TomCommerce
(TomCommerce is a fictious name as the case involved a 3rd party who didn’t want the name to be published)
LeSS Product Development at TomCommerce
Context
In 2014 I completed an engagement working with TomCommerce, a large e-commerce organisation. It was part of their overall business strategy to dramatically increase the percentage of revenue taken through digital channels.
The product on which I was asked to focus was an e-commerce system which was already in use throughout Europe. The complexity came from having to integrate with multiple suppliers and payment providers for each market.
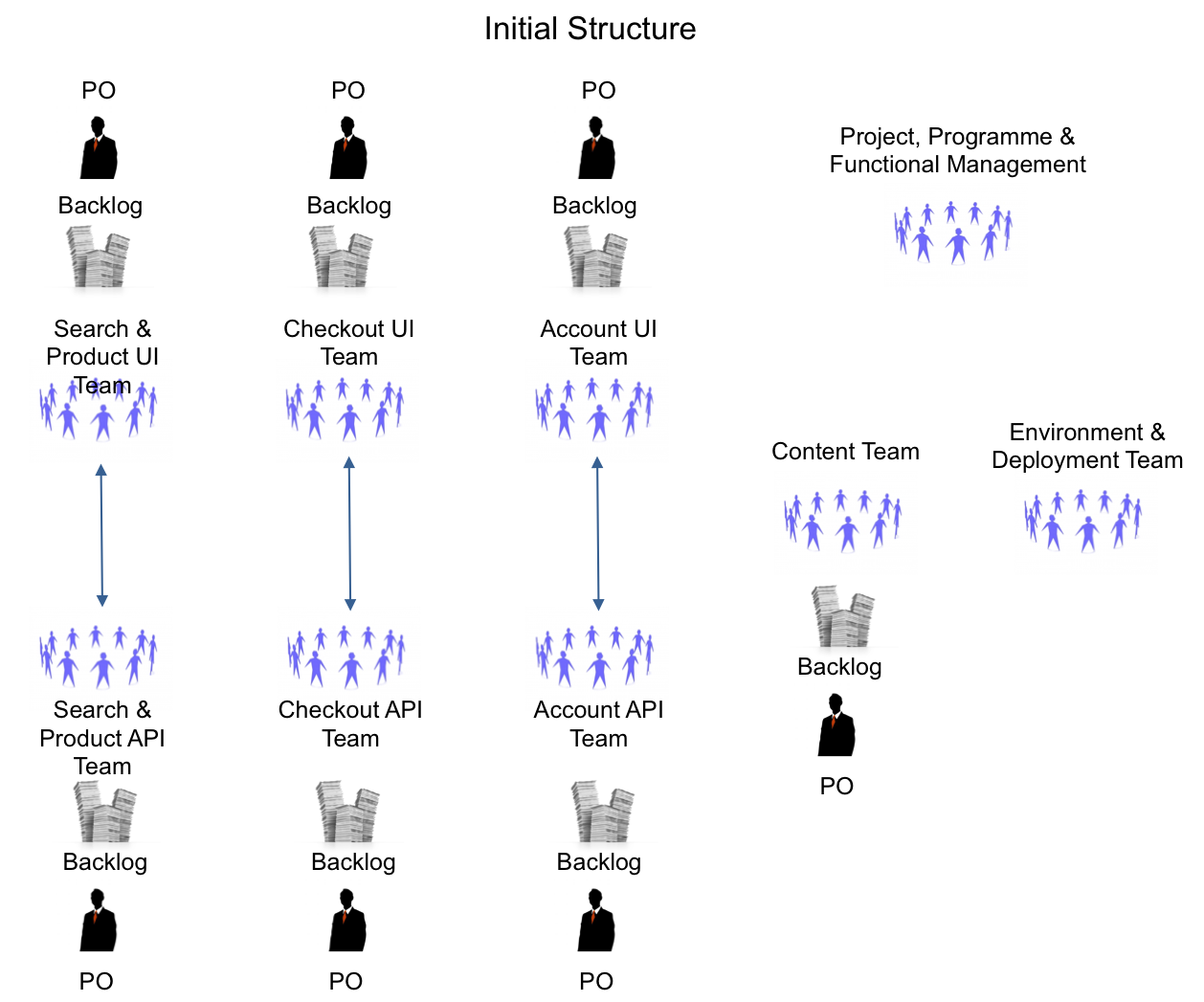
The initial-state ‘e-commerce Team’ was made up of 7 component teams, (so-called) Product Owners, and some functional specialists (such as in analysts, testers and so-called “functional managers”; though they did not manage anyone) that were outside of teams. There were also people who did manual testing, located at a different site than the majority of component teams.
