Thales - Surface Radar
This is a story of how Thales Surface Radar TU Processing, a high-tech embedded software development department operating in an environment with defense requirements, transformed into one agile organization. A challenging journey for this 70-people department with 9 very specialized subdomains!
The Product Line and Context
Thales Group creates systems and services for the aerospace, defence, transportation, and security markets. One of the business units in The Netherlands is Surface Radar. Within Surface Radar, which is a product line rather than one product, is the Technical Unit Processing (TU Processing) department, which is responsible for the “Processing” functions in a radar system – the development of the digital processing functions in radar and optronic sensors (across the product line) for naval and air defense applications. Multidisciplinary teams pursue these developments, with specialists in the areas of system engineering, sensor functional design, architecture and realisation of real-time embedded systems.
“Processing” is just one of several major domains that make a complete radar system. Major domains include:
- Processing with air and surface tracking, helicopter tracking or drone identification.
- Combat Management System for defining the mission objectives and configuring overall mission needs.
The Processing functions are software intensive, though also include customized FPGA programming. Of course, the complete radar system includes lots of hardware development as well.
The TU Processing department has about 70 people, while the overall product group has a few hundreds in total. Major departments include:
- TU Processing
- System Engineering
- System Test
- Hardware
- Mechanical
Typical product development in TU Processing runs for multiple years with tens of thousands of person-hours needed to complete a delivery. The Processing domain consists of several very different and highly specialized subdomains, varying from sensor management to waveform calculation and burst management. And to the subdomains of the radar processing chain where the raw data is stepwise converted into an environmental picture with clear tracks. Each of these subdomains requires dedicated functional knowledge on for example FPGA development, concurrent and parallel computing to handle the 4 DVD’s of data that need to be analysed every second, and also complex mathematical algorithm development. Becoming a master in a subdomain takes several years and every subdomain uses different development stacks ranging from VHDL stacks, GPU programming all the way to Matlab, C and Java development.
This is a story of starting with a flaccid “Scrum-but” change and how we eventually improved towards a LeSS adoption within one major functional area, Processing, within the larger still-traditional product group. In LeSS terms, it is the story of a LeSS Huge product group and early adoption steps within one Requirement Area, “Processing”.
Early Experiments in Agile Practices & Component Teams
About 2005 the TU Processing department heard about the Agile Manifesto and the Scrum framework. There were doubts whether this would fit to the situation TU Processing has to operate in: a high-tech embedded software development environment with defense requirements.
However, the promised transparency and increased knowledge sharing sounded attractive. Hence, the department started to experiment. First with student projects, then research projects. Later on two dedicated small development projects in the radar domain. The promise to be able to deliver the most value within the constraints of time and budget became true. Hence it was decided to take a next step.
The Initial Challenges
Previous to the first “Scrum-but” adoption wave, the people worked in project teams. Each project had a few specialist engineers that would be dedicated to the projects. This approach led to several problems:
- Different projects creating their own solutions to the same problems and also to lots of duplicate code.
- Critical expertise was only at a few individuals in a project. This increased schedule risk in case the expert would become unavailable.
- Inflexibility of the organisation. In case projects needed a change in engineers, resource management needed to change their resource plans.
- Partially allocated engineers which is not at all good for team productivity.
