
The biggest challenge for the Sprint Review was keeping them short and feature focussed. Having arranged for a Team room meaning a dedicated Video Conference capability for half of each day we would always use it for the Sprint Reviews and the Reviews would be turn-based with each Team inviting feedback on what the had ‘Done’. With a large proportion of the group learning the vendor platform and the business domain as we delivered, a large number of our Sprint Reviews unfortunately turned into an opportunity for the teams to share the work they had done and they were far too technology focussed.
So what did we do?
- For some time we made time for the teams to share their work with each other prior to the Sprint Review commencing
- This provided an opportunity for the teams to provide feedback and learn from the features delivered by group overall
- We went to great lengths to get the Subject Matter Experts (ex-users of the platform being replaced) 100% allocated to helping the group
- This provided a big shot in the arm and gave the teams expert feedback on many of the nuances of the business domain and operational environment.
- The single most effective measure we took was to undertake a Systems Modelling activity as part of an Overall Retrospective
- The process of modelling, dialogue and discussion enabled everyone to understand the many variables that are in play when working on the the problem statement we set out to investigate “How do we keep Sprint Reviews feature focussed” and how there was no single route cause (as was some people’s original conclusion)
Team Retrospectives
We have found individual Team Retrospectives can be approached in very much the same was as in one-team Scrum.
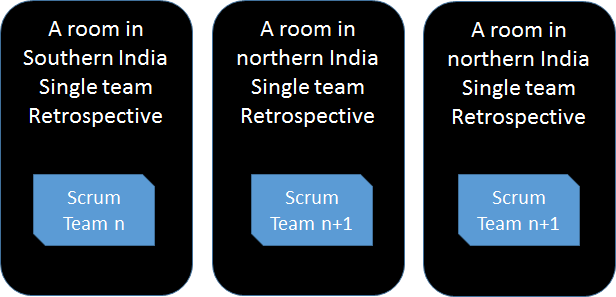
We wanted to experiment with this so we tried:
One single team Retrospective and one Multi-Team Retrospective
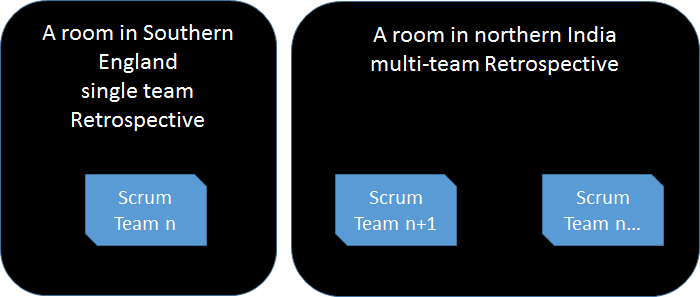
A single multi-team Retrospectives with the all Teams joining the co-located teams using video conferencing.
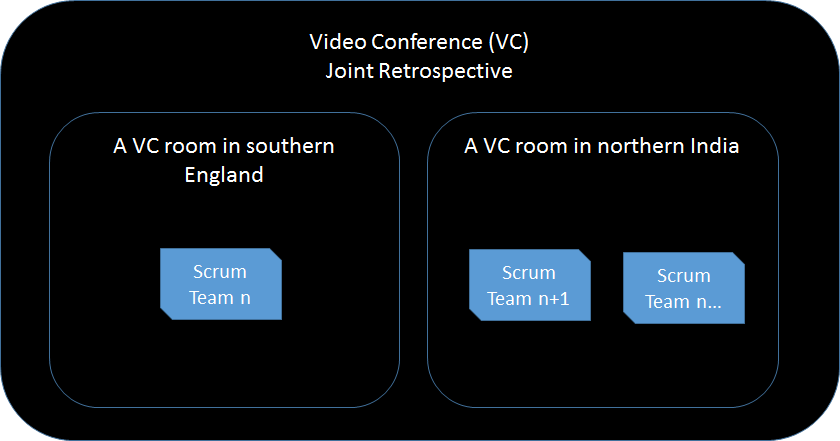
These experiments were useful, they helped us understand that they were most valuable when they were team specific and we shared the points that relate to the entire product delivery system at the…
Overall Retrospective
The Overall Retrospective is one of the few extensions to one-team Scrum that LeSS provides and as a result one of the events that we learnt the most from. The value in having this event is undeniable and by keeping the attendance to team members, the Product Owner and managers that supported the teams (and not just have it be for Scrum Masters as was some people’s temptation) a real shared understanding of the successes, failures are experiments to be executed was provided.
