Sita - Border Security
Border Security System: LeSS & Offshore Development
Background
Context & Customer
SITA builds products to help governments worldwide keep their borders secure. The product we were building was to automate border solution that optimises the process of travellers coming to the respective countries without compromising security. The product was being built to acquire the data of all travellers coming to the respective country, screen each of them against available watchlists and capability to take and record necessary actions for travellers flagged by the system by the various government agencies (e.g. police, immigration, etc.).
How it all Began
In 2010, SITA won a big contract to build and implement a border security system in an 18-month timeline. The system included a highly secure Data Centre and software solutions deployed on all ports of the country.
I was hired as an internal consultant to help them to adopt agile ways of working by Frank West (Product Delivery Director).
The contract between two parties was to build the entire system (Product and the Data Centre) and deploy as a big-bang approach after 18 months. But the Director of Software Development was uncomfortable with this approach as he had burnt his fingers with the big-bang delivery many times in the past. Especially so in this case as this system was highly complex and consisted of many unknowns. So he wanted to explore agile ways of working (one more time) and hired me to help him to deliver this system in an iterative, incremental, and adaptive approach.
When I joined, the organisation structure of SITA was very hierarchical and divided into functioned silos. It looked something like this:
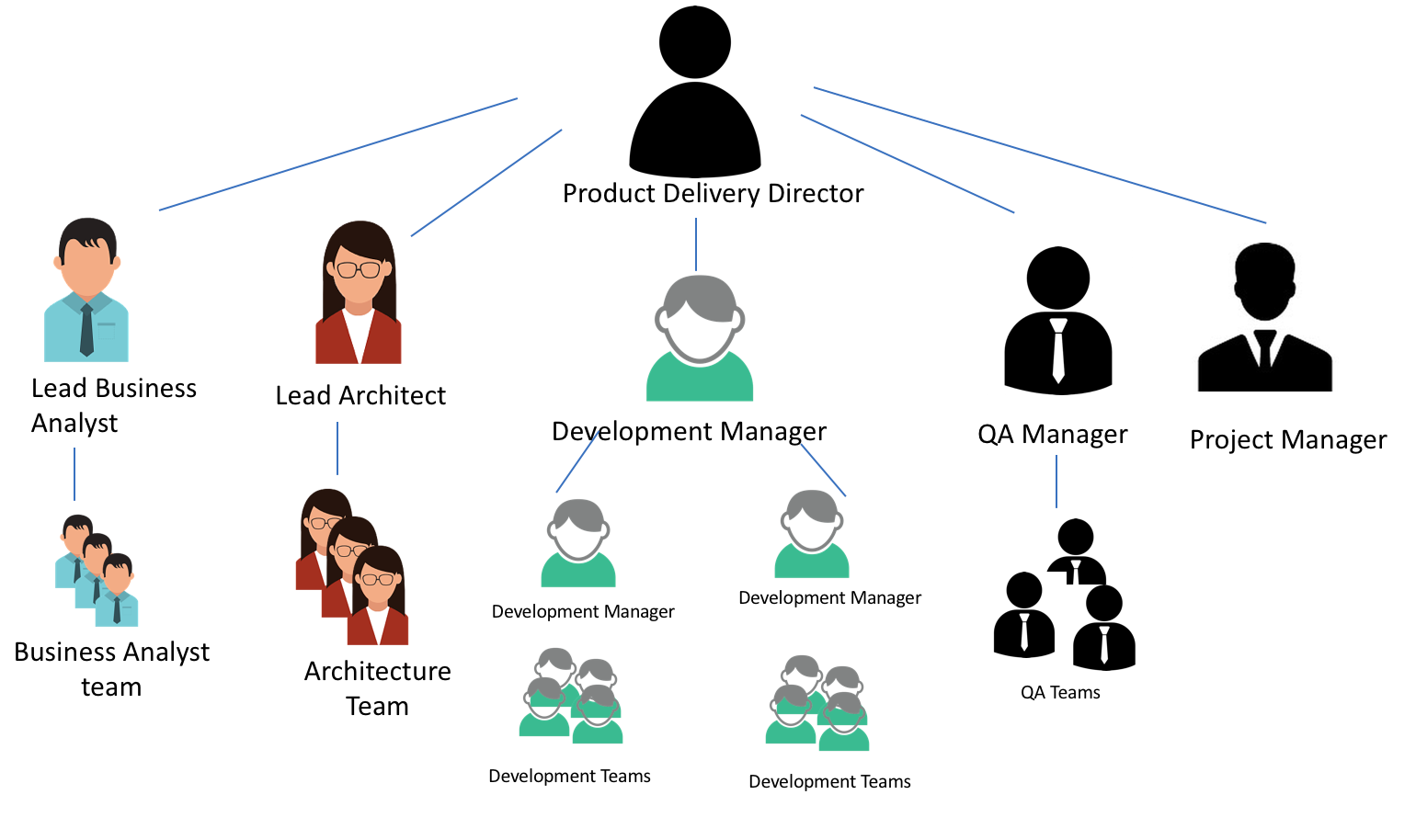
There was a similar structure in place for a Business team that mainly consisted of Programme Management, Sales Consultants and Business Solution Architects (subject matter experts).