As a reaction to these problems, traditional thinking led the development organisation to focus on functional specialization and to structure itself in stable component teams. Following the architecture of the system, for each subdomain a component team was created. For example, a team for sensor management, a team for digital signal processing, another team that does waveform calculation and so on.
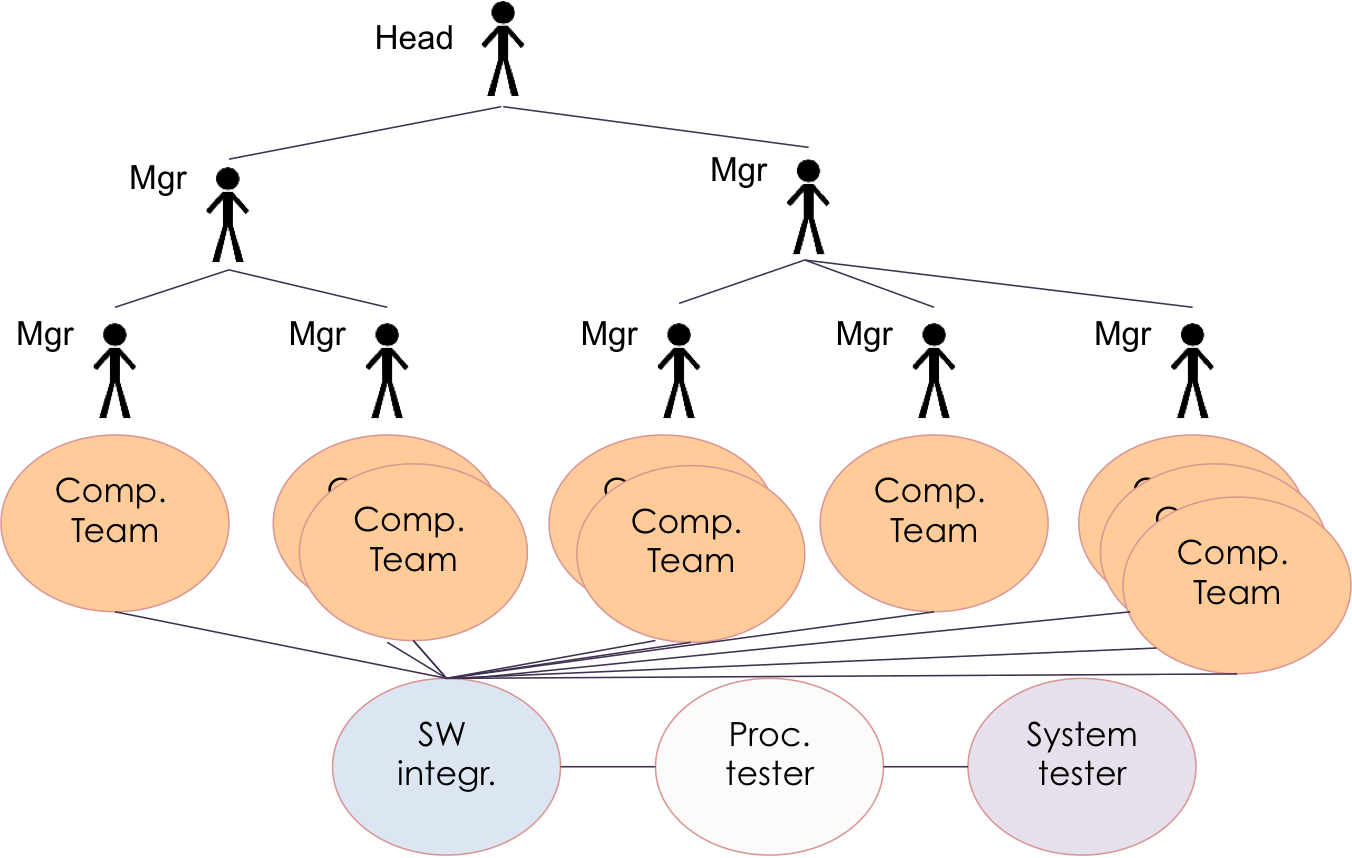
In this new structure, “Scrum-but” and fake Product Owners were introduced. These were simply the existing managers of component teams. The group still worked in a traditional project-management model, with single-function groups and sequential life-cycle with handoff, command-and-control, pushing commitments, late integration and testing, and so on. But some ‘agile’ labels like “Product Owner” (manager), “stories” (regular requirements), and “Product Backlog” (the old list of all the work to be done in a big batch) were pasted on top, it gave the impression to more senior management that “good modern ideas have been introduced”, though it was largely a facade.
Of course, because of the component-team specialization, an integration team was needed to integrate all components and also a functional-test team was introduced to test after the components were integrated.
This structure meant that:
- Instead of resourcing dedicated engineers to projects, the projects (i.e., project managers) brought work to the stable component teams.
- The component teams could avoid developing multiple solutions to the same problem within the scope of one component. On the other hand code duplication across components still happened because now every component team worked for itself.
- Because specialists on the same component worked together in a team, the schedule risk because of one specialist being unavailable was reduced because the people in the component teams could help each other. The specialists were now part of a team and the conditions for knowledge sharing were set.
Scrum-But with Component Teams
The “Scrum” adoption with component teams led to flaccid results. The engineers were happy, but they lacked a focus on customer-centric work. Project managers missed the focus on their milestones and felt they had lost control on what was done when. They used to (ineffectively) coordinate the work and put pressure on the project teams to get their work done, but now there were competing goals and pressures from different projects into the same component and component team, which created new coordination and competition problems.
Schedules and budgets were still being exceeded and there seemed to be an ever-growing need for coordinating the work between the component teams and handling dependencies between them. These were all signs of deeper problems waiting to be discovered.
Although the teams now delivered working components every Sprint, there was no working system every Sprint. And the organization still faced the following core challenges:
- The separate component teams locally optimized their own productivity. There was no focus on the whole product and therefore a poor focus on creating value. A lot of work was done every Sprint, but no integrated working product - no value - was being delivered.
- The responsibility of delivering an integrated functional working product was still being handed over to separate test teams causing unnecessary delay, coordination and meetings.
- Project managers still had the impossible task of managing requirements dependencies among all the component teams. This led to late integration and therefore higher costs of fixing defects and lack of transparency on development progress.
- Stakeholders complained about the lack of project transparency as project progress was measured on individual components. Again no whole-product focus.
- Line managers played the role of fake POs limiting team-customer interaction and inhibiting self-managing teams to arise.
The so-called “POs”, the focus on components in isolation, the absence of a customer focus and the lack of team autonomy was a recipe for failure.
The key lesson learned was that agile is about feedback and adding value. To increase feedback and value the teams need to increase their focus on the whole product
The Next Step in Change: Towards Feature Teams & LeSS
Managers originally thought the root of the problems had to do with the engineers and that the engineers should change, but the problem turned out to be the system and the managers that defined and enforced it. Managers, engineers and also the organizational design needed to change. So a larger organizational design change was eventually started.
