Huawei
Huawei - LeSS without Scrum
(中文版)
LeSS without Scrum describes an experience where we applied LeSS organizational design elements for large-scale “agile” adoptions without first introducing Scrum in teams. This illustrates an organization-first approach, in contrast to the more common bottom-up team-first approach seen in what is arguably a somewhat naive approach to adoption in large-scale domains. In contrast, these adoptions more closely followed the LeSS adoption guide from the third LeSS book, Large-Scale Scrum, called “Three Adoption Principles” that starts an adoption top-down and bottom-up. Why was that useful? Because the proper organizational design provides the solid foundation for the further coaching and amplifies its effectiveness. We used the same approach in two different development groups within the same company. The two groups represented cases of different sizes, as cases of LeSS and LeSS Huge respectively.
Background
This experience report is from two development groups of Huawei in Hangzhou, China during 2015-2016. I worked as a consultant to help their large-scale agile adoption. This company is huge, having tens thousands of people in product development. They are organized into business units and development groups, each of which is usually hundreds to thousands of people. They had previously attempted a so-called “agile” adoption, predictably and strongly demonstrating “Larman’s Laws”. For example, what they incorrectly called an “iteration” was in fact a small waterfall, which quite often left testing and open bugs to the next iteration. And what they incorrectly called “continuous integration” was just about a daily build and test automation, rather than the developer practice of developers continuously integrating their code together.
In the middle of 2015 when I was hired as an external consultant to help their large-scale agile adoption, my internal contact Chen Guangjing had some candidate development groups in mind, but there was no decision from any of them that a LeSS or a LeSS-like approach was the way to go. Therefore, we did a few LeSS education sessions – described in some more detail later – to raise the awareness and build the proper understanding about what this would mean.
It came as no surprise that they realized that the change was bigger than they initially anticipated. In fact, no development group expressed that they would try an adoption after the initial workshop. Is that a problem for a LeSS adoption? Not at all! We are far more interested in a small number of groups taking a real step of effective change based on being educated and deliberate, over a large number playing the “change game.” In fact, because of the prior faux-agile adoption that did not of course demonstrate any meaningful benefit, the last thing I wanted was another fake change scenario. Therefore, many of them never actually took the next step.
However, two groups decided to move ahead, which became the two cases in this experience report.
Why Organization First?
It is unfortunately common to attempt to pilot Scrum in a project, since a project team is cross-functional and end-to-end by nature. Why is this frequently doomed to failure? With the traditional matrix structure that is prevalent in a project organization, the project team is not a real team, but just a group of people who each focus on their own single respective specialty areas, such as front-end development, testing, and so on. Even though it is “in project management theory” possible, without meaningful organizational structural change, to align everyone in a “project team” towards a common goal and take shared responsibility, the alignment is fragile – and as far as I can tell after many years of working and coaching, rarely works well.
Why is that?
- Project team members have partial allocation leading to multitasking. This not only reduces individual throughput, but also leads to the next problem…
- Project team members do not cross-learn other specialities, because they are so much utilized for “local efficiency.” This reduces learning, thus, degrades the capability of adaptation as a team, which can be seen in the next problem…
- Project team members do not swarm together to get items done. “Team” exists only in name, it is really just a group of individuals, and they can not work together on achieving the common goal. This leads to the next problem…
- Project team members do not self-manage as a team. As they do not work on the common goal at the same time and place in practice, someone else manages to get the goal achieved, which is the role of traditional project manager. This again reinforces the lack of team’s self-management.
Considering all other challenges such as lack of capability in collaboration and engineering, the lack of motivation due to missing structural support makes it even more difficult to succeed. In my experience, a lot of teams faltered after some time. Some organizations move further by changing the organization structure, while others regress to the status quo.

This is well illustrated by Richard Hackman’s work. In his classic book Leading Teams, the relations as shown in Figure 1 among team performance, team design, and coaching are insightful. Both well-designed team and effective coaching affect team performance, while team design plays a much bigger role among them.
In Scrum, the Scrum Master is responsible for providing effective coaching. But in my experience, the initial Scrum Masters in most organizations are just starting to learn about coaching. The root cause of many exposed impediments will be related to organizational structure. This increases the complexity of the coaching, and it is overwhelming to them. And on top of these problems when starting an adoption, the concept of coaching was and is foreign to my client, and it is hard for them to imagine a self-organizing team without an appointed manager. The chance of success would be low if we piloted one Scrum Team in the existing structure (without organizational redesign) and let loose an inexperienced Scrum Master to attempt to coach the team towards self-organization.
Therefore, we took a different approach to (1) focus first on establishing proper structure, and (2) later increasing the coaching capability.
Another reason to first focus on organizational structure came from this particular assignment, as my consulting was expected to help them experience and benefit from applying LeSS on their large-scale agile adoption. Deep organizational redesign is necessary for a successful LeSS adoption. In fact, it is so important that it is highlighted as one of the LeSS rules for adoption: “for the product group, establish the complete LeSS structure ‘at the start’; this is vital for a LeSS adoption.”