This event is, in my mind, imperative to real long lived success and as a result the one which we continue to work hard at to get the most learning from. I find is easiest to summarize my learning via some tips:
- Avoid it being too procedural. Facilitating a good Retrospective (and keeping it feeling fresh and invigorating) of any type (Team or Overall) can be a challenge. We have found that it is easy for it to turn into a status update and spend too much time getting too little value comparing the notes from each of the teams Retrospectives. When we could have been…
- Using modelling techniques such as Causal Loop Diagrams (System Models) promote the conversation and useful understanding of people’s perception of the Product Development system as a whole (whilst remembering that this models will never reflect the truth, the only only correct model of a system is the system itself)
- Inter-Team tensions can sometimes rise to the fore. The idea that we should enter a Retrospective knowing that each team member has truly tried their best can, easily at times, get lost when you have numerous teams. The Overall Retrospective can be an opportunity to discover and highlight these tensions, thankfully strong Scrum Mastery and facilitation has chartered us through these choppy waters.
Sprint Planning One and Two
When practicing one-team Scrum previously Sprint Planning was pretty straight forward. We had a single Sprint Planning session and did not need to differentiate between Sprint Planning One - setting the direction, the who, what and why - and Sprint Planning Two - getting into the how and the design. What becomes apparent when you begin to scale is that the Product Owner (Temporary Fake or otherwise) needs to remain effective whilst offering the teams the next Product Backlog items to be delivered,
LeSS reaffirmed the distinction between the Sprint Planning sessions and in doing so helped us remember that the Product Owner should be setting the direction through prioritisation as a core responsibility. We had multiple teams sharing one Product Owner and originally (not following the LeSS guidance) by not splitting Sprint Planning into two parts the Product Owner was getting too far into the detail which reduced collaboration and questioning by the team. This ultimately was detracting away from the team’s’ learning and slowing the building of relationships with the ultimate deciders of success or failure - the customers and users.
Daily Scrum
Try as we might to get each of the Daily Scrums happening one after each getting we have never been able to get the timings to work which has always led us to what I believed is a less than ideal implementation. So what has been tried?
- All on the phone.
- Frequently people would work from home or someone from another team in another location would ask to join. To keep a level playing field we thought we would try having everyone on the phone (rather than just a few). There was a feeling that this was not the optimum way of conducting the Daily Scrum but wanted to back up our feelings with evidence. The inability to see each other, not all having the same focal point (the physical board) and the increased opportunity to be distracted if chained to the desk by a telephone led to impersonal and ineffective synchronisation, needless to say this format did not last for long.
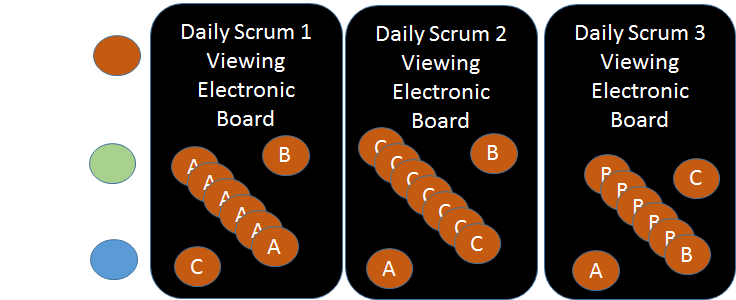
- A daily “Scrum of Scrums”Per team Daily Scrums in a Video Conference room, with one representative from each team present at each team’s Daily Scrum to share their team’s activities.