Transition Towards Scrum (but not yet LeSS)
We started with three days of workshops on understanding the agile manifesto, its principles, and an introduction to Scrum. It was critically important we started with proper education. We wanted to make sure we created a learning organisation in the long term so we placed lots of emphasis on enabling/providing proper education with regards to more collaborative, iterative and incremental ways of working. I provided an overview of Scrum and then we discussed how we should form the development teams. After lots of discussions with development teams and management, we came up with this team structure:
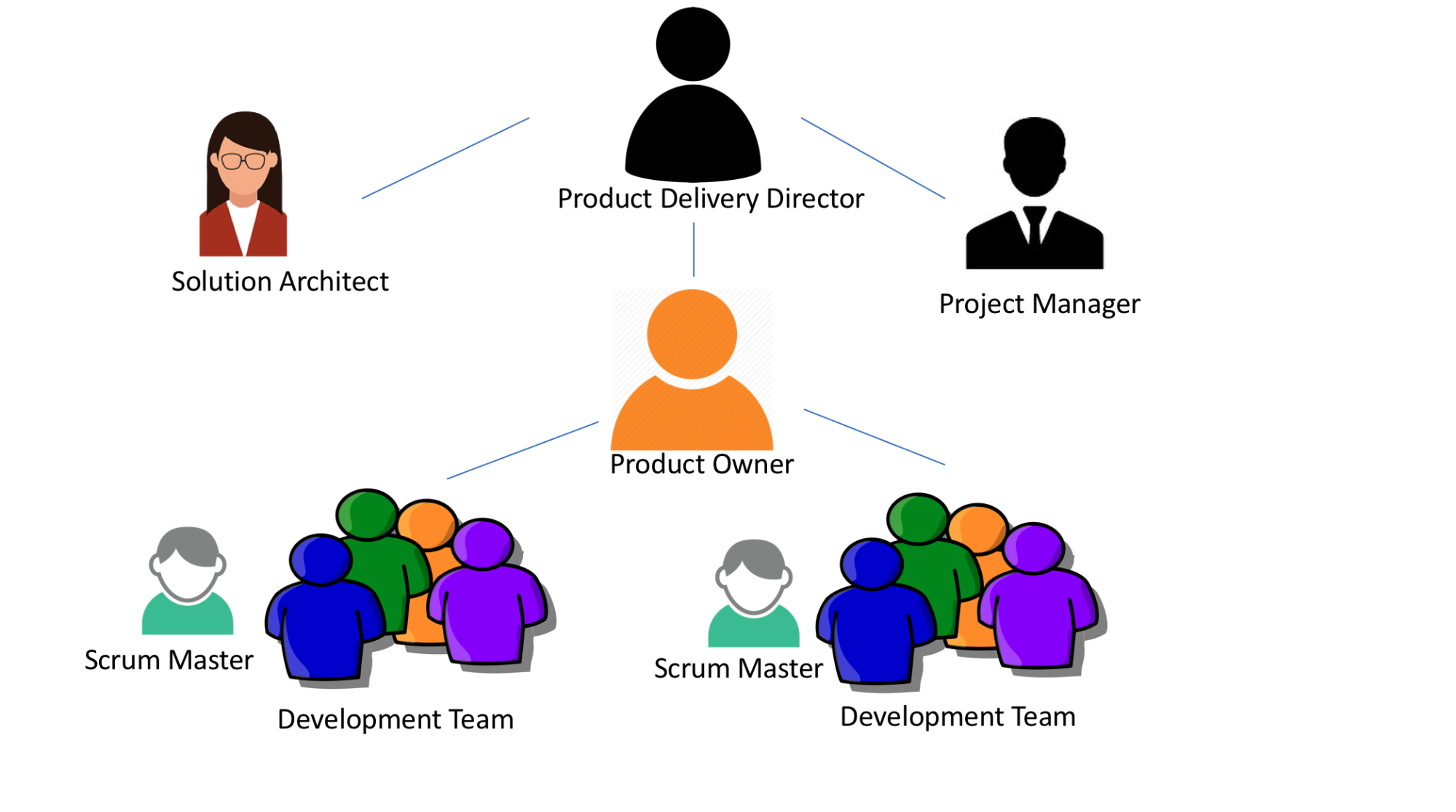
It was important for us to get the structure in place from the beginning to ensure that we create real teams keeping in mind “Culture follows structure” that is part of the 5th law of “Larman’s Laws of Organizational Behavior” so we started by creating two cross-functional Scrum teams. These teams were a mix of SME/BA, Developers, testers, and architects. Although we did form the team with a group of specialists every member of the team only had one title i.e. “developer.” There was a commitment and expectation to the team that they will not work as specialists and that the entire team will work towards the Sprint goal and pick up the next available task required to achieve the Sprint goal.
Our subject matter experts (SME) people were highly skilled domain experts in border control procedures and airline industry.
I discussed with Frank that we would not need the project manager, but he insisted on keeping two people (the project manager and the solution architect) to manage corporate reporting and some pre-sales activities. Both of them had good domain knowledge about the product that we were trying to sell to other clients.
Frank understood that we would not require both ‘roles’ in future, but he suggested, retaining these two people in their roles, for now, would help us to keep sales team in sync with what we have been building a product, so they do not start selling it as a separate ‘projects’. He asked both of them to work with the sales team, and they were also regularly involved with Product Owner to understand how our Product is growing so that they could advise our prospective clients accordingly.
We Inherited Component Teams
At a high level, the entire solution was to gather the data from the airline about each passenger and screen each of the passengers against watch lists to learn if any unwanted person is trying to visit the country. The solution was mainly divided into two very large components: Data Acquiring System (DAS) and Risk Assessment System (RAS). So teams were created to handle this structure. Team Black (each team decided to name their team after colours) was responsible for Acquiring Data, Team Green, Blue, and Purple was responsible for Risk Assessment. So we started with the component teams, which at that time looked “logical”.
From Component to Feature Team
Eventually we realised that component teams had introduced lots of unnecessary dependencies and handoffs across teams that contributed to the late and expensive feedback that was also discussed in one of our overall retrospectives. Using this feedback we started a dialog to move away from the component team and rather form feature teams to avoid unnecessary dependencies. During the dialog we also realised that we would not be able to add more teams in the future properly if we didn’t move to feature teams (managing dependencies across multiple would be a nightmare) sooner, so we started discussing the approach to create feature teams.
During the dialog the team also came up with following issues in forming a Feature team:
- Not every team has the skills and knowledge needed to implement the next-in-priority item
- The design of feature implementations across components of the architecture could become haphazard
- Feature teams could get stuck on design decisions
All these were important points so we decided to start with one feature team (“Guide: Transitioning to Feature Teams”) rather than to go big bang. We created one feature team and asked them to work on delivering features end-to-end. We followed the advice from XP to introduce a “Component Shepherd” as a mentor for each component to avoid any technical hiccups initially.
The main role of “Component Shepherd” was to mentor the feature team to make changes to the respective component and provide pros and cons while the team were making the changes. All Component Shepherds worked more like travelers (“Guide: Travelers”) so that they were free most of the time to mentor and coach multiple teams. Gradually (9-12 months) the team built up the knowledge of various components and only rarely required mentorship from the “Component Shepherd”.
Transition to LeSS
The Scrum adoption worked well for our initial two teams. Our initial product offering received good feedback from the customer which generated lots of interest with other prospective customers. Our prospective customers liked our features offering, but they also wanted lots of new features in the product. Once we had a few more customers signed up for our product, we decided to add more teams.
We didn’t have much experience in multiple teams working together so we started exploring resources available to help us. We discovered two books “Scaling Lean & Agile Development” and “Practices for Scaling Lean and Agile Development” both written by Craig Larman and Bas Vodde. They looked like the perfect guidebook for our case – especially concerning the idea of Large-Scale Scrum Framework 2 (now LeSS Huge) – as we had an expectation to grow to around 20-30 teams in the future.