Most organizations try to avoid organization structural change, as they see it risky. And it can be risky, particularly when it involves hundreds or even thousands of people at the same time. But because there is now a lot of experience in LeSS adoptions, this is now well understood. Therefore, one of the principles for a successful LeSS adoption is deep and narrow over broad and shallow. This means that in the “smaller” large scale, which involves approximately 50 people or less, we establish the complete LeSS structure at the start. In contrast, in the very large scale – the cases of LeSS Huge – the adoption with structural change is done with an evolutionary incremental approach.
Organizational Constraints
One of the initial critical decisions in adopting LeSS is to define what the product is. In my client company, the development of almost all products are spread into multiple development groups, which are organizational entities, as shown in Figure 2.
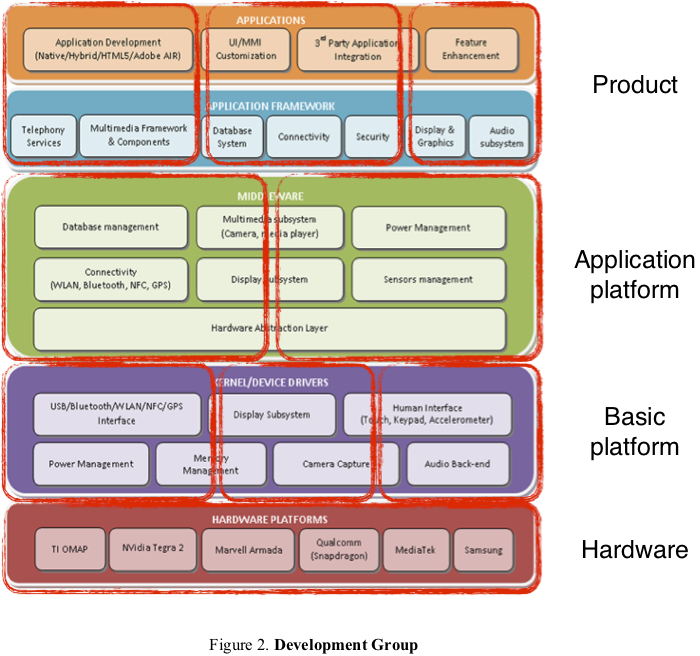
There are various development groups. The “product” development group is responsible for the real product to the end customers; it usually has dependency to other development groups such as platforms or network management. The platform is further split into application platform and basic platform, and so too is the development group. For complex products, they are built upon application platforms and basic platforms; while for simple products, they are only built upon basic platforms.
For example, Base Station is a real product to telecom operators such as China Mobile, and it is built upon platforms, and dependent on network management. There are at least three development groups involved to deliver the complete solution: Base Station (the “product” development group), Platform (at least one “platform” development group), and Network management (another “real product” development group). This is still a simplified view, while in reality, there are often many platforms involved.
As a LeSS rule, “the definition of product should be as broad and end-user/customer centric as is practical.” In expanding product definition as broad as possible, it should include the whole stack. However, as we worked with the management of development groups who could only make structural change within their scope, we had to start from the product definition constrained by the scope of development groups. This is in line with the LeSS guide in Large-Scale Scrum called “Define Your Product”, where one of the common restraining forces that narrow a product definition is existing structures. As shown in Figure 3, the possible evolving path for “product” development group is to expand and include at least the “application platform” development group. While for “basic platform” development group, it is possible to evolve into a real generic platform product, though we have to understand that this means to enter into a different market and work with different customers.
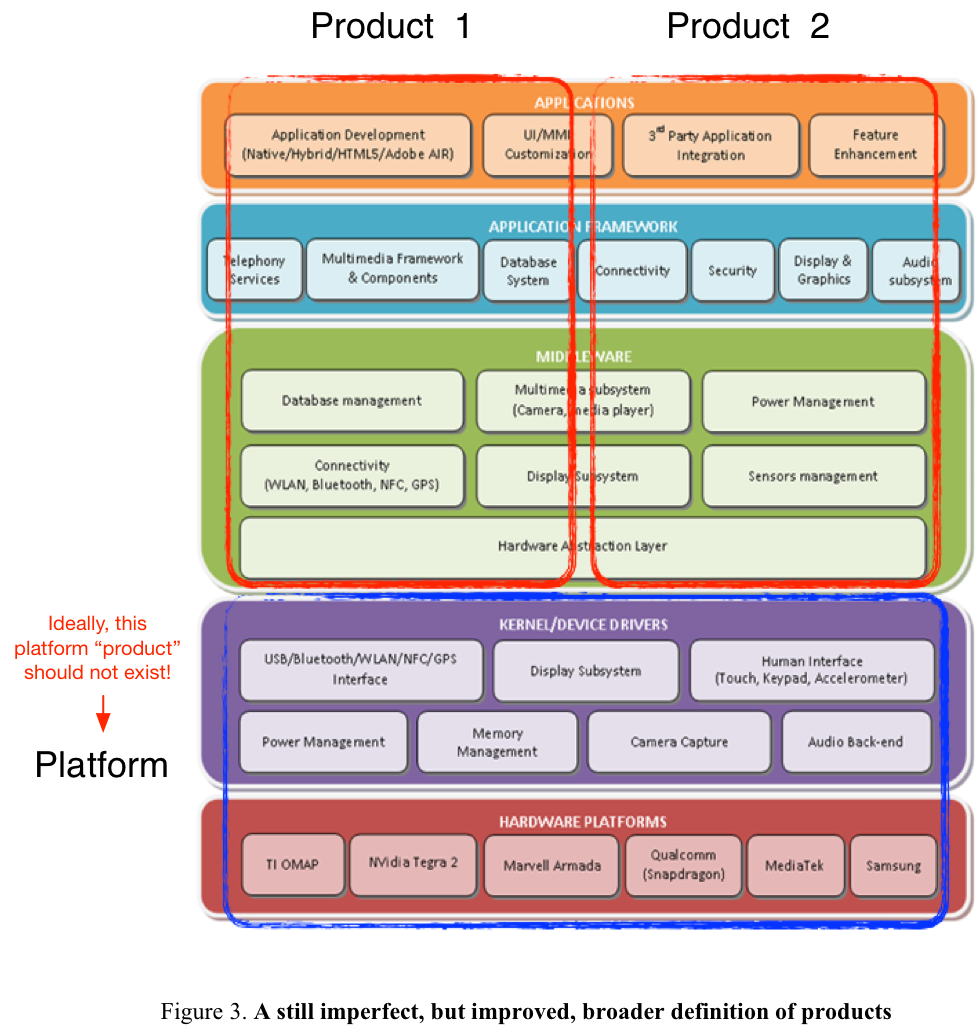
The two development groups we worked with represented different types of development groups: one for basic platform and the other for product. Even though the product did use the basic platform (among others), it used the basic platform pretty much as it was – with only very minor changes to the code, to support the higher level product. Thus, the two cases were chosen as independent adoptions, even though in an ideal expansion of the product definition, they would be both part of the same broader product definition. They also represented different sizes, one approximately 40 people and the other approximately 120 people, thus, providing cases of LeSS and LeSS Huge respectively. We first started with the LeSS case in late 2015 (for the “lower” platform group), and then the LeSS Huge case in 2016 (for the “upper” product group). There was some overlapping period when I worked with both groups at the same time.
LeSS Adoption in “Platform” Development Group
The development group in this case develops a platform shared by multiple higher-level truly commercial products, and at the time of the coaching consisted of approximately 40 people. To repeat a prior point – and worth repeating – in an ideal broader product definition this platform group would not be a separate “product” and would just be part of a much broader front-to-back single large product. But the structural boundaries made that impractical as a first step. This art-of-the-possible reflects the LeSS rule on product definition: “The definition of product should be as broad and end-user/customer centric as is practical. Over time, the definition of product might expand. Broader definitions are preferred.”