There were also some project and program managers that worked with the stakeholders to represented so-called ‘Tech’ in scope negotiations (the contract game), co-ordinated work across component teams, provided updates to management and generally pressured the teams to deliver faster against commitments made from above.
In total, there were about 80 people.
The Product (Management) Group sat outside of what was called the ‘Technology Group’ and collaboration was limited. The head of the Product Group very rarely got involved and just let the various product managers work with the business analysts associated with the component teams.
The analysts maintained a different so-called “Product” Backlog for each team.
The teams collectively worked on large batches of features. Each batch was called a ‘project’ and was generally delivered within 15 to 18 weeks, after a long and painful integration effort.
Sources of Dissatisfaction
Upon arrival with the client, we took some time to understand the organisation and how things were currently functioning. At this stage, I am generally keen to talk to as many people as possible covering all levels of the organisation. I embedded myself on a team to observe what was happening on the ground. It soon became clear that there were sources of dissatisfaction both internal and external to the teams. The main issues were:
- Under-delivering on promises (made by Project Managers).
- Inter-team dependencies and queues.
- Low morale within the teams.
- Teams that were very removed from the customer.
- No view of the whole product.
- Low quality / instability of the platform.
- Lack of transparency around Sprints and the releases.
- Lack of communication across sites.
- No time for technical / architectural improvements.
- Unreliable and manual deployments and testing processes.
At the individual team level, people went through the superficial motions of Scrum, but with vital elements missing. It was classic ScrumBut. The Contract Game was still being played, with fake “Product Owners” that were really just component managers pushing the teams to complete the imposed scope-and-date “commitments.” There weren’t real self-managing teams with independent autonomy and the free ability to decide how much work to take on. The people weren’t multi-skilled continuously-learning “product developers”; rather, each had a single speciality, so that there were subteams in each team, creating mini-waterfalls. And there wasn’t a mindset or practice of deep empirical process control; rather, it was “follow the established plans and processes.”
Each team had a (fake) “Product” Backlog and related (fake) “Product Owner” of their own component’s technical tasks, so that these backlogs did not contain real end-to-end customer requirements, but decomposed component-level work. And because of these multiple backlogs and owners, there was very low overall transparency at the real product level.
Other missing elements? Well-educated and dedicated Scrum Masters and good technical practices. Sprints certainly did not result in a potentially shippable product increment. This was only achieved right at the end of the ‘project’ after a long, and very painful integration and testing exercise.
Project and Programme managers made commitments on time and scope and pushed the development teams to meet these unrealistic expectations. They then set about micro-managing the work leaving little or no room for autonomy at the team level.
And of top of all this, there was little coordination or ability to coordinate, given the complexity of the structure.
In short, it was a typical pretend-agile large-scale group where not much had changed except the labels.
The result of the above was very demotivated teams, working in silos with little communication and coordination, a low quality platform, no visibility on progress, infrequent and unreliable releases that did not focus on the customer, and frustration throughout the organisation at the situation. They understood the need to improve in order to more successfully serve their customers.