These books were (and still are) so rich in providing guidelines with respect to scaling (and the challenge it throws to an organisation) that it became a guiding force for us to scale throughout our journey. We regularly started exploring ideas from these books and did lots of the “Try and Avoid…” experiments in one of these books.
Multisite Offshore Development
Despite our strong preference for co-location, we had a couple of strong organisational constraints of physical space in our current office and a need to engage with our customers who were located in different time zone. When we asked for the additional budget (mainly more teams) from the management (Executive Committee), we were asked by them to explore to work with our existing offshore partners based in India and Kiev to ensure that we have teams presence in multiple time-zone (mainly Middle-East and Australia) to engage and support our new customers.
We agreed to the challenge but with one condition that once we select a vendor, we will interview and build teams as we have done in the UK rather than a typical offshore model of accepting next available people/team (“Avoid… Outsourcers saying, Leave it to us, we do agile for you”). We also decided to have co-located teams (“Guide: Organizing Multi-Site in LeSS”) in each location to ensure that teams are learning from each other which is only possible in co-located teams. We would also bring offshore teams to the UK for at least four Sprints (“Try…Offshore group first does several iterations onshore”) .
We thought we would have a hard time from management (based on similar past experiences) but to our surprise, both our management and offshore partners agreed without any fuss before we started the offshore vendor selection process. I think they understood that in the past, onboarding of offshore teams had been painful. But as they realised that we have been delivering results with our new ways of working, we were allowed to experiment with the way we wanted to work with offshore teams.
Multisite experience within our office
We discussed multisite experiment with our teams and ensured them that it’s not going to have any impact on their job. As they were also aware that we needed more teams and had a big constraint on physical location. Although most of the people had experience working with multisite but not in the way we had been working recently (inspect and adapt). During the dialog, one of the team member asked, how does it feel like working with a multisite team in an agile environment? As none of us had any idea about working with multisite agile teams, one of the team members gave us an idea of experiencing the challenges of multisite environment before we onboard a new team at a different location. She suggested “Why not move one of the existing teams to a different floor and only communicate with the other team using phone/Skype i.e. no face-to-face communication, and see what challenges it brings. We really liked the idea ,which resonated with one of the experiments (“Try… Think multisite even when close”) from the book.
One of the team moved to a different floor for the next Sprint (luckily we had a space on that floor to accommodate the team but only for 2 weeks). Very quickly, we could see the that teams realised the challenges that multisite forces upon them even though they were in the same building and only a floor apart. Even though they had been working together for a very long time, but not able to see them physically and only communicate over phone, email, and Skype, they missed the close physical collaboration (e.g. whiteboard sessions).
This was a good experiment to create an empathy with ‘onsite’ teams for upcoming ‘offshore teams’ (that’s how they saw it in the beginning).
Offshore Partner Selection
We visited all three locations (two in India and one in Kiev) and were warmly welcomed by all of them.
All of them started with lots of Powerpoint presentations of their ‘agile’ capabilities and experience of ‘agile projects’ that they have delivered.
It was quite evident very quickly that most of their understanding of the agile ways of working was ‘wrong’. Presentation after presentations, it was clear that these groups were either bullshitting or willfully ignorant about what they termed ‘agile’. We felt that they were much more skilful in ‘creating powerpoint slides’ but delivering continuous value by delivering iterative and incremental software, not so.
We wondered among ourselves why they had such a poor understanding of the agile ways of working. After all, these companies had access to everything (training, books, hire consultants/coaches to help them etc.). I asked this question sincerely to understand it from their point of view from one of their managers. His answer was quite interesting and informative that helped us to understand how the offshore IT companies work. In summary, offshore companies don’t work as an advisory service to their clients. Their business model is often around providing bodies of people at a cheap cost and also align with the way their clients expect them to work. So they genuinely don’t invest in anything new until it becomes the mainstream and client expect them to know it well. They are often not helped by most of their clients who themselves have not learnt to adapt agile ways of working (the way it should be).
After visiting all of the offshore candidates we realised that it will be a long, painful but exciting journey with any of them. So based on our experience all of them, we proposed to start with only one of them based in Bengaluru, India. As per the experiment in the book Practices for Scaling Lean and Agile Development (“Try… Fewer sites”) we didn’t want to create unnecessary complexities by starting with multiple sites with multiple offshore partners.
We were pushed by ‘commercial department’ to use all three locations. But after we explained to them the negative impact (communication, coordination breakdown, language & cultural differences, issue with visas with one of the location etc.) of multiple sites and partners especially in an agile development environment we were allowed to use only one of the partners with a view to start using all of them in the future.
Apart from the above mentioned negative impact of multiple offshore locations, we also wanted to keep the organisation simple and carry on our journey to be agile rather than do agile. We already had a good start with Scrum and Extreme Programming engineering practices and we wanted to add more teams without adding any unnecessary overhead of coordination, offshore management etc. to remain customer-focussed. Basically we wanted to scale product development by descaling the organisation by removing any unnecessary complexity between customer and teams. We were committed to avoiding unnecessary/artificial complexities of managing multi-locations before we have experimented successfully with two locations (the UK and one more location). We were well aware the unnecessary overhead that comes with working with offshore IT companies e.g. dealing with Engagement Managers, Onsite Coordinator, offshore project managers, multiple time zones, etc.
As we ourselves were trying to simplify organisational design to remain customer-focused, we understood why the ‘commercial department’ was pushing us to use all three locations. They were pushed from the top to move any new work to offshore locations to reduce cost. They were the accountant who was behaving like an accountant (and a very good one) without understanding the overall systematic implications of their actions. In short, classic local optimization.
Our little departmental success has created a positive buzz in the entire organisation. Our success story (high-quality product, happy customer, early and continuous delivery, more business, etc.) have also reached to various people outside Product Development (e.g. HR, Commercial etc.) who were curious about what were we doing differently. We invited commercial department people to meet us and our teams so that we can explain them our ways of working. This is related to the LeSS adoption rule: “For the larger organisation beyond the product group, adopt LeSS evolutionary using Go and See to create an organisation where experimentation and improvement is the norm.”). When they visited us, they were surprised to see the visualization we had created within our department. They could easily see our Product Backlog (story map on the wall), Sprint Backlogs for each team (on whiteboards), build statistics (build status, number of defects etc.,) monitors etc. and on the floor (mostly noise of people working together). Despite being from a non-technical department, their reaction was why wouldn’t you work this way, it’s so obvious. They also offered their genuine help us to negotiate a cheaper rate with our offshore vendors if we are willing to start with 10+ teams straightaway which we declined politely and realised we have a long way to enable lean and systems thinking in our organisation. They clearly could not see the systematic impact of adding 10+ team vs 1 team. They only looked from their local optimisation goal to reduce the cost without realising that they are probably increasing the overall cost with that kind of behaviour.