The platform offers functionalities such as extended OS (Operating System), communication, patching, and so on. As they are in a lower layer, they have little dependency upon other development groups, but other groups depend on them. The requirements to them are not directly customer requirements, but part of the solution defined by upper application layers, which could be another platform or a real product.
Build Awareness
The initial workshop happened in August of 2015. It was a two-day LeSS workshop, focusing on the organizational design principles behind one Product Backlog and behind feature teams. We invited key managers and influential leaders from a few development groups; about half of them were from this group. In short, we started with the LeSS guide “Getting Started” that starts with Step 0: Educate Everyone. However, the decision to have organizational structure change happened in late 2015, 3-4 months after the workshop. This is a common adoption experiment in LeSS: to decide slowly and with careful learning and discussion before actually making the change. Meanwhile, we had a few deep discussions with the management team. This is usually the case as the organizational change is risky and involves much personnel change.
Change starts long before it starts.
One Product Owner and One Product Backlog
One key aspect of the work redesign was around the creation of one (and only one) shared Product Backlog across the feature teams, reflecting the LeSS rule: “There is one Product Owner and one Product Backlog for the complete shippable product”. The main changes are summarized in Figure 4 (table below).
| Before | After |
|---|---|
| Work is scattered, including customers requirements, improvement, maintenance, and so on | All work goes through one Product Backlog |
| Work is organized in programs | Work is organized product-centric (platform in this case), with programs only as interface towards outside |
| Multiple program managers | One Product Owner |
| Done in phases (analysis, development, testing) | Common Definition of Done for all requirements |
Collecting all the work and putting it into one prioritized backlog was a key in work redesign. We got rid of the programs and shifted from program mode to product mode, which is in line with the LeSS guide “Product over Project or Program”.
And we followed the LeSS rule, “there is one Product Owner and one Product Backlog for the complete shippable product”, to have one and only one Product Owner. The organization used to have multiple program managers directing teams, predictably, with conflicting priorities. As we got rid of the programs, we got rid of the program managers too. One of the former program managers had a solid business understanding and good relationship with the people in the real products, and so became the Product Owner.
In order to get one Product Owner working well in practice, e.g. not overloading him, it is necessary for the Product Owner to focus on prioritization while having teams do the clarification, and do it as directly as possible with customers, as in the LeSS guide “Prioritization over Clarification”. We will elaborate more on this in the section Sprint practices.
Initial Definition of Done
Another important aspect related to work redesign was to agree on the Definition of Done. We took the original criteria from their iteration as the starting point, compared it with release criteria and clarified unclear issues. This was done together with the Product Owner, domain experts, and management, and was reviewed by the newly-formed teams before starting the first Sprint. This is in line with the LeSS guide “Creating the Definition of Done”. The initial version of the Definition of Done was imperfect because it did not end in shippable product, because of constraints described next. So there was a roughly 2-week delay between the (imperfect) “done” product increment and the final truly shippable product increment. The undone work that was formally identified as not being possible to immediately include in the initial Definition of Done consisted mainly of two types.