The Good and Bad of a “Change Group”
Because the group was new to the idea of agile change forever that managers focus on forever, and therefore the importance of not having a change project or change group, it was decided that some of the managers would form a temporary change group to “initiate the change.”
The goals of the change group were useful: support top-down and bottom-up change, change the organizational structures, organize education to prepare for a larger step of change, communicate about the next step, and so on. And in that sense the “change group” was useful. But we realize now that it was also a mistake to create a distinct “change group” because it reinforced the old culture and beliefs that change to agile was a project with an end, rather than endless change and improvement of the organizational system within which the managers would be deeply involved for the rest of the daily work lives, focusing on “change the system forever.” It’s possible that after the “change group” disbands, some of them can think, “Our change work is done.”
Create a shared change vision
People that participate in creating the change vision become engaged, aligned and therefore will more likely contribute to the change1. And that’s exactly what you need; a mindset where people contribute to the change by learning and improving their own work.
Therefore, the change group had a number of shared visioning sessions to craft the initial change vision with people such as lead developers, architects and testers. The initial change vision was eventually written down in a few crisp and clear lines.
The biggest problem of the teams was the lack of whole product focus. Therefore, the core of the change vision was about being able deliver an integrated functional tested product that their customers could use every Sprint. The goal was to realize this within two years.
In the first months, the change group spent much time on communication. Bi-weekly walk-in sessions were set up for people to just walk-in to discuss the need for change and the business objectives. Next to that, numerous invite only awareness-sessions were organized for people to learn about agile development, how they do their work today, what can be improved and how Scrum would benefit them and their company.
Expanding the Definition of Done: The change direction