One of the conditions we put with our offshore partner (before we decided to work with them) was that we were looking for a ‘long-term partnership’ and not a temporary project model (“Try… treating offshore organisation as internal partners”). What it meant, in reality:
- we would have the same ways of working (i.e. Scrum and Engineering practices from XP) and
- team formation (cross-functional and self-managed).
We also offered to help the offshore management to understand and adapt the ways of working, based on Scrum, XP and lean thinking to essentially ignore organisational boundaries. We said that we would provide a coach for 3-6 months initially to help them build and mature their understanding of lean thinking and agile ways of working. This agile coach will not be at their cost as we see this as our investment to build a long-term sustainable partnership with them.
But in return, we expected a complete transparent culture and minimal offshore hierarchical management (“Avoid… Outsourcers with top-heavy management”) from them. We also made it clear that the foundation of our partnership is built on trust (both sides). Without that, it could be a very bumpy ride that both sides will like to avoid.
They would also provide
- an open office working environment (without any cubicles and cabins) and
- each team member will have two 27” monitors.
I think with some initial discomfort (e.g. providing a team 27” monitors to the developer may create a problem in regards to some other projects happening in the same building and there being no manager in the team), they agreed but suggested to include one manager to learn the new ways of working and help in facilitating and coordinating the new working environment, which sounded reasonable to us. To our surprise, the manager was genuinely a big supporter of collaborative and transparent ways of working and was quite excited to work with us in “creating flow, after waiting for so long in a waterfall mud” (as per his own words).
So after one month of flying and multiple visits to Bengaluru, Delhi, and Kiev we had an offshore partner… but still no teams yet.
Team Selection
We provided our offshore partners guidelines (not a detailed job specifications) on skills we required for the cross-functional teams. We mainly looked for team members experienced in J2EE, SOA, JavaScript, SOLID design principles, Oracle DB, TDD, continuous integration, Jenkins, and exploratory testing. As this was our first team in Bengaluru, we wanted to ensure that we pick the team members not only based on an aptitude to learn but more importantly an attitude to learn.
We looked for people who not only had good understanding of the skills we were looking for, but a genuine curiosity to continuously learn new technologies and ways of working. However, we did not want them to only want to learn from the resources available to them (books, internet, conferences etc.) but from each other as well.
We didn’t think it would be that difficult to select a team of around 8 people but after two exhausting days of technical tests, pair programming (“Try…Interview outsourcer-programmers by programming”) and multiple interviews of 200 people, we had only selected 7 people that fitted our team selection criteria (aptitude and attitude to learn). This explained the four-year programmer problem, well described in, Practices for Scaling Lean and Agile Development book (Chapter 13, Offshore):
“Worldwide, there is a problem with the quality of programmers. They do not usually learn much useful about good programming/ design at university, because computer science professors—though brilliant and gifted in their specialties—know little of the craftsmanship of great code for real-world product development, and they certainly don’t spend time pair-programming and coaching students in any meaningful way. The professional-programming skill of professors in India and China is arguably even worse. So, in these countries especially, the average person first joins an outsourcing company with very low programming skill. It gets worse: The four-year programmer problem. After about that duration, a person expects to stop being a programmer and become a manager. Motivation is understandable—more money and status.
So there is a pool—on average—of programmers of low skill who leave the value work after just starting to achieve a modicum of skill and productivity.”
We also realised that four out of the seven selected team member only had a couple of years of experience but a great curiosity for learning, less waterfall experience and a preference to work in an agile environment. The other three people actually had an architect title who just wanted to continually code and had a desire to be hands on, probably forever. So we thought at last we had our first team but we were informed in the evening that one member couldn’t join us as he had some emergency at home and would have to relocate to Hyderabad.
Key learning from this experience
What we learnt from this experience is that an offshore company may have lots of people available but they may not have the right skills to work in an agile environment. It’s not because they are not capable but most of the offshore companies are NOT setup to work in a collaborative environment that directly reflects in the skill set of people working for them. Of course we were not under any illusion that they couldn’t learn and adapt but until the offshore companies provided the environment to foster the collaboration and their customer also truly adapts collaborative, inspect and adapt ways of thinking/working, this change will be painfully slow. Anyway, we had a team of 6 people ready to work with us.
Team Onboarding
We had an agreement that the team will spend four initial Sprints (“Try… Offshore group does first does several iterations onshore”) with us in the UK that required 2-3 weeks of visa processing time. So we thought while we were there, the team should start getting to know each other a bit more as none of them had worked together in the past. We set up a two-day workshop with them to understand the vision of the product and domain they would initially be working with (“Try… Offshore domain and vision workshop”).
Before we explained them the vision of the product, we clarified that we were looking for this team to be long-lived (“Try… Stable offshore Scrum teams”) as we had in the UK. We encouraged them to understand each other by creating three pairs. Once they chose their pair, we asked them to spend 15 minutes in a pair to know things about each other and after 15 minutes, they would have to introduce their partner to rest of the team. We didn’t prescribe how they should know or present the information and suggested to be as creative as they can to make it exciting. This exercise helped a group of six people take the first step towards becoming a team.
We explained and demonstrated the entire product and let them play with it. We asked them to perform exploratory testing and see if they could come up with any suggestions to improve the existing features. They really liked the simplicity of the user experience of the product and very quickly understood various user journeys and came up with some clarification and suggestions that our Product Owner noted down and promised to think and come back with. We also shared our wiki with them so that they can go through any particular requirements in detail to understand it better.
As mentioned earlier, the Bengaluru office already had a dedicated thick network line from our office. We made the necessary network and security changes to allow them to access of our source code repositories, build servers and other environments. We recommended the team to setup their development environment on their laptops to tease out any connectivity issues as soon as possible and also start getting familiar with the code structure and existing architecture.
Offshore teams working with onsite teams
The team from the Bengaluru arrived at our UK office after 4 weeks of initial selection, over the weekend. We arranged for them to stay close to the office so that they didn’t have to unnecessarily worry about commuting to the office. Our Sprint cycle was Wed-Tue (2 weeks Sprint) and the new team had two days to observe and discover the way we work in the UK office.