One was the internal work fully controlled by this “platform” development group itself, most importantly full regression and security checking. The full regression was still dependent upon some manual effort; and security checking consumed much effort with the existing process. The needed effort made it not economical to do them in every Sprint.
The other was the integration work that had to be done together with applications or application platforms, i.e. other development groups. Traditionally, other groups would not consume any item still under development, and they had the fantasy that the integration would be trivial thus not necessary to do it earlier.
We dealt with the undone work in temporarily-needed Release Sprint, as illustrated in the LeSS guide “Creating the Definition of Done” – step 3, explore what to do with the undone work. Feature teams, rather than a separate team, did the undone work to avoid the handoff waste.
Later we made solid progress in reducing both types of the undone work, following the LeSS guide “Evolve the Definition of Done”.
How? We moved the internal work into each Sprint (and thus into the Definition of Done) via automation and process optimization. And we were able to do the integration work with real products for roughly ⅓ of items by the end of my coaching assignment.
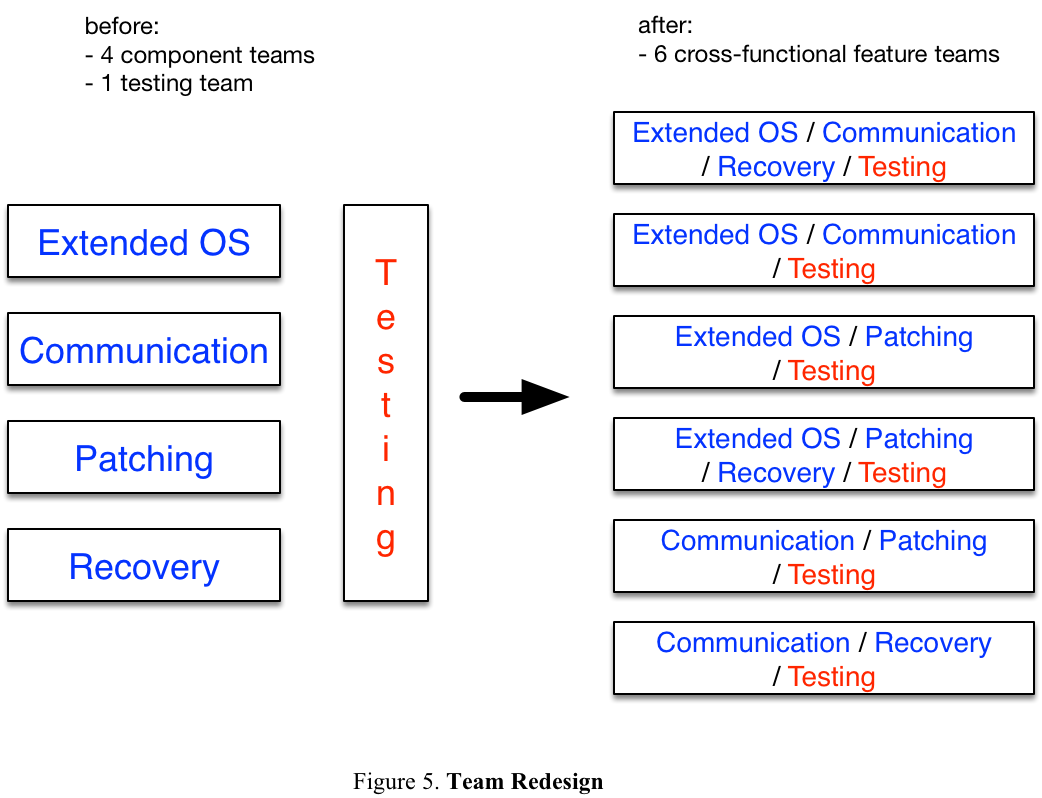
Self-Designing Team
Before adopting LeSS, there were 4 component teams responsible for different components, and one testing team. We reorganized them into 6 feature teams via a self-designing Team workshop, which followed the LeSS guide “Three Adoption Principles” – use volunteering. Our aim was to create cross-functional and cross-component feature teams out of single-function and component teams, following the LeSS rules, “each team is (1) self-managing, (2) cross-functional, (3) co-located, and (4) long-lived” and “the majority of the teams are customer-focused feature teams”, as well as the LeSS guides, “Build Team-Based Organizations” and “LeSS Organizational Structure”.
Management and I worked out some new-team constraints, and the initial list was as below.
- Team size is 5-7 people
- Team is cross-functional
- Team is cross-component and feature oriented, being able to complete “end-to-end features” within the platform
- Team has broad knowledge and is thus adaptive (flexible), being able to take any item from the one shared Product Backlog
Regarding the last point, we were concerned about the consequences of every team being a good generalist but without specialization. Even though it provided the most flexibility, it raised the biggest challenge in creating sufficient throughput in the short term, since (unfortunately) there was pressure to deliver fast, with insufficient slack for learning. So we applied the LeSS guide “Prefer Specialization in the Customer Domain.” How?