In Scrum and LeSS the expansion of the Definition Of Done is used to reveal weaknesses, increase transparency, and improve the system until ultimately the group can ship every Sprint. We used this idea and mapped it to the old traditional V-model sequential lifecycle that Thales uses so that the plan could be communicated effectively.
During the flaccid-Scrum phase with component teams, each team had their own Definition Of Done that included functional tested components.
In Step-1 away from that model, one Definition Of Done was introduced for all teams and extended to include integration testing. The plan was for all teams to deliver an integrated product every Sprint. The teams would have to work together with the integration test team to make it happen. Once the organization was able to do that, the separate integration team would be dissolved.
In Step-2 the Definition Of Done would be extended up to testing at the processing level. The teams would have to be able to do functional testing in the Sprint so that the product group would be able to deliver integrated and functional tested product every Sprint.
System testing was not planned for inclusion in the Definition of Done because system testing includes hardware and electronics development that was not within the scope of our change.
Organizational Structure Change
Now that the more significant change journey had started, the most obvious next step was to move from component teams to feature teams because that would create an immediate focus on delivering customer value. Unfortunately the management decided this change was a too big and too risky shortly after the move from project teams to component teams. After all we were dealing with 9 teams of heavily specialized component teams. The choice was made to expand the responsibility of the teams gradually. And to help with doing that, we did the following …
Feature Team Adoption Map
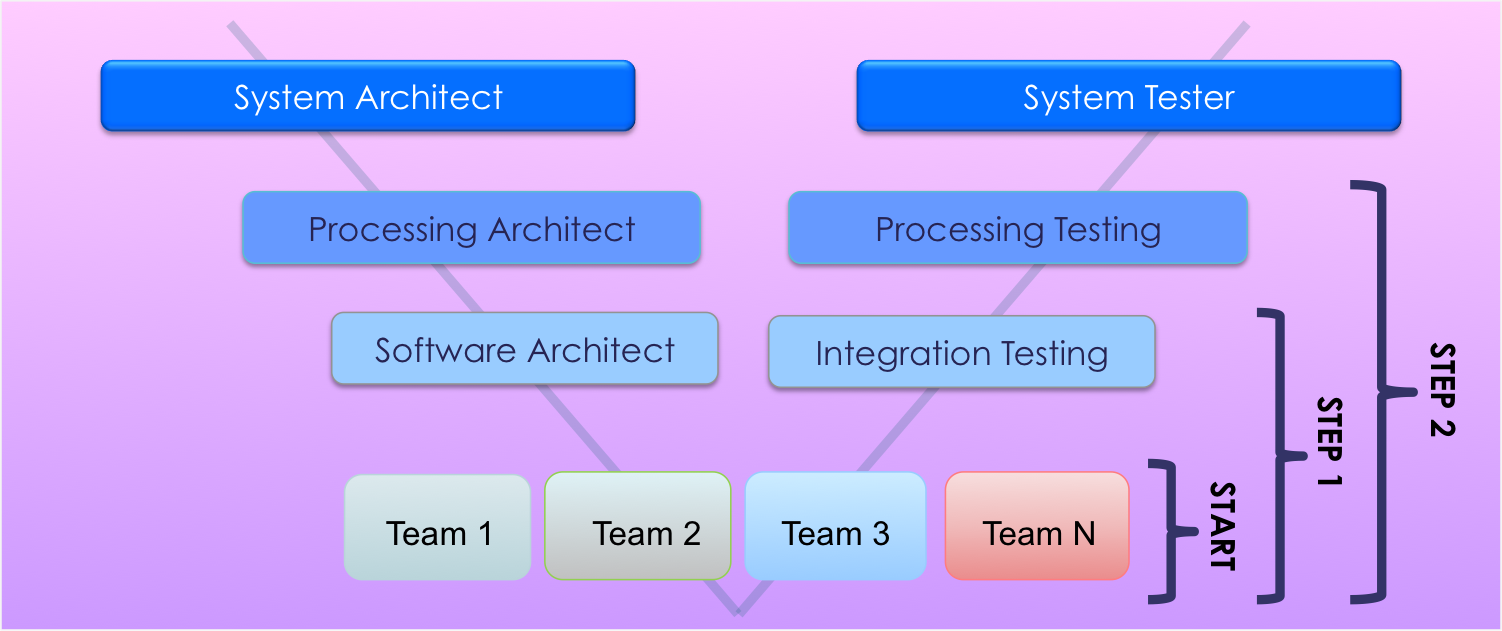
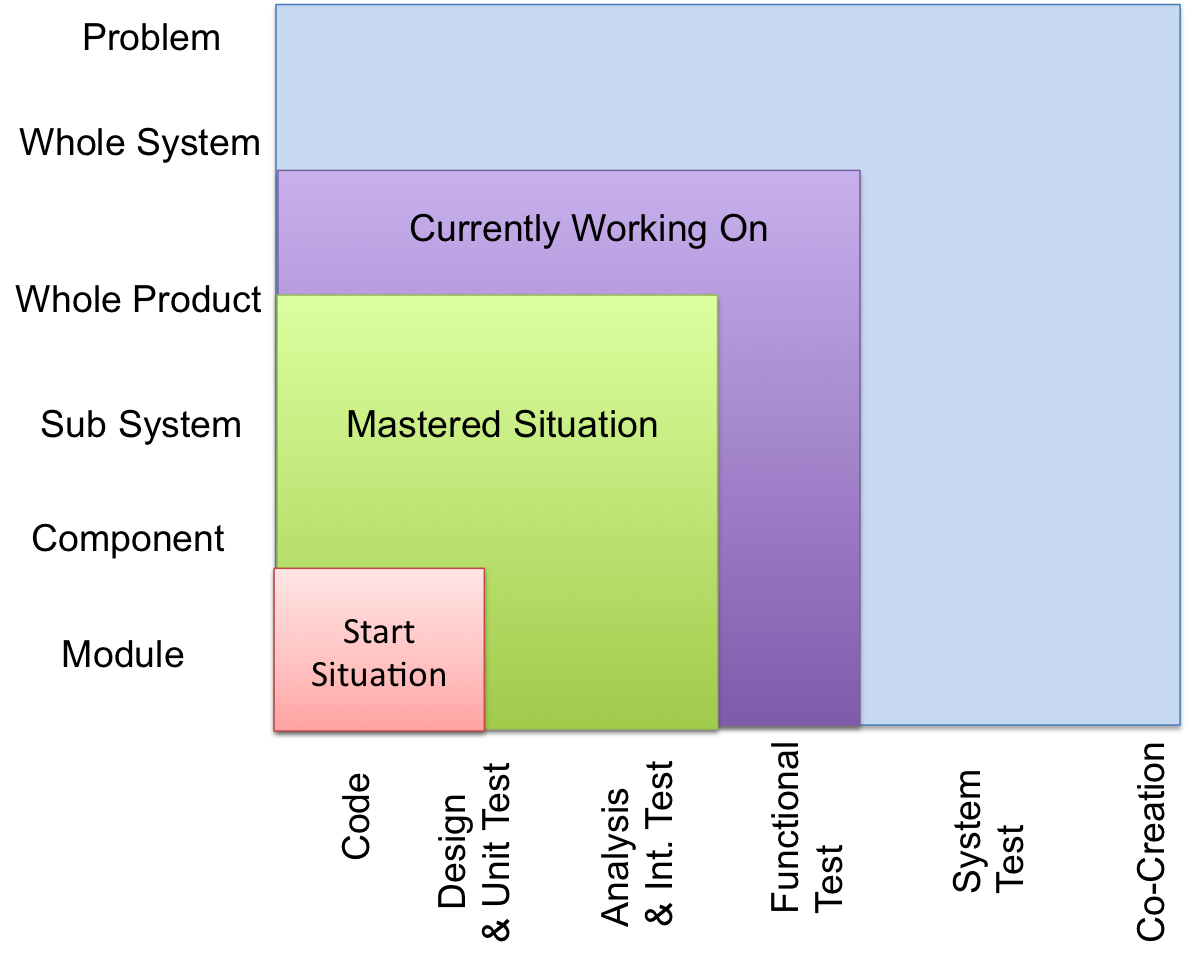
To help understand, discuss, and visualize the upcoming changes in the teams and the Definition of Done you can apply a LeSS tool, a Feature Team Adoption Map 2. With this map you plan the expanded work of your teams along two axis. The first axis is about the activities the team does such as coding, design, analysis, unit testing, integration testing, functional testing and so on. The second axis shows the architectural scope of the teams, such as including subcomponent, component, subsystem, whole product, whole system and so on. An increase “up” in the V-Model increases both the scope and the activities of a team.