They also were unaccompanied by their manager as he was still engaged in the Bengaluru office to setup the open office environment and arranging big monitors for the team. He wanted to travel with the team but we suggested he only comes to the UK after ensuring they have the agreed office environment setup in the Bengaluru office. Travelling without a manager was a bit tricky for the team. First of all, they had never travelled together as a team (most of their ‘on-site’ experience has been mostly travelling independently and not as a team) and they often had a ‘manager’ when they arrived at an ‘on-site customer’ location to direct them. So they looked a bit overwhelmed to be exposed directly to the ‘client’.
One thing we appreciated from our offshore visits (especially in India) the genuine warmth we received when we arrived their office first time.

There was a sign for every arriving visitor, a wonderful gesture.
So we did the same for our offshore team when they arrived in the UK office. We had their name on our welcome board and we were available to welcome them when they reached to our office.
We had not hired a Scrum Master from the offshore vendor because we couldn’t find one. So we decided that we would request one of the existing Scrum Masters, Sylvie, to join the new team to help them to learn and have deep understanding of Scrum. We also paired them with an existing team so that they didn’t merely observe and learn from their ways-of-working, but on top of that, they developed the relationships at a personal level with other team members.
Sylvie arranged for an architecture workshop (“Guide: Current Architecture Workshop”) to go through the current architecture. Our Product Owner also joined this workshop and explained the various use cases one-by-one and various people from the existing teams participated in the discussion to explain the current architecture. We mainly went through the purpose of the product, its current features and drew the architecture to help them understand the different views of the system i.e. Logical, development, process and physical views for each scenario so that they could understand the overall picture of the system being built so far.
We white-boarded the discussion near the team area so that they could also retain the information for their future reference. This workshop lasted one day and it gave the team a bigger picture of the system.
At the end of the workshop, Sylvie asked for feedback from the team about the workshop and they all sounded reasonably positive. One of the members interestingly referred to the workshop as a ‘KT session’ (knowledge transfer). This was an intriguing point, and Sylvie had to clarify (repeatedly) that we wouldn’t be transferring any work to the offshore company, but the new team constituted part of our organisation as far as the work is concerned. There wouldn’t be any difference how the work was shared across teams as they were equal to any other team (“Try… Treating the offshore organisation as internal partners”). Of course we would continually provide all the support to them in their learning of various aspects of the product but they should focus on understanding and learning end-to-end (depending on which feature they work on) as they wouldn’t be working on any specific component and would be responsible (as any other team) delivering an end-to-end feature.
One of the critical aspects of our success was our transition from component teams to feature teams. We had learnt from our experience the challenges this transition brings not only to the team but on the overall organisation. So we wanted to ensure that our new team starts as feature team and not get entrapped in component team mindset (“Avoid… Sites organised by components or functions”).
The next day the team was mainly involved in working with the existing team that they had been paired and participated with in Sprint Review, Sprint Retrospective, and Overall Retrospective. We could see that they really appreciated the transparent and collaborative ways of working. They were amazed to see the empowerment and autonomy of the team and were looking forward to their first Sprint.
Normally our Sprint Planning Part 1 lasted approximately one hour as all items for the Sprint were already refined in the previous Sprint during the Backlog Refinement meeting. But, because we had a new team, the Product Owner and the existing team spent around two hours to go through the items (that had already been refined) with the new team to explain and take feedback from them.
We had a large open plan office and we kept a large space free to foster collaboration (“Guide: Coordination-Friendly Environment”). Our teams visualised our Product Backlog, Sprint Backlog (for each team), Definition of Done and current architecture in that space on large walls. So the existing team explained the goal for the next Sprint and had a dialog with the new team about what item they would like to take for their first Sprint. This was relatively surprising for the new team because they expected the item to be ‘assigned’ to them by someone. Sylvie asked the team, if they would like to work on their own or join another team to achieve the overall Sprint goal. The team member felt that they should be working with another team so that they could get all the support they needed during the Sprint (“Try… Scrum Master intent on self-organising teams”). She again clarified that although the new team would have a separate Sprint Backlog, they would be provided all the support they needed to achieve their Sprint goals. So after further dialog, both teams agreed to take the item for their Sprint Planning 2 meeting.
The Sprint Planning 2 meeting was primarily our initial design workshops (“Guide: Multi-Team Design Workshop”) to learn and agree how we were going to technically implement each item that had been selected for the Sprint. Both teams took around three hours for their Sprint Planning 2 meeting and agreed on a speculative design (extending existing class and sequence diagram) on a whiteboard (magic whiteboard) with each other for quick feedback. Team retained the whiteboard and moved it next to their sitting area to use it during the current (and future) Sprint. After an initial review and corrective actions taken based on the feedback, both teams had their Sprint Backlog up and ready on their team white-board. It was definitely a long day for the team!
Sylvie requested their feedback on both Sprint Planning sessions and shared with me and other technical coaches and we could see that they had slowly started grasping (and believing) what we had explained to them (with regards to the ways of working) while they were in Bengaluru when we chose them. One of the team members said that they had read and heard a lot of clichés about collaboration, empowerment, transparency, and safety (especially, when a client visits them), but this was the first time they had experienced something in reality. Even choosing what items they should work on during a Sprint was a shock to them as they were so used to ‘assigned’ work to them by a manager. We could clearly observe and experience the impact of an organizational system on the behaviour of the people. This reflects the LeSS guide “Culture Follows Structure”, meaning that in larger companies (though less true in very small ones) that the organizational design (structures, policies, processes, power relationships, etc) influences the mindset and behavior.
Technical Excellence in Offshore Teams
Although all of the team member were aware of technical excellence practices i.e. test driven development, continuous integration, pair programming, trunk based development, continuous delivery etc., they had not experienced the usage of it so rigorously. They realised very quickly that teams shouldn’t compromise on quality and should strongly believe in building quality in. For example, even though no one mandated pair programming they realised most of the other teams worked in pairs, so they also decided that they should pair up.
After a few days, Sylvie observed that the team would benefit from a technical coach (“Try… Experts Coach/review rather than dictating design”). Sylvie’s observation was based on the team’s writing unit test after they had written the code and also the fact that they lacked understanding of pair programming (to solve a problem together and get continuous feedback). She shared her observation with the team and offered the team the option of a technical coach to work with them to assist them to learn XP practices more effectively. She also noticed that nobody responded to her observation and there was a silence for at least 2-3 minute (although she felt they were quiet for almost 10 minutes). It was an incredibly uncomfortable situation for Sylvie and the team! She was thinking, “Why are they silent?”, and the team was thinking “Who will take a decision?”. They were not used to making decisions (as it was previously a manager’s job.).
After everyone had got uncomfortable with the silence of 2-3 minutes, one of the team members asked who would take this decision.