There were 4 noteworthy domains (such as extended OS, patching), and there would be 6 teams. We tried to support the two factors of broad knowledge (for adaptiveness) and good throughput, via (1) having each team able to work in at least 2 domains, and (2) with each domain having at least 3 capable teams. This change made each team still possible to have some level of specialization for throughput, while at the same time enabled the whole group to work on the highest priorities of the Product Owner, without distorted prioritization to meet the limited constraints of rigid teams that could only do one thing.
After these decisions we moved on to design the agenda for the self-designing team workshop. We referred to some ideas shared in this article, and made a rough agenda like this:
- Opening (development group head highlights the motivation behind this)
- Volunteer for Team Leaders (see 2.4 Scrum Master vs. Team Leader)
- Self-designing team cycle 1 (with initial constraints set by management)
- Self-designing team cycle 2 (with additional constraints set by participants)
- Self-designing team cycle 3 (fixing “bugs” – unmet constraints)
- Create team resume and present to the whole group
- Wrap-up (participants share their feeling and comments at their will)
Each cycle ended up with a setup of 6 emerging teams. In cycle 2, it started by asking participants to come up with additional constraints that would help form teams better. As they already saw one concrete setup from cycle 1, it was a lot easier. For example, they noticed that some emerging teams consisted only of senior people, while others only of junior people. When this was raised, a short open discussion ensued and we did a consensus checking to refine the list by adding a constraint about seniority of the members in each team. In cycle 3, it started by asking the whole group to raise “bugs” for teams created out of cycle 2. A “bug” could be that (1) one team lacked testing skill, (2) there were only 2 capable teams for the specific domain, and so on. Then, they self-organized to fulfill those unmet constraints.
The whole workshop took 2.5 hours, and the outcome was 6 new stable teams created, as well as the charged energy to get started. The before and after state is summarized in Figure 5.
Scrum Master vs. Team Leader
One challenge for my client to adopt LeSS, or more precisely Scrum, was introducing the Scrum Master role. A Scrum Master is a coach, while coach as a role is virtually nonexistent in traditional organizations. Meanwhile, a Team Leader role is commonplace, and traditional organizations hold them accountable for team (usually just a group rather than a real team) performance. This strongly contrasts with the model of team accountability in Scrum and LeSS
As it was clear that we could not reach agreement on this, we decided to keep Team Leader role and define accountability a bit vaguely – shared by both Team Leader and team. This was far from optimal, but that was our starting point. Later, we educated Team Leaders about coaching self-organizing teams through training and coaching by example – facilitating Daily Scrum and Sprint Retrospective. Afterwards, I was pulled by some Team Leaders to help further in developing their coaching capabilities. Some Team Leaders developed themselves into more of a Scrum Master/Coach role, but other Team Leaders continued more or less their old way of command and control.
Sprint Practices
With a consistently supportive organization structure in place (excluding the remaining Team Leader role), we were able to do the LeSS Sprint practices in a straightforward way.
Product Backlog Refinement
As we had one Product Owner and one Product Backlog for the 6 teams in the whole platform, we started with overall Product Backlog Refinement (PBR), which not only started the clarification work, but also served as a coordination step between teams for how to do the further PBR among teams. This is in line with the LeSS guide “Overall PBR”. The Product Owner and team representatives worked together to decide which items would be refined by which teams. We decided for some items to be done by some teams, while leaving other items open thus refined by multiple candidate teams. The final decision of which teams working on which items would be made in Sprint Planning. Even though teams were cross-functional feature teams, the specific knowledge was not distributed evenly. Thus, people from different teams were still pulled as needed into the refinement of certain items.
Sprint Planning
Sprint Planning (both parts 1 and 2 in LeSS) happened jointly in a big common space, as shown in Figure 6. The participants included the Product Owner, all Teams, some consumer-developers of the platform, as well as some “technical support” people. Being all together really helped, because the planning and clarification of most items benefited from input from both multiple teams and multiple stakeholders. One of the lessons we learned from this adoption is that we did not do enough multi-team PBR before Sprint Planning (we did mostly single-team PBR), and this led to the need for more stakeholders and more clarification and coordination discussion during Sprint Planning than actually should have been necessary. For example, we once discovered that two teams got two separate items from two (real) product groups, but those items had the same underlying need. That could have been discovered much earlier we had done more multi-team PBR. But in any event by having multiple stakeholders at Sprint Planning we were able to see this, and worked it out.
Of course, Sprint Planning One is for understanding what to build. As usual, started by having the Product Owner roughly presenting the Product Backlog and candidate items for the coming Sprint. Teams would together decide which items were picked up by which teams. The Product Owner made sure that high priority items were distributed to multiple teams for risk mitigation, as suggested in the LeSS guide “Sprint Planning One” – spread high-order items. The team-selection decision for some items was already made during PBR, and the decision for other items was made here. After the selection was done, teams in parallel clarified minor details that they did not think to explore during PBR, and discussed acceptance criteria directly with consumer-developers. When there was a lack of clarity about item scope, the Product Owner was pulled into the discussion.
Notice that the clarification started in PBR but continued in Sprint Planning One, in effect mixing the activities of two LeSS guides, “Multi-Team PBR” and “Sprint Planning One”.