Realizing Step-1
So what did we do? In order to realize Step-1 - extending the Definition Of Done with integration testing - we decided to scale Scrum to the department level. That meant to deliver an integrated product every Sprint. Therefore, all teams need to work from one Product Backlog and have one Product Owner. Furthermore we did not want any handovers anymore to the integration team and we also did not want the line managers being intermediaries between the customers and teams anymore.
Cross Component Teams
Next to this the single component teams became cross-component teams. Meaning that teams started learning about- and working in two or more components instead of just one component.
All of these changes meant that we changed to a networked organizational structure1 as depicted below:
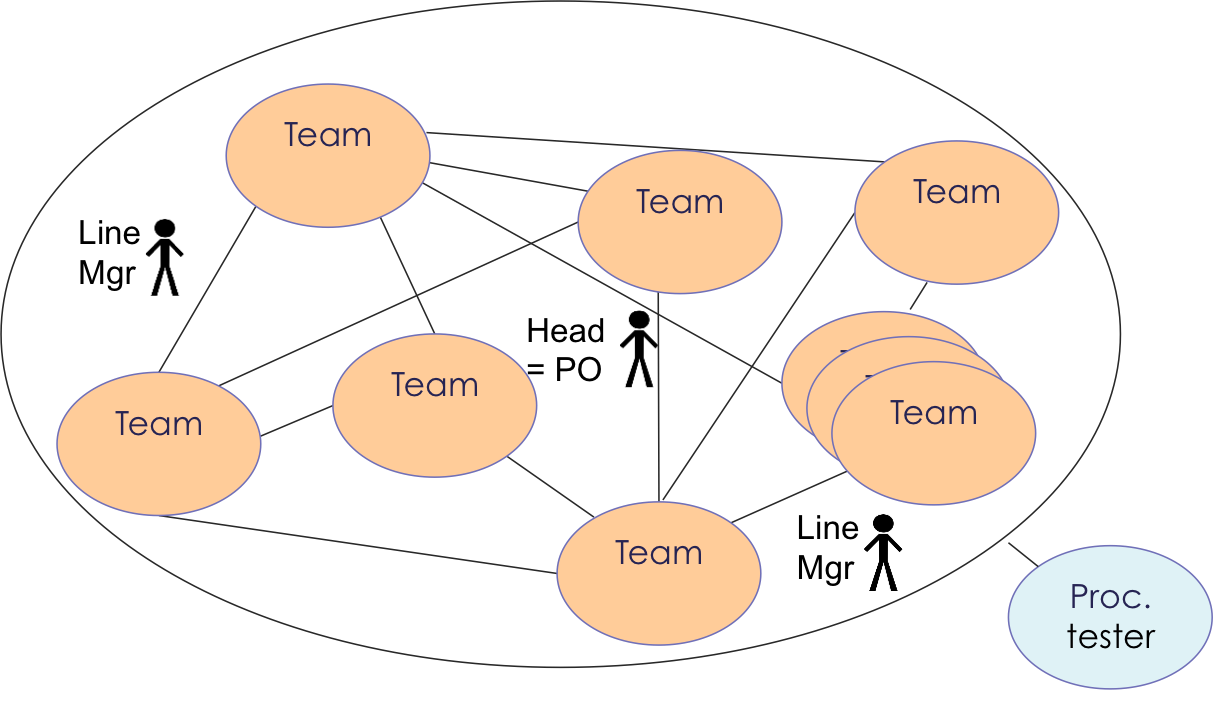
This structure change meant that:
- The hierarchy was reduced and a more networked interaction pattern was used.
- The department head became the temporary fake Product Owner (PO) of the Processing product. We understood that this was not an ideal situation because there was still the “Contract/Commitment Game” and the “PO” did not have the real authority of a PO as defined in Scrum. We realized that the real PO needed to come from Product Management, but this was good enough to start with.
- The so-called team-level “PO manager” role was removed. Some managers left while other picked up a coaching role outside of the teams. The line managers now focus on coaching the relationships between the people, teams and the customers.
- The teams now have more and more responsibility to integrate the software and there are less handovers to the integration team. The integrators became part of the teams.
So there was improvement but there was still an old lingering culture of single-specialists, “special people”, and seniors representing teams. Therefore, this still reinforced invisible hierarchies with handoff problems and inhibited real self-managing teams and multi-skilling and a culture of just team members. In fact these “special people” were even still called “Product Owners” by virtue of attending refinement meetings (rather than the whole teams), showing that the group still had a long way to go to improve from the old habits.
Specialized roles remain
Project management and even line management are involved still in day to day work.
The old role matrix of specialized roles of for example domain architects, project architects and integrators still exist in the formal function house. Although they still exist the expectations of the roles changed drastically. Apart from the project architects, the people playing those roles are now full time part of a team as a regular team member.
The project architects are not part of a regular team because of their unique expertise and work. Lets take system testing for example. For a full blown system test you could need helicopters, fighter jets, surface to air missiles and so on. The preparation and coordination of such a test requires the expertise and time from a project architect.
