(Originally published by Lv Yi on June 23, 2019)
In this article, we shall look at the organization structure made of specialized feature teams, explore the dynamics around their backlogs, and then analyze the impact on agility and find levers to optimize for agility.
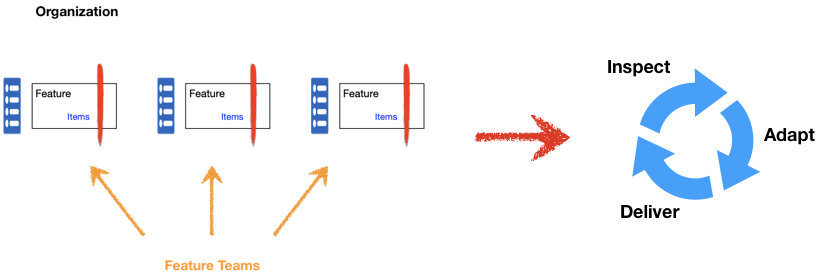
A feature team is responsible for delivering customer value from end to end. There is only one backlog associated with value delivery, i.e. the whole team shares the work and has one priority. In an organization, however, there are usually multiple feature teams, each having their own backlog. They are responsible for different customer domains, and that is why they are called specialized feature teams. Their backlogs contain mostly independent work.
Let’s still ask the question of why having multiple backlogs for multiple feature teams. The answer again lies in efficiency thinking.
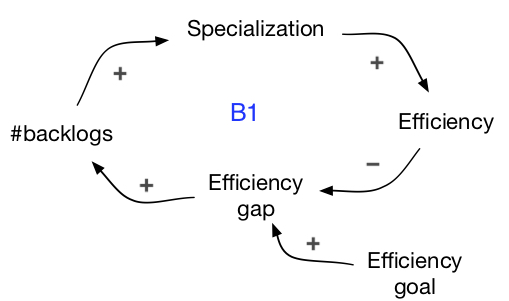
B1-loop: specialization for efficiency
This is the same loop as the one we have seen in the structure made of functional and component teams. There is an explicit or implicit efficiency goal. This causes an efficiency gap, leading to more backlogs, more specialization, higher efficiency, which reduces the gap.
With feature teams there is a different type of specialization. Instead of specializing in a function or a component, a feature team specializes in a customer domain. This creates a different impact.
Since feature teams can deliver customer value independently, having more backlogs won’t have direct impact on e2e cycle time. But there is an unintended impact on adaptability - ability to change direction.
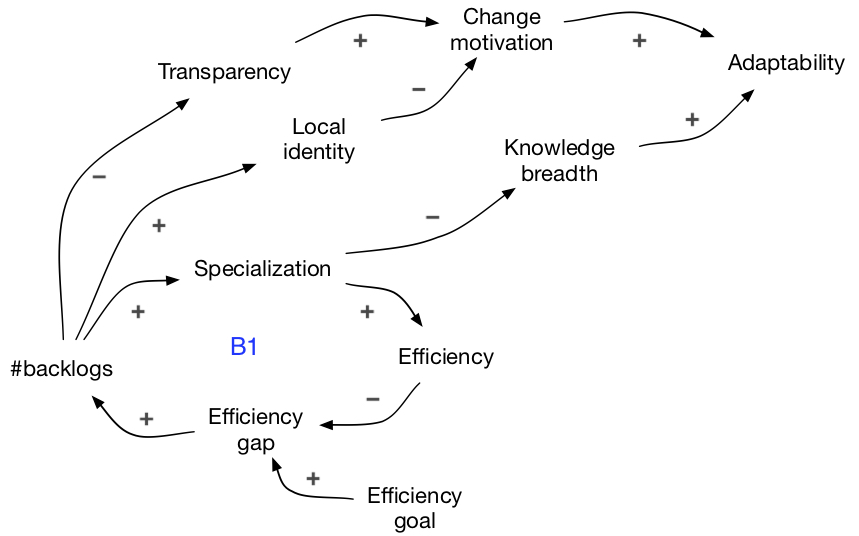
In the upper part of the diagram, there are 3 causal links from the number of backlogs to adaptability.
All of them indicate that having more backlogs leads to lower adaptability.