And of course, Sprint Planning Two is for understanding how to build. In our case continued in the same big space, applying the semi-frequently-applied LeSS Guide “Multi-Team Sprint Planning Two” with all teams (rather than a subset of teams). Why an all-together multi-team part two? , Because it increased the likelihood that teams would identify opportunities for coordination. It was common to hear some team simply shouting that “We need to make a big change on component X in the next Sprint. Would any team like to have a joint discussion about the basic design?” And then other teams would respond.
During Sprint Planning One or Two, it was likely that some teams found that they could not take as many items as they initially thought, while other teams found that they could take on more. As all teams were present, it was easy to adjust through self-organization among teams and the Product Owner.
The planning efficiency was low in the beginning; nevertheless, we stuck with the timebox, which meant that in the early Sprints the planning output was not as good as we would like to have. Initially we were only able to identify a few key acceptance criteria and create gigantic and vague tasks. As our skill improved, we were able to draft better acceptance and create smaller and clearer tasks, usually by thinking about and collaborating on more speculative design.

Using the Daily Scrum to Coach the Team Leaders
With the Team Leaders having various understandings about the Daily Scrum – some misunderstanding it as status report meeting, it was a great place to coach by example. Every time I visited them, I observed their Daily Scrum and tried to ask powerful questions such as “what is our Sprint goal?”, “what are most important risks for us to achieve our goal?”, “what slows us down?”, “what are most important tasks for us to achieve our goal?”, “how shall we adapt?”, and so on. By letting team think of those by themselves and discuss about those together to make decisions on how to move forward, it opened up Team Leaders’ view on alternative ways of leading teams. Some of them got interested in coaching and started to learn about asking powerful questions. I focused on helping those who would like to grow into coaching type of Team Leaders.
Cross-Team Coordination
The whole group was together on one floor of one building. In very simple ways, that strongly helped cross-team coordination.
There never emerged a need for a Scrum of Scrums meeting, which is in line with the LeSS guide “Maybe Don’t Do Scrum of Scrums”. Out of PBR and all-together Multi-Team Sprint Planning Two, teams usually had good idea about which others they needed to keep in close communication with during the Sprint. They set up various channels to coordinate in a decentralized way, which is in line with LeSS rule, “prefer decentralized and informal coordination over centralized coordination.” How? One example was simply to have someone observe another team’s Daily Scrum, as per the LeSS guide “Scouts”.
Component reviewers were introduced to reduce quality risks due to knowledge gap in feature teams, but they also helped discover coordination needs across teams.
Community of Testing is one instance of the LeSS guide “Communities”. It not only supported learning and improving testing skills, but also helped discover coordination needs across teams.
These multiple channels and with the focus on identifying coordination needs are two key points regarding LeSS view on coordination.
From Quality Control to Built-in Quality
Before the LeSS adoption, the group had the traditional weak practice of “inspecting defects out after creation” rather than “building quality in at creation time.” These included design document reviews after a document was created, and code reviews after code was created. Unfortunately, the group did not grasp that the LeSS guide “Multi-Team Design Workshop” and the XP practice of pair (or mob) programming could replace those “inspect defects out” activities with the more powerful “build quality in” practices. Therefore, unfortunately, even after the LeSS adoption, there were still the same “inspect defects out” activities performed by a small number of designated reviewers.
The adoption of LeSS at least increased the transparency of the ineffectiveness of the practices, as they strongly slowed down development and prevented integrating continuously.
The group adapted in two ways. One was to increase the frequency of reviews, as well as promoting small batches and frequent submission. The second was to increase the number of designated reviewers, so that there was at least one per team.
Meanwhile, those reviewers helped teams increase knowledge on the components so as to avoid massive comments during the review. Over time, it was delegated for designated reviewers within teams to decide whether review is necessary.
Sprint Review… and Getting Feedback from our Consumers
In the beginning, we thought about inviting many consumer-developers and stakeholders to the Sprint Review. It turned out that many of them were not interested, for reasons that were mostly variations of the fact that this platform was not a real end-to-end product, but just a … technical platform. A Sprint Review is meant to include looking at and ideally playing with meaningful items, but since the platform items boiled down to just APIs and services for higher-level groups, there were not tangible items to play with.
So the valuable feedback that one would normally get in a Sprint Review was in this case obtained only when the consuming development groups integrated and used the platform increment from each Sprint.
We agreed that the most valuable feedback came from the integrated use of the platform, thus, we focused on learning and feedback from the consuming groups during the Sprint, rather than at the Sprint Review. Eventually, we expanded our Definition of Done to capture this – that the integration with higher-level applications was also done within each Sprint. This prompted us to ask “when would the application consume this item?” when deciding the item priority. In fact, there was time when we only discovered that the items were not needed any more after they were delivered.
When the use happened during the Sprint for specific items, the consumer-developers had direct conversation with the team, so that any insufficiency would just surface. We simply shared the learning and feedback, and discussed about their implications and updated Product Backlog accordingly at the Sprint Review.
As the platform was essentially a big component for the real products, we could not make the inspection and adaptation based on the real customer value of done items and future items, as it should be in Sprint Review. The real product inspection and adaptation happened in the product level, with our work integrated into real product items. Then, our Sprint Review unfortunately focused more on adjusting Product Backlog to meet release schedules for various products.