A broader product definition
One problem that needed to be solved was the problem of prioritizing the various customer requests. On average there are around three products being developed in parallel. The product of the department is the radar sensor. It can be custom tailored for various customers and needs to be supported for decades. Although these are different products from the customer’s point of view, internally the products had very much in common, and were part of a product line. The products have a shared codebase, are developed by the same people and contain a high degree of the same code.
Therefore, we decided to apply the LeSS approach of defining products broader: from the internal Thales viewpoint the product would be defined as one instead of multiple products. This broader definition enabled the PO to do fine grained prioritization. How? Instead of prioritizing a particular customer and its set of features in a batch, the PO could now prioritize fine grained features across customers. This flexibility allowed the PO to increase customer value by not working on low-level features. In addition to a broader product definition helping realize this improvement, it this was made possible (or at least, much easier) by the expanding Definition of Done for the teams, with their expanding scope.
Fine-grained ordering of the product backlog became possible because of a broader product definition.
The Product Owner: Prioritisation over Clarification
The overall PO is not an expert on all the requirement details and cannot clarify them in detail. Furthermore, the vast number of features is too much for one person to handle. Therefore, we applied the LeSS approach that the PO focus is on identifying where the value is and then prioritizing the most valuable features to work on.
And on the other hand, the detailed clarification of the features is left to the teams to figure out directly with the customers. This approach was now possible because the intermediate line managers were removed.
Things were improving!
Learning with Optimization Communities
Adopting large-scale Scrum is a challenge to which the details of the solution cannot be known a priori as every organization is unique. The best approach is therefore for the teams to learn and discover their own path by continuously performing experiments using the PDSA cycle.
The people that do the actual work are in the best position to do the experiments and learn.
The learning of the teams is shared laterally in the organization by forming what we called “Optimization Communities”, which are communities of interest, a common element in a LeSS organization. Certain people from the Scrum teams formed into Optimization Communities to discover what to change and how to change it across the department. Various Optimization Communities were formed on e.g. Scrum Mastership, agile testing, test automation and craftsmanship. Mostly the people doing the real work in the development teams take part in the optimization teams. But optimization communities are open to anyone who wants to learn and share knowledge to define good practices for teams to use within the specific Thales context.
A community is not a separate dedicated team; it is people with a shared interest from development teams. They also apply some Scrum practices: they have a backlog of goals (e.g., “define a standard”, “improve the build server”), a backlog owner who prioritizes it, and one of the regular Scrum Masters helps the community work and improve. The source of requests for the backlog is team members, the PO, or other managers.
A LeSS Sprint at Scale
You need to have an integrated increment in order to add value to your stakeholders and provide transparency about where development is at. Therefore, as per LeSS, all teams work according to a shared definition of done at the product level.
One Product means one Definition of Done
This definition of done includes for example that the increment is deployed on target, features are integration tested, components are functionally tested, all documents are up-to-date and in compliance with our quality standards. And as per LeSS, individual teams can extend this minimal overall definition of done with specific items they need.
The Sprint follows the LeSS organizational design system.
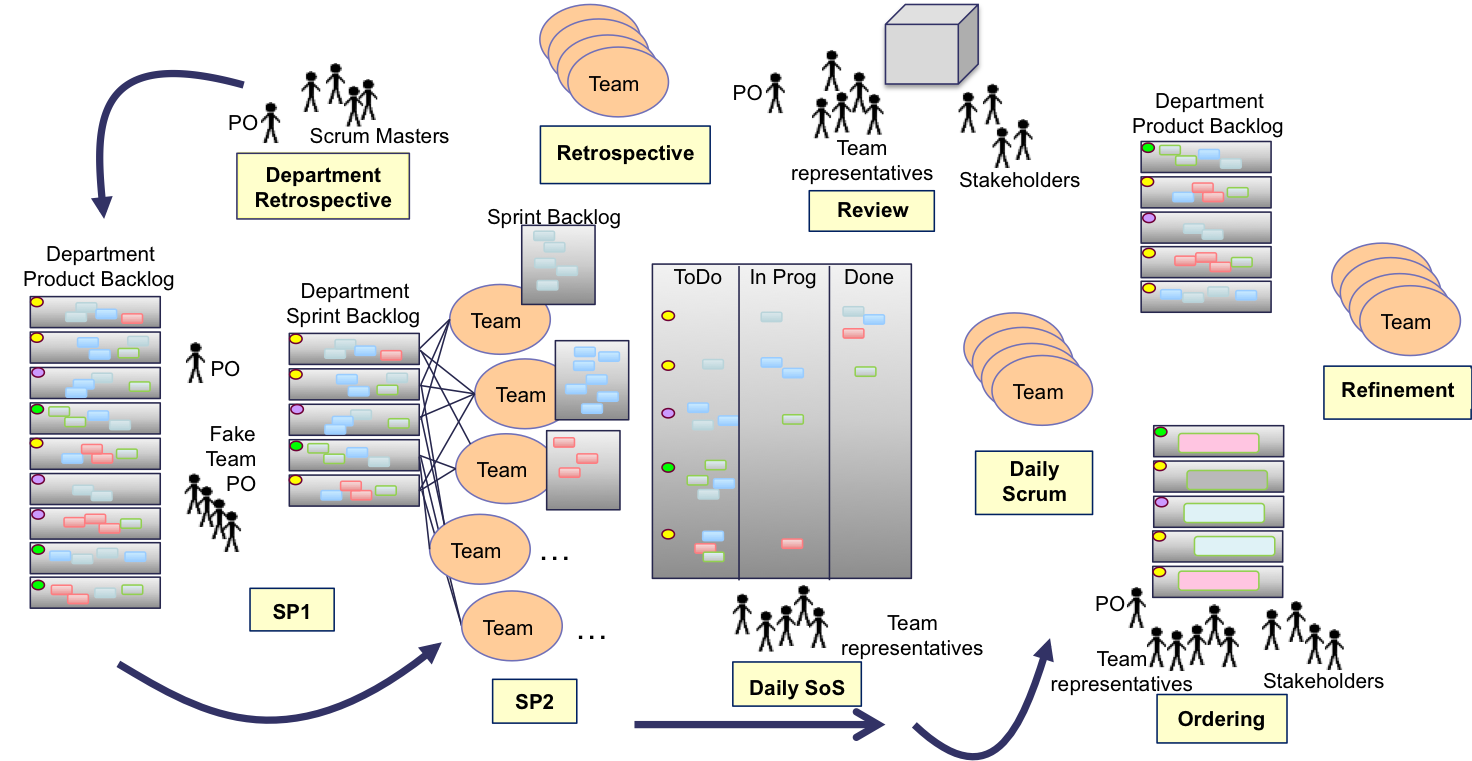
The details of the Sprint are described below. The figure gives an overview.