Transition to LeSS
Having worked on many enterprise Agile transformations, I am firmly of the opinion that there is no one detailed-defined model or framework that works in all contexts. This is true both at the team and scaled level. Scrum works because it is a minimalist framework rooted in empirical process control, with almost no definition of how to specifically work, but with strong mechanisms for transparency and adaptation. Teams can then add whatever else they need to be successful based on their unique context. The scaled version of Scrum is Large-Scale Scrum (LeSS). It stays true to the spirit of empiricism and provides a minimalist scaling framework that can evolve to suit almost any context. Having tried and tested many experiments in Craig Larman and Bas Vodde’s books on LeSS, I was confident that most would also be appropriate on this engagement.
We kicked off by educating everyone. It is vitally important that everyone is on the same page to begin with; including managers. We started with some of the pain-points that had been identified, and then covered Scrum and some of the core ideas and principles in LeSS. We showed how we hoped to resolve some of the issues that had been raised with real Scrum and the LeSS organizational design system.
We then set about making a few changes to the structure of the product group. These are detailed in the next section. This change included an accountable executive to own the changes. I have found that there is a much greater chance of success when the change is driven internally. I worked with this leader to guide him through the change, what outcomes we wanted, and how we might get there. An important part of that was being able to demonstrate success. We identified metrics such as value delivered, cycle time, escaped defects, various code-quality metrics, and a happiness index to track our progress.
We supported the group with coaching at all levels. This covered LeSS and Agile principles, modern engineering practices, and product management.
Structure Changes
The structural changes, made at the start, were probably the biggest change we made. Component teams were unable to deliver end-to-end working software and were hit with external dependencies and queuing hell. See the ‘Initial Structure’ picture:
What we implemented, initially, was ‘New Structure v1’ as illustrated here:
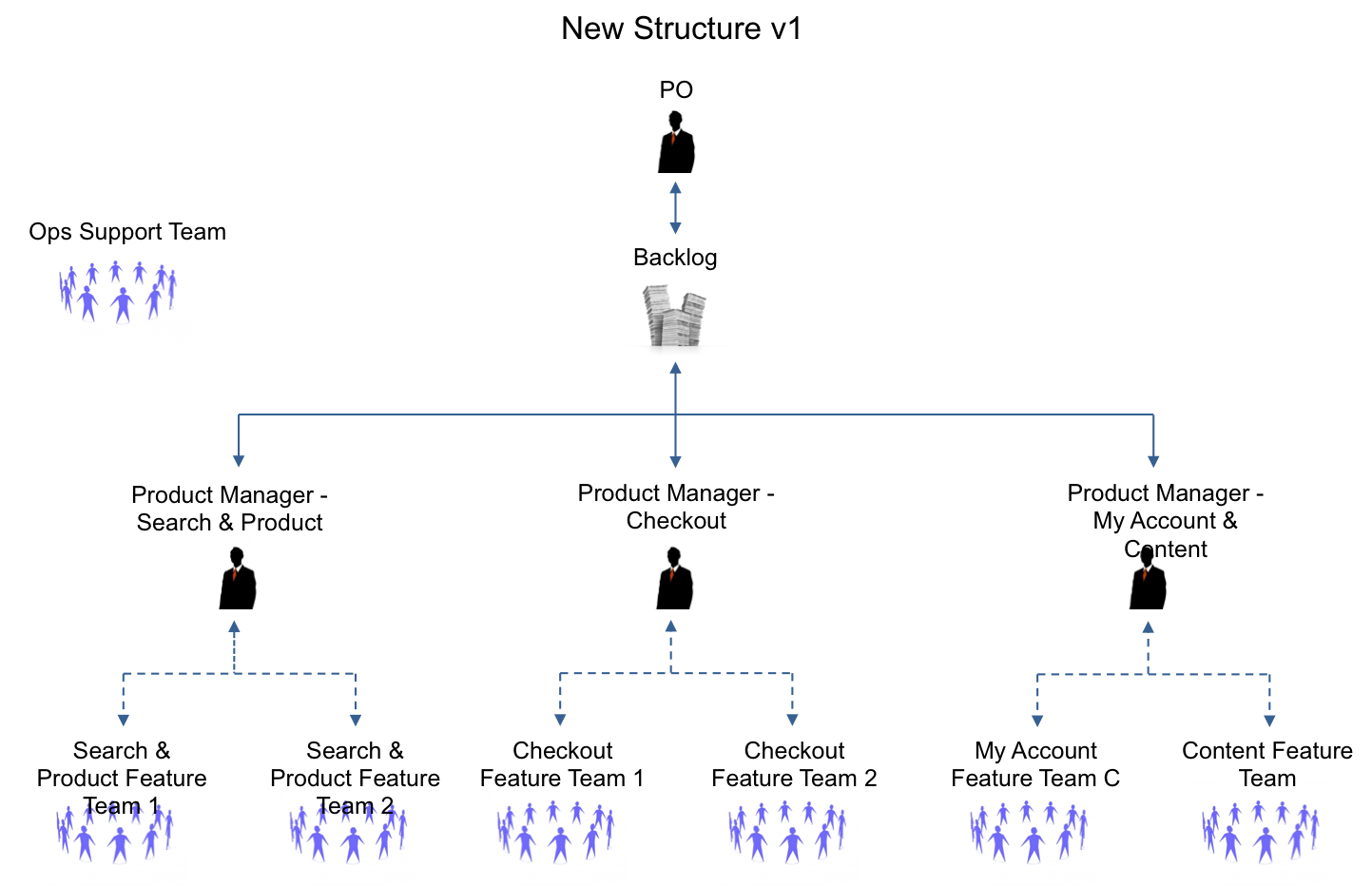
This involved one Product Backlog shared by all the teams working on the one product, and one customer-focussed, strategic Product Owner, supported by three Product Managers; one for each area of the product: Search, Checkout and Account. The Product Managers worked directly with the teams to get the features created ready for implementation.
The second (and bigger) change was the move from component teams to feature teams. There was a surprising amount of resistance to this initially, though I know in retrospect that this is in fact predictable due to widespread local-optimization and silo thinking. Inspired by previous LeSS case studies, we recommended and introduced a self-designing teams activity where people re-organized into new feature teams. People wanted to stay within their product functional-area (such as search), so we kept that as a constraint on the scope of the teams’ redesign. We encouraged API teams to join with UI teams to form multiple small, cross-functional and cross-component feature teams. We mitigated the fear of a loss of component groups by encouraging the formation of communities of practice across many areas; technical and non-technical.
Another big change was the elimination of dispersed teams (members of one team in different locations). There was one team at another site, but they were now a co-located feature team.
The advice was for the “functional managers” (separate functional specialists) to move into Development teams, but the HR department was keen to keep the role. We did, however, keep project, programme, and functional managers away from day-to-day delivery activities which turned out to be an acceptable compromise. They initially spent their time on HR issues and updating various stakeholders, but the need for this soon vanished as we introduced greater transparency and collaborative planning.
For some time, there was still a separate operations support group because of major weaknesses. However, we soon embedded the operations capability in the regular feature teams a few Sprints later, realising the DevOps goal. See the ‘New Structure v2’ picture:
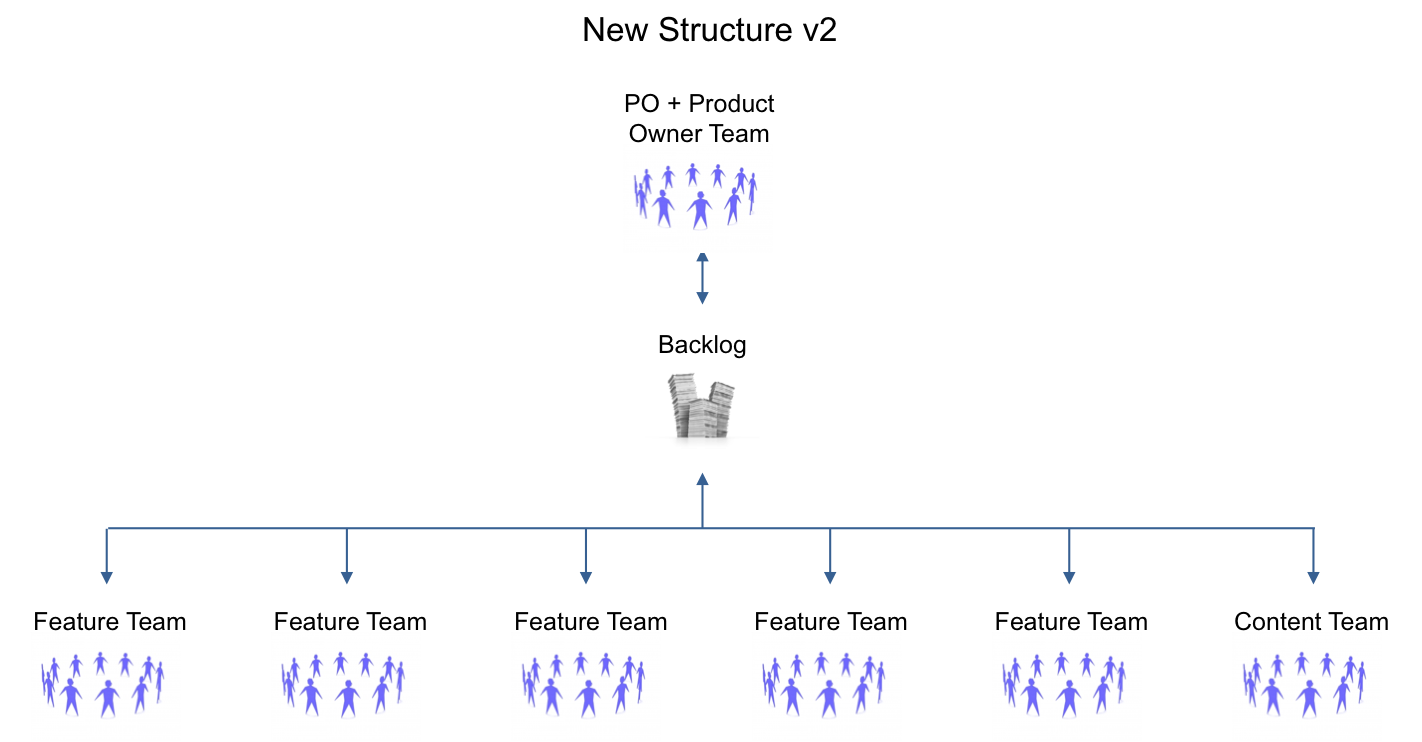