Retrospectives and Continuous Improvement
We used both Sprint Retrospective and Overall Retrospective for continuous improvement. Here is a summary of example adaptations we already talked about.
- Changed from mandatory review process to voluntary review process
- Moved integration with application into the Sprint
- Test automation to lower the cost of full regression
- Process optimization to lower the cost of security checking
From the first Sprint, we introduced team level retrospectives. Traditionally, it was the Team Leader who thought of improvement ideas then directed team to implement. Their previous experience was that they got silent response when asking the team for ideas, thus, they could not see how to engage the team for continuous improvement. I facilitated retrospectives for all teams at least once, and demonstrated the difference that effective facilitation could make. For example, build a timeline together to reflect the team’s view on the past Sprint; generate ideas for action via 1-2-4-All structure. Some Team Leaders became interested in facilitative way of leading teams, then, I worked with them in helping develop their capabilities.
We implemented the LeSS rule “Overall Retrospective”. We started with a first, special Overall Retrospective before the first LeSS Sprint, with the whole group present. The reflection was done for the last release of 2-3 months. For Overall Retrospective in each Sprint, only Team Leaders, the Product Owner, and supporting managers attended, to start with. We discussed about whether to involve other team representatives and decided to start without them as the first step. Why? Because, unfortunately, previously doing “organizational improvement analysis” that included hands-on team members was very far from the normal way of working. So to transition to the “radical” new mindset and behavior of engaging regular team members in thinking about system-level organizational improvement, we decided to take baby steps, starting with the Team Leaders, and only later integrating other team members.
One focus in continuous improvement was to shorten the time from an imperfect done increment to a perfectly done shippable increment. This was a theme for quite a few Sprints. Through systematically removing impediments and expanding the Definition of Done, as per the LeSS guide “Evolve the Definition of Done”, this duration was decreased from roughly two weeks to three days, over six months of improvement experiments.
Overall, there was a significant improvement in cycle time and throughput. And in terms of quality, the level of external defects was low before the change, and they were kept at the same low level after the adoption of LeSS.
Remaining Major Weaknesses and Areas for Improvement
At the time that I left them, these were some remaining major improvement areas:
- The whole scope of the adoption was still within only the platform. It should expand along with a much broader product definition that spans “top to bottom”.
- The Definition of Done was still imperfect. It required three days of handling knowingly deferred “undone” work before being truly potentially shippable.
- The level of narrow specialization in feature teams somewhat inhibits adaptiveness of teams to do whatever the Product Owner prioritizes. There’s a need for broader learning still.
- Accountability needs to be removed from the Team Leader and given completely to the team, and then of course the Team Leader role needs to be eliminated.
- More multi-team PBRs to increase broader learning and then, more team adaptiveness.
- Increase “build quality in” by doing pair or mob programming and integrating continuously.
- Involve team members regularly in Overall Retrospective.
LeSS Huge Adoption in “Product” Development Group
The second case to (more briefly) discuss is a LeSS Huge adoption. It happened in the same company but in a different development group. As described before, even though this product did use the platform in the last adoption, their adoptions were done independently.
The development group in this case develops a network security product, consisting of approximately 120 people. The size of organization exceeded the smaller LeSS organizational design system (for “50” people), and it was a case for the LeSS Huge organizational design system. There were three groups, one doing the web interface in Beijing, and the other two doing the work in network equipment (hardware and related software) in Hangzhou. As usual, many features cut through both the front-end web interface and the “back-end” components related to the equipment.
Requirement Area
The critical decision in LeSS Huge adoption is the formation of Requirement Areas (RAs) as grouping for both work and people, as per the LeSS guide “Requirement Area”.
A smaller LeSS organizational design system adoption should be “all at once”. But LeSS Huge adoptions are different, due to the overwhelming complexity and weaknesses exposed. So we need to consider two key adoption guides for Huge cases: “Evolutionary Incremental Adoption”, and “One Requirement Area at a Time”.
And that implies that in the early LeSS Huge adoption steps there will be some groups in the new model of feature teams, and some in the old model of component teams. As an example, ideally, we should have dissolved the Beijing web-interface group, since it is just a large front-end component group (and so creates delays, handoff, and other wastes). But especially because it was a component group at a different site, and this was the first step in the adoption, we decided to temporarily leave that group in their traditional mode. It would have been too hard to fix that problem in the first step.
So we decided on an adoption vision of two RAs, focusing in Hangzhou first. The Beijing site would temporarily remain as a traditional component group. The two RAs were named “Collaborative Operation” and “System Support”.
Why only one site first? Although LeSS adoptions can be and are multi-site, we felt – as do many other LeSS coaches – that it was important to aim for visible success without too many problems in the first step. Starting off the first step of a large adoption in two or more sites increases the risk of drowning the organization in issues, when developing support for the adoption is still important.
So we did apply the Huge guide “Evolutionary Incremental Adoption.” But we did not apply the guide “One Requirement Area at a Time.” Why? There were “only” 80 developers at the common Hangzhou site, and we felt relatively confident – because of only two RAs involved and the relatively small structural gap as will be described later – that we could successfully do an all-at-once adoption with two RAs in this context.