“What do you think?” she asked.
“Shall we discuss it with our manager once he arrives?” he replied.
“What new information manager will bring to encourage you to decide?” she asked.
“Well, he will decide. These decisions are taken by a manager,” he answered.
“Who do you think is the best suited to these decisions?” she enquired.
“Well, the manager. He knows more about the ‘project.’ We don’t want to take decisions without him being present here.” the other team member replied.
“Is this how things normally work in offshore?” she genuinely enquired.
“Hmm, yes.” all of them said virtually simultaneously.
“Ok, your manager is arriving this weekend and it’s Thursday, so let’s discuss it on Monday once he is here,” she replied to close the discussion.
After the conversation, Sylvie decided to discuss the situation with me, other Scrum Masters & the technical coaches. Therefore, she called for a quick huddle in a room and shared the conversation with all of us and asked for suggestions to handle this situation. Although it was a sensitive situation for most of us we understood a bit more about their ways of working back in the Bengaluru office. We could have easily ‘forced’ the decision on the team, but we wanted the team and the manager from offshore to genuinely understand the importance (and power) of self-organisation. We knew it was going to be a long and exciting journey with the new team. One of the Scrum Masters also nudged us that we ourselves had gone through a similar journey early in our transition, so we should have empathy for the new team. It was a powerful reminder, and we thanked her for the reminder.
On Monday, the Scrum Master and the coach had a meeting with the manager to share the conversation. The manager said that he was aware of the conversation as the team had discussed it with him when he arrived. He said it was up to us to decide how we wanted the team to work. He didn’t have a preference as there was no fixed scope or timeline. Although we had mentioned the importance of technical excellence and self-organisation for us to the manager and the offshore company during the vendor selection process, we understood those conversations can be easily forgotten after they had ‘won the contract.’ So we reminded the manager and explained our preferred ways-of-working not only for the team but also for managers. We required him to ensure (genuinely) that the team should feel empowered to be self-organised. We wanted him to take a more facilitator approach during the engagement. Not sure he understood what we meant by that, but he nodded positively.
So we had a further dialog with the team with regards to adding a technical coach. We requested the manager to explain to the team the importance of technical excellence and self-organisation and him to support the team with their decision making. He was absolutely upright in saying that he understood that these were all-new ways of working not only for the team but for him as well, so there may be some setbacks but promised to discuss everything transparently with the team. The team agreed to have a technical coach to help them learn XP practices. . The team suggested that they should try it for a couple of Sprints and have another dialog during a later team Retrospective. This was the first ever suggestion from them and possibly the first step towards becoming a self-organising team.
So we added a technical coach. The coach did not possess any particular power. The main responsibility was to work with the team on the production code (in pairs) and introduce various concepts (TDD, A-TDD, continuous integration, pair programming, design principles, etc.) to the team for long-lasting learning and focus on building quality in.
Although the team had decided to review the introduction of the technical coach after the next Sprint, they mentioned the positive impact and what they had learnt (personally) in the current Overall Retrospective itself.
The technical coach spent three Sprints before they felt that the team had grasped the main concepts and application of XP practices, and agreed to continue working on improving their skills. The coach went back to her original team, but the team knew they would be able to access her if they needed any help further.
Lesson Learnt
What we learnt from this experience is to engage with offshore management in considering decisions and assisting them to understand the rationale and importance of your decisions to sustain the change. They had a strong influence initially on the team so educating them on lean thinking and agile principles was equally important for a long lasting change.
The offshore team spent three more Sprints working onsite before they moved back to the Bengaluru office. The offshore team members developed a genuine rapport with other team members. They were more open and transparent (gradually) with other team members and it was evident in their interaction that they indeed enjoyed their stay and learning in the UK. They requested if we could ask Sylvie (the Scrum Master) to travel with them to Bengaluru for a while to maintain the support to learning, sustain change and educate offshore management on lean thinking and agile principles.
We asked Sylvie if she would be willing to embrace this opportunity to spend some time in Bengaluru to help and support. She was happy (and excited) to spend three months in Bengaluru. We also thought it would help us to recruit a Scrum Master in Bengaluru for the offshore team.
The offshore team also suggested to have a single point of contact (Onsite coordinator) at UK office to help them whenever they need any support. We asked all teams about this suggestion and someone suggested that rather than having one single point of contact for the entire team at each location, (“Avoid…Single point of contact”) each member should choose a buddy (“Try… Buddy system”). The buddies would ensure that they are reachable to each other whenever anyone need any support from their location. We asked them to self-organise and choose a buddy and within 15 minutes each offshore and onsite team members had a buddy. In fact, each offshore team member had multiple buddies as we had more people at onsite.
Working Environment in Bengaluru
When the offshore team reached to Bengaluru office, they were quite surprised to see the new open space environment that was set up for them. Each workstation had two 27” monitors, a wider deskspace for pair programming, a webcam (“Try… Seeing is believing - ubiquitous cheap video technology and video culture”) and Skype/Google talk setup and a long whiteboard to support the design workshop. We also installed a webcam in the kitchen area in the UK and break out space in the Bengaluru just to create a more fun and informal environment. There was a video conference room facility available at both locations. Although in UK it was mainly for our teams but for Bengaluru based teams it was shared with others as well so they ensured that they booked the video conference facility in advance for the first and last day of each Sprint for the next 3 months.
Initial challenges of multisite setup
As we had only five teams in total (onsite and offshore) we did not plan changes in our ways of working. We thought it should work seamlessly. But very soon we realised the challenges of working with teams at multiple locations. Although we had the webcams and conference facility available, often poor internet connectivity created lots of issues, especially during cross-team communications. Different time zones also meant that we had to adjust the timings of our Sprint Planning, Sprint Reviews and Overall Retrospective meetings.
One considerable problem we faced was using a shared svn repository hosted in the UK by Bengaluru-based teams. Even though we had a dedicated fat and fast pipe network between two locations, the team in Bengaluru often experienced slow access to svn. They discussed the issue with the UK-based team and agreed to use the svn slave replication using Apache HTTP (“httpd”) server (“Try… Continuous Integration in one repository across sites”). With Apache HTTP installed normal svn writes were transparently pushed immediately to all replicated slave repositories in Bengaluru, and normal svn checkouts or updates were directly obtained from the local slave.