Although the new feature teams originally self-designed around the comfortable familiarity within one small speciality area, we eliminated the constraint that teams could only take items for one area. Rather, a team could in theory take features from any area in the one shared Product Backlog. And we encouraged that. This had a massive impact on spreading learning and eliminating bottlenecks when high-value work was not evenly distributes across the areas.
Role Changes
The role changes were less dramatic, but equally impactful. Managers facilitated learning and helped to resolve issues rather than assigning, and tracking, work. Team members took on more responsibility for defining and delivering valuable features.
The Product Owner took on the role of seeing the whole product, ordering the single backlog and focussing on the customers. Aiding him, were the rest of the Product Group Product Managers who were area subject matter experts. But they no longer created super-detailed requirements disguised as fake ‘user stories’. They worked closely with the teams who took on much more of the responsibility for understanding what the customer wanted. All other dedicated roles were absorbed into the teams.
Strong, dedicated Scrum Masters were introduced to coach and develop the teams and help to improve the processes. We were able to coach some internal people who showed an interest and seemed to have the right attributes for the role, but for the organisational coaching part of the role, we recruited more seasoned candidates.
With no Project Managers to coordinate the work, teams began to do it themselves. Scrum Masters deliberately did not take on this role.
LeSS Meetings
The coordination between the 6 feature teams was handled using a number of techniques:
The build and deployment process was automated which enabled the teams to move towards continuous integration (CI). Initially, we used an intermediate step of using short-lived feature branches. This was a huge improvement but, in hindsight, we should have moved straight to ‘true’ CI, eliminating the delay that comes from working on separate branches. Having code checked out for 2-3 days was still causing merge issues; albeit significantly smaller ones than before. Once we began developing on the “head of trunk” and abandoned branches, we saw the state of the product vastly improve and stay much closer to shippable throughout the sprint.