Another interesting decision was whether we would couple a Requirement Area with a formal line organization in the “org chart.” We decided to decouple the formal organization structure from Requirement Areas, following the tip in the LeSS guide “LeSS Huge Organization” – “Avoid having the Requirements Areas be equal to the organizational structure as it leads to them being difficult to change.” Why does this tip exist? We saw it for ourselves in this adoption. Each market release was about six months, and from one release to the next, there was significant shift in priority focus between the two RAs. So we wanted some teams to (each release) move from one RA to the other. It would have been too painful (given the broader organization policies) to formally move teams across “reporting lines” that frequently. Structures are sticky! And to accommodate the fluctuation in priorities across the two RAs, we targeted to have one team in each RA to know enough to be able to work for both Requirement Areas.
Product Owner Team
As expected, there was one Product Owner, and two Area Product Owners. There were also three program managers who remained as interfaces towards the rest of the company that still assumed a program-centric (rather than product-centric) working model. Together they formed the Product Owner Team for the whole product.
The Product Owner was one of the most senior people in the organization, who had the capability to work with multiple stakeholders and make tough prioritization decisions. However, we were not able to find Area Product Owners with the similar level of experience in the organization, which clearly showed the weakness in its product management. With the vision that Area Product Owners eventually need to work directly with stakeholders and make tough decisions on their own, the one Product Owner acted as teacher and coach for the Area Product Owners to not only help them get the job done, but also grow their capability. This is in line with the LeSS guide “LeSS Huge Product Owner”, who has the task of growing and supporting Area Product Owners.
Extended Component Teams within Requirement Area
As the web-interface group in Beijing remained as a component group, we could not implement feature teams fully, at the first step. In this case, the LeSS guide “Feature-Team Adoption Maps” provides an evolutionary path. And so in our case, we started with extended component teams. This means that each (newly formed) team could develop across a range of components (and thus reducing many wastes and increasing adaptiveness) but that they were still not in the perfection-vision state of a true feature team that could work completely full stack, top to bottom.
In the first LeSS Huge adoption step, these extended component teams would do both automated and manual (exploratory) testing for the network equipment based on a Command-Line Interface, while the web-interface group would do the full end-to-end integration testing.
To implement extended component teams, one step is that we dissolved the testing group and had testers integrated permanently.
To implement one Product Backlog with LeSS Huge Area Backlogs, we had to create teams that would be able to work on any item in their RA. Before the change, each team worked on a single specialty sub-area, and essentially had an implicit backlog in each sub-area. How did we create such teams? Instead of doing team redesign, we let the existing teams expand their work scope to more components, with learning and feedback support from other teams previously having the single speciality. This was possible (versus reforming into new broader teams) because the original skill difference among the sub-areas was not big.
A future intended step in the LeSS Huge adoption, as per the incremental feature-team adoption maps approach, is that the teams in Hangzhou will learn to also take on the web interface development work, thus becoming full stack feature teams. And then of course also taking on the full end-to-end testing.
Dependency
Regarding Sprint practices, as usual in LeSS Huge, most activities happened within each Requirement Area. As this case was a real product, rather than a platform, it posed more complexity in terms of dependency. The product depended on network management and platforms, which were done by other development groups. It was not practical to extend the teams across development groups, due to organizational boundaries. Thus, we had to resort to other ways of managing dependency. As SAFe was used widely in many development groups of the company, we essentially tried to do a “Program Increment” sync to manage dependency across development groups, while moving towards feature teams to eliminate dependency within our development group. As we were able to sync our own internal work into the same Sprint, the integration was done as continuously as possible within the same Sprint. However, out of sync problems across development groups still happened quite often, as the underlying constraint came from the bigger structure – those other development groups essentially develop some kind of components for us.
In some future expanding of a broader product definition, it should include the scope of network management development group and “platform” development groups. Then we could expand to true front-to-back feature teams to dissolve those dependencies.
What We Learnt
The experience had strong resonance with Richard Hackman’s finding about proper team design outweighing effective coaching as the key factor to influence team performance. LeSS’s strong focus on organizational design reflects the same. The structure-first approach provides an alternative and better way to the traditional approach of piloting within the existing structure.
It would be better if we had agreed on a vision of effective coaching for teams. This lack of agreement at the organizational level limited how far we would go in terms of self-organizing teams, as it was left by chance to individual Team Leaders.
At the tactical level, here is a summary of what we learned:
- Use an incremental approach to expand domain specialization for more flexibility.
- Take a transitional path from traditional Team Leader to Scrum Master/Coach.
- Enable self-organization across teams via joint Scrum events.
- Enable one and only one Product Owner with multiple teams by getting all the teams deeply involved in requirement clarification and feedback.
In a way, this experience report is not a full story. It ignores what happened before we got involved. People within the organization should understand that the change introduced from the LeSS adoption was big thus be prepared to apply the art of possible and much patience until the point when the organizational redesign could happen.
Acknowledgements
I would like to thank my contact Chen Guangjing from Huawei. We worked closely during the whole journey, had lots of deep discussions about how to help those two development groups move forward, and shared many great insights.
I would like to give my deep appreciation on the great help that Chris Edwards, my shepherd, had given me in writing the initial experience report for Agile 2017; and Jurgen De Smet, my mentor, had given me in turning it into a LeSS case study. Lastly, I would like to thank Craig Larman for helping improve it to what it eventually becomes now.