As per LeSS, the Sprint starts with a large Sprint planning that is broken up into two parts. The first part is for discussing the Sprint goal and which features are needed and is attended by the PO and team representatives. The second part of the Sprint planning is about making a detailed plan for each feature. The teams themselves do this. Most dependencies are identified in Sprint planning part 1. In case new dependencies are identified during Sprint planning part 2, the teams find each other to discuss them. Please find the details below.
In the Sprint the teams synchronize daily using a Scrum of Scrums (SoS). The teams have their SoS in front of the department Scrum board. After the SoS each team has its own Daily Scrum. During the Sprint various refinement meetings order and refine the top of the product backlog.
There is one Sprint review where the PO, stakeholders and team representatives discuss e.g. the increment, future sprints and impediments.
The Sprint is closed with each team having an individual retrospective. Finally there is an overall retrospective with the Scrum Masters of each team and the PO to discuss cross team and organisational improvements.
Sprint Planning at scale
One Sprint planning starts the Sprint. Running a Sprint planning for 70+ people is quite a challenge. At first a lot of time was spent on discussing details that were interesting to only a few of the people present. The meeting was not effective and the scaling of Scrum was beginning to be seen as an inefficient way of working.
It was then decided to better prepare for Sprint Planning, invite less people and break it into two parts
Better preparation
- All features that are candidate to be in the Department Sprint are properly refined before Sprint Planning. A Definition Of Ready was introduced. This reduced indepth discussion at Sprint planning.
- The Product Owner works with Scrum teams’ stakeholders to order the Product backlog before Sprint planning, so that the most valuable work is at the top. For example “Remove windmills interferences” or more at the beginning of development “All components are connected and run on target”.

Break Sprint planning into two parts
The Sprint Planning meeting at large was also split into two parts.
In the first part, the PO and Scrum team representative’s discuss the Sprint Goal and discuss and select the features to work on. The discussion ends when one of the teams becomes fully loaded. We use an overall velocity for this that is based on the average number of features all the teams can deliver in a Sprint.
In the second part of Sprint planning the teams create their Sprint backlog. The team representatives take the features to their teams so that they teams can figure out what they need to do to realize the features.
In more detail.
Sprint Planning Part I
Next to the standard activities of a Sprint Planning, the focus is on selecting the right set of product backlog items for all teams and identifying dependencies between the teams. The Sprint Goal is leading in selecting the work to do. The teams pull from the top of the backlog into their own Sprint backlog. As the teams pull the items their remaining capacity decreases until there one of the teams becomes fully loaded. At that time all teams stop pulling new work. During refinement most dependencies between the product backlog items have been identified. Now with the dependency information and the teams pulled Sprint backlogs, the teams try to improve the plan to best meet the Sprint Goal. The teams do this by rearranging the order of the items, or evenby moving items between teams. The next step is for the teams to create their Sprint Backlog.
Sprint Planning Part II
Now that the work is distributed across the different development teams each development team individually plans their Sprint and creates a Sprint backlog. In case of emergent dependencies between the product backlog items, the teams just go talk to each other.
Key lesson learned was to focus on optimizing for flow instead of optimizing for resource utilization.
This may sound trivial for some people, but it was a big shocker for most teams as the teams always had a strict focus on their components only. People and teams were used to be loaded up-to 100% of their capacity. In the new agile setting the teams were expected to deliver an integrated product across all teams every Sprint. And this meant that people and teams are not necessarily planned to capacity.