We used several recommended LeSS ideas for coordination meetings. There was one combined Sprint Planning One and we also did an overall Product Backlog Refinement (PBR) meeting.
Overall PBR included one person from each team (not the Scrum Master) This of course increased visibility of upcoming items to be delivered. Unfortunately, we did not get the Product Owner at these meetings, as recommended by LeSS, but they were attended by supporting Product Managers who knew their functional areas.
Scrum-of-Scrum meetings were initially scheduled, but were dropped after a few Sprints because in fact there wasn’t much need for cross-team coordination because there was a real feature team structure of teams that could do all work end-to-end without dependency on other teams. That’s an important insight: the need for coordination between teams can be a sign of a self-inflicted wound due to component teams and private code. Feature teams and internal open source reduce coordination problems, or shift more of the effort to “coordinating in code”.
Small coordination and design conversations between feature teams happened informally, which was easily possible since most of the teams were co-located.
One Sprint Review was an energising event and was very well attended.
I now believe that the LeSS Overall Sprint Retrospective would also have added value in addition to the regular team-level Retrospectives, but we did not learn about an Overall Retrospective at that time. It would have been a great forum to address issues affecting multiple teams.
There were also some cross-team communities of practice (including architecture, business analysis and testing; for some reason, the Scrum Master CoP never got off the ground.), and related community meetings. These really made people more comfortable with moving to true feature teams and allowed people who specialised in similar skills to get together and share learning and create standards.
Coaching and Continuous Improvement
In support of the on-going improvements of the group, we provided continued coaching in all areas. The Definition of Done was strengthened to include more test automation and performance and load testing. A more sophisticated deployment pipeline gave the capability for daily deployments, although the group have not yet exploited that. Technical practices were improved, Agile values and principles were spread and teams began to take ownership of their processes. Visualisation and effective queue management lead to limiting work-in-progress, strengthening feedback loops, and reducing cycle time.
We helped the Product Group to always keep the customer in mind and to use split testing (A/B testing) to test the impact of all new features. The product strategy was made clear to all through vision boards and story maps helped everyone to understand the whole product at a glance. The ordering of backlog items moved from subjective methods to a cost of delay model; and subsequently cost of delay divided by duration (CD3). This made ordering much easier as we could make visible how much delaying a feature was costing the organisation. This had the added advantage of encouraging ever shorter release cycles. Teams got involved earlier and more often than not, fleshed out the details of the items. They also tracked the features subsequent to their release to measure the customer impact. This brought the teams closer to the customer, allowing them to much better understand their behaviour and to create more relevant product backlog items.
The culture of continuous improvement was settling in. Empirical process control was at the heart of everything. Eventually, we had a enough leaders to take over from the day-to-day role we had been playing.
Impact
The impact here was dramatic. After 9 months, the teams were working very well together. There was a clear product strategy, the teams were aware of it, it was focused on delivering customer value and the conversion rates were reflecting that. A significant increase in the number of people spending money was down to a better understanding the customers’ needs and the ability to swiftly respond to the rapidly changing market.
Teams were, after some teething problems, delivering working software every 2 weeks. Deployments were no longer manual and error-prone. Quality and stability were orders of magnitude better. Releases went from every 15 to 18 weeks to every 2 to 4 weeks. The stakeholders always knew what was being delivered and the status of the release. This allowed for better planning all around. The contract game naturally came to an end as the shorter release cycles led to releases that were less overloaded.
The teams got better and better at coordinating the work. They actively identified areas for improvement and adapted the processes to work for them.
Engagement, morale, ownership and commitment were all heading in the right direction. As I generally find, these things increase with ownership.
LeSS provided a simple framework to allow and encourage these improvements in this large-scale group, and my confidence that the LeSS experiments would work was richly rewarded.