For higher adaptability we need to:
Let’s see how to drive toward fewer backlogs in the context of feature teams.
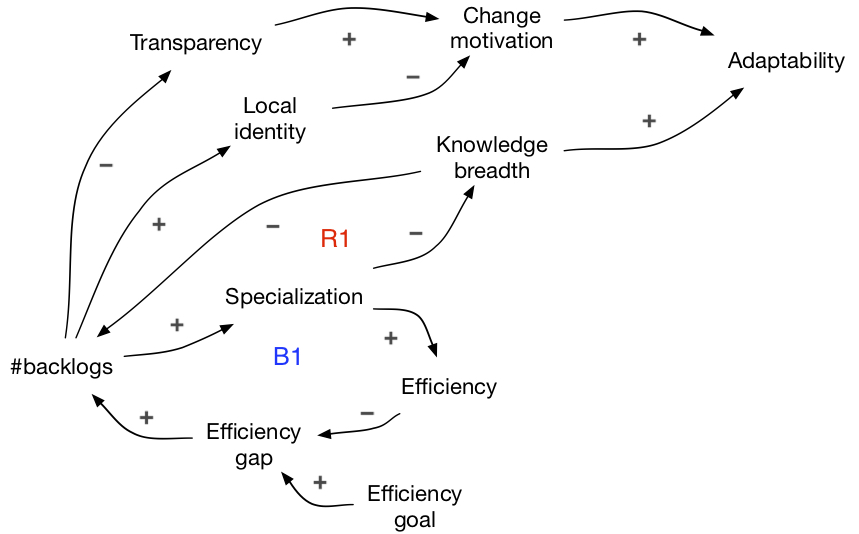
R1-loop: fewer backlogs drive broad learning
More backlogs lead to more specialization and narrower knowledge. The narrow knowledge, in turn, becomes the cause for more backlogs, thus creating a reinforcing R1-loop. It is easier to work in the direction of increasing the number of backlogs, how could we turn this around?
Take the same reinforcing loop and read it as follows: fewer backlogs, less specialization, broader knowledge, even fewer backlogs… The challenge is that less specialization does not lead to broader knowledge by itself. We need multi-learning to increase the knowledge breadth.
Fewer backlogs drive multi-learning; multi-learning enables fewer backlogs. They are mutually reinforcing. Therefore, the number of backlogs itself is an important lever - have one backlog for multiple feature teams.
The above analysis is exactly the same as the one for functional and component teams. What are the differences here? Here, the knowledge breadth is about customer domains, rather than functions or components. The backlog is product backlog, rather than functional or component backlog. The multi-learning is cross-domain learning, rather than cross-functional or cross-component learning.
What are the techniques for doing cross-domain learning? LeSS provides a guide about multi-team PBR. This is the key practice for any feature team to learn broadly about as many items as desirable from the same product backlog. In fact, when you start an adoption, it is recommended to do all-teams PBR by default, in order to maximize the learning. During multi-team PBR, instead of having different feature teams refine different items, we create mixed groups with people from different feature teams, and have them refine different items. They diverge and merge to get maximum cross-domain learning among feature teams sharing one product backlog.
In summary, the backlogs associated with feature teams are still there for efficiency. But the unintended impact is on adaptability, rather than e2e cycle time. Cross-domain learning enables fewer product backlogs, while fewer product backlogs in turn drives cross-domain learning.
Let’s conclude this series by putting various types of backlogs, specialization and multi-learning together.
| Backlog | Specialization | Multi-learning |
|---|---|---|
| Functional backlog | Function | Cross-functional |
| Component backlog | Component | Cross-component |
| Product backlog | Customer domain | Cross-domain |
The driver for having multiple various backlogs is the desire for higher efficiency through specialization. Teams specialize in different things: functions, components and customer domains. It creates different problems. Functional and component backlogs create dependencies for delivering customer value, thus, they have the most impact on e2e cycle time. While independent product backlogs for feature teams has the most impact on adaptability.
The key lever for all lies in multi-learning, though different types of multi-learning. Cross-functional learning enables fewer functional backlogs; cross-component learning enables fewer component backlogs; and cross-domain learning enables fewer product backlogs.
This ends the series about the number of backlogs and multi-learning.