- We probably didn’t try this one for long enough but by having everyone in the VC room around a the electronic backlog it seemed to morph the Daily Scrums into more of a meeting (due in part to our unconscious minds linking the, people, furniture to more traditional meetings). It was great to have the face to face communication and what would have helped was the ability to wheel the physical boards into the room as well but our environment did not permit this which led to the approach we found worked best for us
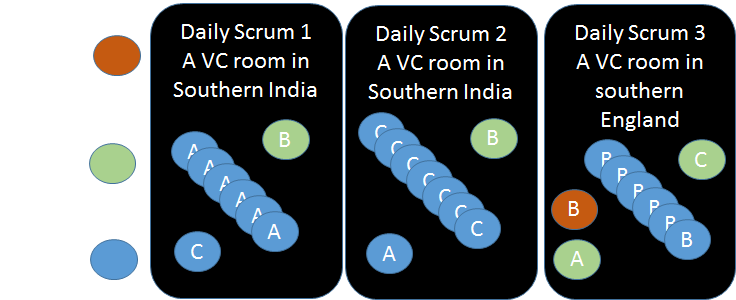
- One team around their Scrum Board with wireless headsets connected to reps from the other teams (potentially standing around their board) over VoIP
- This enabled the team to feel the heat from their information radiator and share the useful information between their and the other teams. The act of standing up around the board keeps things moving in the right direction and having the representatives on the phone provides them with a fly on the wall type experience. Remaining standing whilst the reps their news kept the feeling going and created succinct effective meetings.
What hasn’t been tried:
- Single Team Daily Scrums (no representatives from other teams)
- Why: No synchronisation between teams, leaves information on a pull only basis and even worse potentially leaving people to communicate via a tool rather than verbally (days go very quickly and when the small amount of overlap in time zones is missed communication can often result to the written word)
Product Backlog Refinement
In my opinion the greatest extension to Scrum that LeSS brings provides is the explicit definition of Product Backlog Refinement (PBR) as an event and the added structure provided to it via (optional) Overall PBR and Multi-Team PBR. We had been trying Product Backlog Refinement with all people from all teams and the Temporary Fake Product Owner as a single session. For our Temporary Fake Product Owner having it as a single session led him to get into the detail more than he should have been (when working with Product Ownership at scale this is not desirable or tenable) and for the Team made for a rather arduous block of time.
The structure suggested by LeSS of having an Overall PBR session which is short(ish) enables:
- Product direction to be communicated and for that to be supported by nominated Product Backlog Items to be refined
- The breakdown of larger items as a group, which can include some light analysis when required
- The ability to estimate as a group thus helping us to keep relative Story Points the same across teams (aka Story Point calibration, for example helping to ensure one teams 8 isn’t another team’s 3, we use a Story Point matrix to assist with this).
For us this meant 30-45 mins followed up by several single-team PBRs sessions or some Multi-Team PBR sessions with the users and Subject Matter Experts, arranged at each Team’s discretion. This enables parallel refinement and for the Temporary Fake Product Owner to be freed up to focus on defining the direction for the next product increment to be shipped.
Each Team, nervous at first, was concerned about having effective interactions with users and the potential that without the Temporary Fake Product Owner being present in all PBR sessions the speed at which they were able to discuss, update and record Product Backlog items would decrease. For me the rationale was clear, the users for us are the ultimate arbiters of success or failure, perhaps things may slow down here and there without the influence and guiding words of the Temporary Fake Product Owner but we will have confidence that we will probably being going in the right direction, rather that than going in the wrong direction a little more quickly (which is always the risk with when people’s wishes are influenced or passed through someone other than the source)
Temporary Fake Product Owner
The role of Temporary Fake Product Owner was completely new to us prior to having exposure to the LeSS organizational design system but once it had been explained to me made perfect sense. When we first started work, our first few Sprints were not the greatest, as we were learning so much due to our relative inexperience with the vendor platform and because each new team was learning to work together. Having a true Product Owner at this point probably would have scared them off!
So to make it clear that we had someone communicating the direction (by having a relationship and receiving direction from the Sponsor) but also that this person is not the true decider and not the true “owner of the product” we applied the LeSS guide of Temporary Fake Product Owner. They are temporary, as the idea is to replace them with a real owner of the product acting as the true Product Owner as soon as possible. And of course they are fake because they can’t make decisions as to the direction of the business and product; they are just a middleman communicating other’s decisions, rather than a powerful and independent owner of the product acting as product Owner.
Why was the Sponsor not the Product Owner, as one would expect in Scrum? It is well publicised that our organisation has been through some turbulent times over the past few years, and what this has resulted in is unparalleled change – change of the nature that requires our senior leadership (including the Sponsor) to focus on legacy and newly created challenges. For us this meant that our Sponsor was not able to dedicate the time to taking on the Product Owner role.