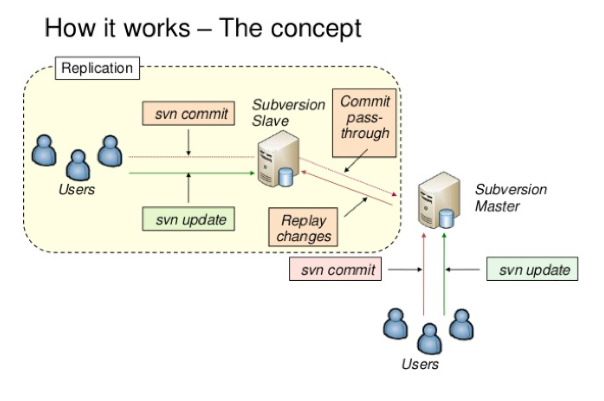
The other significant problem the team faced was the loss/slowness of internet connectivity during the Sprint Review. So the team based in Bengaluru used to record the video of the features (all user scenarios) that they built in the Sprint and used to take feedback after the video had been played. The video recording helped the team avoid unnecessary time wastage during the Sprint Review due to network failures. Once video was played to users, teams, users and the PO used to explore further the learnings and what to build next.
Adding more teams
After four months of experimentation with one multisite offshore team, we were confident that we could add more teams at the Bengaluru office. We discussed the need for adding more teams with the offshore team (and the manager). Both suggested that we should only add one team at a time as we may struggle to find the right people. They also offered to help in the process to ensure that they could filter the people sooner so that we didn’t have to go through a lengthy and painful process (like last time when we selected the first team). We took their suggestion and let them do the initial technical screening based on technical tests and initial round of interviews. This time we also focused on hiring Scrum Masters along with the team members and the offshore managers invited the external Scrum Master candidates as well. We found the process this time better and could see the fruits of our early investment in hiring our first team.
This time we actually managed to add two teams and three Scrum Masters as we had access to external candidates as well. We had one month’s lead time for external candidates, so we ensured that they had their working environment setup before they joined the team.
At the same time, we also managed to hire one more team in the UK. So now we had five teams in the UK and three teams in Bengaluru. We maintained the policy of bringing the team to the UK for the first four Sprint to educate each team towards better skills and mindset.
Introducing Requirement Areas and Area Product Owners
The key to our success in growing teams was that we didn’t deviate from Scrum (principle: Large-Scale Scrum is Scrum). We had one (and only one) Product Owner for the product (not each team) and we ensured that the right people (customer, SME and teams) were involved in Product Backlog Refinement (the LeSS rule):
“The Product Owner shouldn’t work alone on Product Backlog refinement; they are supported by the multiple Teams working directly with customers/users and other stakeholders.”
The growth of our Product (more customer and features) added many demands on our Product Owner. The Product Backlog grew to accommodate new features, and it was getting unmanageable for our Product Owner to maintain it. Although our Product Owner was not involved in detailed clarification of items but working with nine teams was getting difficult for him to manage inward and outward focus. So we decided to introduce Requirement Areas and Area Product Owners (“Try… Area Product Owners when many teams”).
Our Product Backlog was already structured keeping all customer-centric features together, so it wasn’t difficult to come up with customer-centric Requirement Areas. We added a new column in our Product Backlog so that Product Owner and Area Product Owners can filter the Product Backlog to see a particular Requirement Area.
An Area Product Owner worked with other Area Product Owners and overall Product Owner to keep the whole product focus and prioritised features within their area accordingly.
Each APO was working with around 4-5 feature teams and all teams were on the same two week Sprint
We had one Scrum Master (SM) for each team.
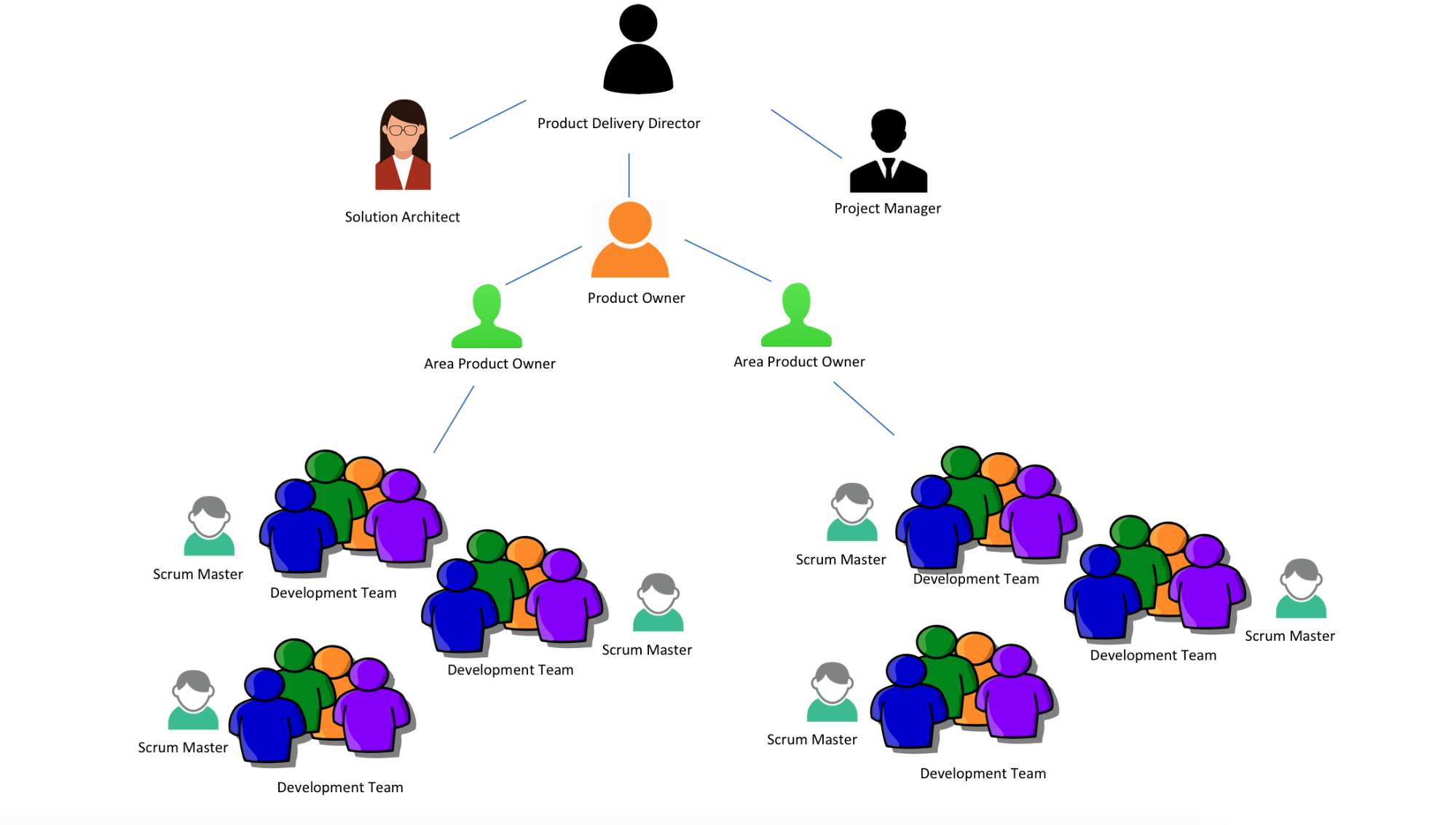
We gradually built 19 feature teams in four Requirement Areas (as the product scope grew much bigger) after 18 months.