The Temporary Fake Product Owner who had been delegated adequate powers had a wealth of experience delivering the vendor platform and a healthy relationship with both the Sponsor and the teams. This enabled him to take on certain aspects of a true Product Owner having been given the power to set priority, provide final acceptance of delivered Product Backlog items (with the Users and SMEs accepting or rejecting each prior to this). Because of his background and experience within the organisation this enabled him to do a great job including the creation and maintenance of relationships between the teams, users, SMEs and stakeholders. His official job title…Delegate Product Owner.
Managers As Coaches - Capability Builders
With a firm belief that we needed to build our people’s skills it was important that we had managers who were able to focus on building the capability of the group and had an expert understanding of and were willing to go and see the work being undertaken by the teams. If we had managers who were not going to where the work is done and don’t understand the impediments people faced then there was little value in them being involved with our product. We originally had one person to play line manager to 15 people but he found hard to build the personal relationships with each of them and to coach and mentor them through their personal and professional development.
In light of this we now have line management within each of the feature teams but as much as possible line management falls outside the direct team (that is, one person is rarely in the same feature team as their line manager). These line managers duties are to coach, mentor and thus build capability within the group working with the original manager to understand and optimise the whole.
What Next?
We felt the foundations were now in place and delved deeper into the LeSS organizational design system, to make a checklist of what needed to be done:
- Ensure the customer is at the heart of what we are doing
- Test Driven Development (TDD) and Acceptance Test Driven Development (A-TDD) to help reduce queues & hand-offs of work to be verified, improve code quality, improve requirement quality, provide early feedback and enable us to move quicker.
- Drive continuous integration and have a perfection vision for continuous delivery
- Devise a method to get us to as near a production-like environment to deploy to and test upon as soon as possible.
- Get the right level of transparency with the goal being to make progress, user feedback and blockers available on a pull basis to the middle and senior managment levels.
Test First Always, Use Examples Frequently
‘Better to train them and risk they leave then don’t and risk they stay’.
Early on in the process I found an excellent cross-functional delivery manager to take on the role of Scrum Master. We set about understanding how automated acceptance testing could be achieved with a vendor platform that we were told was best suited to a screen-scraping style of automated testing.
We settled on Fitnesse, a wiki-based automated testing tool based on Fit. We discovered that by creating a little ‘glue’ between Fitnesse and the vendor application we were able to automate a large amount of functional and non-functional tests. The creation and execution of these tests immediately became part of our Definition of Done and before we knew it we were promoting A-TDD and “Specification by Example”.
To give an example: our sales team had been talking to a prospective customer and they had asked if we could split their daily cash payments in a number of different ways. When asked who from the team would be ‘writing the requirement’ I said no one individual would be doing this: instead what we would like to do is for a few team members to sit down with you and understand through examples which configurations were most likely so we could deliver what the sales team required and avoided any unnecessary waste (for example edge cases that were very unlikely or never going to happen).
Within the space of a week the team had eight scenarios specified by examples and prioritised ready for the next Sprint. These examples went straight into Fitnesse where we watched them fail, thus setting the criteria for success. By the end of Sprint the sales team had what they needed, the prospective customer was told we could do it and we had the code potentially shippable and being tested at least during every build.
Go-Live Hurdles
For us to go live there were a number of constraints that have to be met (such as Disaster Recovery, standardised user role and permission reporting,among others). Prior to go live it was agreed that we should get to as near a production-like environment as possible so that each piece of functionality could be deployed there and explored by the users.
We decided to experiment; all but one team would continue delivering user features and another would work on building out the required target deployment infrastructure (wherever possible adhering to end state go-live needs).
We found we were able to get the most of the required infrastructure in place within four two-week Sprints. We also discovered we now had one team who understood the infrastructure with work left to do. Was the experiment a success? On reflection, we should have put more effort into defining what success meant:
- How much infrastructure was enough?
- Most of the infrastructure we required could have been provided by keeping the teams as they were and coaching the team through this period. This would have resulted in more people being close to the work, greater shared understanding of the infrastructure and quite probably a better solution.