Coordination & Events
Coordination
One of the advantages of teams sitting together at one floor was cross-team coordination. For example, Team members across the area used to join each other’s Daily Scrum, learn and share the learning with their team whenever there was a need of cross-team coordination (“Guide…Scouts”). Often for complex features/items, two teams used to work together and solve the problem together (nowadays termed as mob-programming).
If a large and complex feature required more than two teams together, one team used to take the principal responsibility (“Guide… Leading team‘) to ensure that they learn, share the learning and coordinate with any internal or external group for the required feature. For example, while working on this product, we had to use the MATIP (Mapping of Airline Traffic over Internet Protocol) to receive and transmit airline reservation and ticketing information with Amadeus and Worldspan, one team engaged with a third party to learn how to implement MATIP in our product and shared the learning with rest of the teams. They also took the responsibility to deploy the feature in production by going to Data Centre and testing it end to end there to ensure that it is working as expected as it was the first time we were using this protocol.
Overall Product Backlog Refinement
As we had around four to five teams in each area it was getting difficult to refine the Product Backlog with all teams sitting together. We chose to introduce the Overall Product Backlog Refinement meeting. This meeting happened only once a Sprint and our main purpose of this meeting was for representatives from each team to come together and perform light collaborative analysis on the items they would be taking to team Product Backlog Refinement (PBR) to get ready for the next Sprint. They also ensured that not one single team was taking all of the high priority items from the backlog, instead of spreading them across teams evenly to minimise the risk of a single team not finishing high-value items and avoid “key team” fragility (“Tip:Spread high-priority items across teams”). At the end of this meeting, all teams were well aware what items they have chosen to refine in next Sprint, not only by their team but by all teams within their area. This meeting was timeboxed for one hour per Sprint.
(Single-Team) Product Backlog Refinement
The items chosen by team representatives in the overall PBR session were refined by each team. Each refinement session was facilitated by an Area Product Owner who was used to bring the relevant SME/Customer Representatives. Each team had a dialog about three critical aspects of a user story (referred to as 3Cs by Ron Jeffries) i.e. Card, Conversation and Confirmation to ensure that item is prepared, discussed and confirmed before taking into a Sprint. Each team within an area used to have three to four PBR sessions (an hour each) for our two weeks Sprint keeping within the guideline of 5-10% of Sprint being dedicated to PBR.
Sprint Review
Our initial Sprint Reviews were between the Product Owner/ APO/ SME and teams at the end of each Sprint. As our teams matured with collaborative working we had more engaged SMEs/APOs and each item was reviewed with the Product Owner/SME as and when it got completed, but we soon realised that we were missing cross-team product progress & learnings. So we experimented with a total cross-area Sprint Review format where each area used to review (one-by-one) what and how each area has contributed to the product increment.
This review was attended by all areas (including Product Owner and Area Product Owners), business stakeholders, SME and management and generated interesting ‘product focus’ conversations. Sometimes these dialogs used to be exploratory in nature e.g. how do we improve features or integrate with other products available to improve the overall capability of the product etc., and other time to discuss the other markets we can take this product to. All these discussions led to entries in the Product Backlog for future exploration.
This format of review was very helpful for the teams to learn about the increment of whole product and learn about features that they didn’t build but was delivered part of same sprint.
Sprint Retrospective
Sprint retrospective meetings were mostly done, as expected, separately by each team but sometimes teams in an area used to do it together, especially when those teams had worked together on a feature. This helped them to have a dialog with each other to learn how cross-team coordinations can be further improved. One or two agreed actions were added to the next Sprint Backlog and tracked like any other Sprint Backlog Item.
Coaching & Continuous Improvement
There was continuous coaching provided on Scrum, technical excellence, systems thinking to the development and senior management teams to promote collaboration, self-organisation and mastery.
We had ingrained principle across the division to have “commitment before success”. What it meant for the management team was that they had to show their commitment for creating an environment of transparency, empowerment, trust and invest in systems thinking. We spent lots of time coaching the management team to understand the cause-effect for each of our actions. We also helped them to build a value stream map to understand the flow of work to identify waste and improvement areas within the system. The management team continually showed commitment to make it a success and they invested their time in understanding systems models. Although most of the prior dysfunctions were created by the management and the structure but they learnt from it and helped us to create a better future system state. They helped teams to create a safe-to-fail environment where teams can learn and share their learning across the organisation.
Impact & Conclusions
The impact of this transformation was massive to the business. We had 5-6 more customers within 24 months of the first product launch and our ROI was increased to approximately eight times more than we anticipated in the beginning.
Our key learning from this transformation was to keep things simple. Although we grew from two teams to 19 teams in 18 months, we didn’t complicated the organisation design by adding unnecessary roles to manage dependencies or for coordination. We simplified the organisation design to “descale” and continuously removed any barriers between the teams and customers for faster and real feedback.
All the feature teams continually focused on adapting technical excellence. We hired lots of good developers with an XP background and they helped existing team members to adopt A-TDD, TDD, pair programming, cross team programming, continuous integration, and continuous delivery. We moved from monthly deployment to continuous delivery in 18 months. We extended our Definition of Done to deploy each item to staging environment (not on production due to regulatory constraints) and we used feature toggling to switch features on and off until they were fully accepted by our customers. Enabling continuous delivery also helped us with lots of quick experimentation by using multivariate testing, That enabled us to ensure that we are gathering data before committing to bigger features.
Our offshore vendor adapted and embraced our ways of working and all of our teams in Bengaluru enjoyed it. For most of the people it was not only a career-defining moment but for some a life-changing moment. None of them wanted to go back to the old ways of working, so they continually committed to continuous learning to improve their skills. The offshore manager told us that there was a different positive buzz about this ‘project’ within their company. Their employees even requested to work on this! Offshore vendor claimed that their attrition rate for our teams was only around 8% in comparison to 20% in Indian offshore market.