- Reuse before real use
- If the original teams had done the work they would have been using the new infrastructure as they went, instead the work was done and then handed over
- A team who felt their worth was less as they had been asked to focus on something other than customer features
- And conversely a team who felt their worth was more as they had not been asked to deal with anything but feature delivery
We learnt the following the lesson: Fake progress is no progress and instead of splitting the way we did, we were small enough that we should have dealt with it in a better way through agreeing with the Product Owner a better ordering of the work on the Product Backlog (enabling the teams to deal with infrastructure work in addition to feature delivery). Perhaps it was our level of maturity at this point which meant more traditional project thinking came into play, but as someone once said to me “it’s only a failure if you didn’t learn” and learn we certainly did.
Done and Undone Work
Creating a Definition of Done was a given, creating a list of Undone work was not at first. LeSS helped us to understand that it was just as important and useful (in our context) to be explicit about the Undone work that was between us and production.
Creating these collaboratively was the only option as far as we were concerned so we held a workshop where we introduced the concept of Undone work (having already defined a Definition of Done) to the team and spent less than an hour collating anything we felt would fall into this categorization. With this list on our Wiki it provided a path to greater agility and made it easily accessible to the world .
We gradually made our list of Undone work smaller and as a result our Definition of Done larger but we were never able to surmount some of the technical challenges provided by the chosen 3rd party platform and increasing infrastructure needs.
Continuous Improvement Towards Perfection
A recurring theme in Retrospectives was to keep the Product Backlog items as small as we could and still keep them as a user-centric feature. Why? Well every step we made lead to more learning about the vendor platform and large backlog items seemed to make the learning harder and as a result the progress harder.
In order to learn and keep moving forward, Spikes became increasingly useful. At first some of these were ‘fake Spikes’ aka analysis. So we set some ground rules for how they should be dealt with:
- Some code should be written or configuration made so there is something to see and to show how any learning can be applied
- If the team felt comfortable than any acceptance tests created whilst completing the Spike should be put into Fitnesse, if not then they are free to continue without these tests but the work would not be committed back to trunk (see below).
- As a rule of thumb what is hacked will stay on its own branch, not be merged to trunk which meant the code did not have to be production ready and our overall code base quality (we use Sonar and Squale to produce a quality rating to help us measure code quality) would not be impacted.
Coaching
As time progressed it became apparent these teams and others within the organisation were improving by striving to be agile (predominantly by using their own take on frameworks such as LeSS and Scrum) and that in order to give those teams support and expedite their journey towards high performance we formed an Agile coaching community. Our vision was to provide internal public training and build meaningful, long lasting coaching relationships. To be a member of this community you had to show that you were
- passionate about delivering value incrementally and iteratively to our customers and users
- have a desire to improve yourself,organisation and the people and teams within it
- have had some relevant experience
- volunteer to be part of it
The community is still growing with the Scrum Masters from our teams playing an active role delivering and receiving training and coaching. Over time more and more teams are looking to us to help them on the path to agility with the LeSS organizational design system and principles playing a major part.
LeSS Helped Us By…
As this tale draws to a close I want to share with you a summary of what for us were the most important learnings from our journey and how LeSS helped us:
- It told us to let each team have their own Retrospectives and then have a Overall Retrospective with team representatives and others, after.
- It provided advice and clear guidance on organisational structure and the role of the manager.
- The Product Backlog Refinement structure and suggesting Multi-team PBR unless it was clear only one team was capable of picking up that specific backlog item (for instance when we had one team working on the infrastructure)
- What didn’t help us was spending too much time trying to make and then maintain an event schedule. Not something LeSS asks and not something we really needed
- Allowed us to model, discuss, understand and improve the system as a whole.
- Understanding that the model may end up being thrown away but the conversations and debates are priceless
- My making CI, TDD, A-TDD explicit in the framework
- We had always promoted the benefits and recommended teams do this, what LeSS made clear was that in order to scale and synchronise in code these practices have to be mandated.
- Educating us about the value of one Product Backlog and one Sprint for the whole group.
- Offsetting per team “asynchronous” Sprints doesn’t work: it creates queues, waste and as a result increased cycle times. One Sprint producing one increment on the same means more focus on technical excellence and synchronising in code which was a challenge but the right thing to do
Conclusion
It is possible to scale up Scrum for multiple teams working together on one product in a large organisation and the best framework for us to do this was LeSS.There are lessons to be learned and things we could have done better, but we have had many successes and learnt a tremendous amount. By becoming quicker and more efficient in rolling out vendor platforms, and taking this approach in other parts of the business will ultimately increasingly benefit our customers.