Coordination with the Scrum of Scrums
Every day the various teams organize themselves around the department Sprint Board in a Scrum of Scrums with team representatives. It started out with having this coordination session twice a week. It turned out that this was not enough as things moved too quickly and people were not used to working towards a common Sprint goal. Therefore the teams decided to have the meeting on a daily basis. They have it every day for about two years now and it is still valuable. Having this daily meeting creates transparency on overall progress, emerging dependencies and also maintains a joint focus for achieving the overall Sprint Goal. The Scrum of Scrums is done in front of a big wall that has the features to do this Sprint. In this backlog you can see which teams are working on which features and their progress. You can also see the stories for each feature and the dependencies between them. Below you can see an example of the department Scrum board. It is here where the teams identify and plan how to help each other and resolve inter-team dependencies and impediments. Next to this Scrum of Scrums, the individual Scrum teams have their own Sprint backlog and also have their own Daily Scrum.
The teams manage their own dependencies at the daily Scrum Of Scrums
Next to team representatives, line management and project management also attend to be updated on impediments that they can help with. Having a Scrum of Scrums at large with lots of people introduces the risk that the meeting will turn into a status meeting instead of a work session. Good facilitation from the Scrum Master prevented this from happening.

Backlog Refinement at scale
At least two times per Sprint project architects and team representatives come together to refine the top of the product backlog’s features for the individual Scrum teams.
After the features are broken up into smaller item, it is clear which team will do which item. Therefore, the individual teams can refine their items independently of each other in their own refinement sessions so that the top of the product backlog is ready before Sprint planning. So there are refinement workshops for features at the department level and refinement workshops for items at the individual team level.
Architecture & Design
The change to developing a working product every 4 weeks was a big shock. The mindset of being accountable for delivering an integrated product was not there because people were used to delivering only a component. The change from “we need everything before we can test and say if things are working” to identifying what minimal slices of functionality you actually need to create feedback was huge.
Another problem had to do with the architecture. It is a component architecture with huge interfaces that break easily. Remarks like the following were said often
- “How on earth can we deliver something that works in 30 days that is also useful?”
- “We cannot calculate anything with incomplete or inaccurate data?”
- “What’s the point of making the algorithms if the input data is going to change later?”
Create a walking skeleton as soon as possible to reduce risks.
We started working with the architects and testers. In large story mapping sessions we identified chains through the components and small pieces of functionality that would enable us to create end-to-end working product - value - early on. In the beginning of a project the focus is on creating knowledge value like e.g. reducing technical risks and getting a feel for capacity of the teams. Later in the project, customer value increases, as we are able to deliver end-to-end customer functionality.
In the sessions we asked questions like:
- “What thin layer of functionality would reduce technical risk?”
- “What would be the smallest valuable layer through all or a subset of components?”
- “What data can reduce the risk calculation and measurement risks?
- “What is needed to run the first system tests?”
- “How can we get working product deployed to target that can be tested?”
The breakthrough was realizing that the architectural constraints can be met at a later time and do not need to be satisfied right from the start. For example, it is ok for an input component to directly call the output component bypassing all intermediate components along the way. Once it works and has automated tests around it, you can add the internal components later as more and more functionality is added.
Sprint Retrospective at Scale
Every Scrum team has its own Sprint retrospective where they look at team improvements and team building. It is essential for teams to keep doing this with the people they work with on a daily basis.
In addition to the team retrospectives there is also an overall retrospective to improve the performance of the department as a whole. The PO and the development teams’ Scrum Masters attend. In this working session problems with the adoption and also impediments in development that the teams cannot solve themselves or that have cross Scrum team impact are discussed.
Sprint Review at scale
At the end of every department Sprint there is one big Sprint Review. The department Product Owner and the external stakeholders inspect the achievements of the last sprint. The PO also presents the current department Product Backlog and uses the department Sprint velocity to relate this to the overall radar system development milestones. This gives the stakeholders the opportunity to take action if certain important milestones might not be met.
The Sprint Review usually ends with the demonstration of one or a few realized features. In the beginning of development the demonstrations are very technical. In these cases the demonstration is limited to senior experts who can actually understand what is being shown and provide feedback on for example the correctness of for example a waveform.
For practical reasons, the invitees are limited to the roles mentioned. However, the day after the Sprint Review, the PO updates in a 15 minutes session the whole department on the highlights of the Sprint Review session.
Change to Servant Leadership
In the first weeks of the adoption management was discovering their new role. Management started with separate management sessions to discuss organizational impediments. They did see, discuss and delegate solving to others in the department. After a few sessions the department head and his managers realized that they should not be delegating but rather be helping to solve the impediments.
Management understands the problems at the work floor through first hand observation.
Some managers started visiting the department Daily Scrum. They started solving impediments on a daily basis. The teams welcomed their commitment and transparency and as a result the teams had more respect and appreciation for the efforts of management. It is not that they started writing code but rather actively worked on solving impediments and thoroughly understanding the problems of the teams.
Line managers become coaches.
Before the Scrum adoption, each component team had a line manager responsible for the Scrum teams’ success. Next to that line management was also responsible for coordination, people management, appraisals and budgeting. During the Scrum-but phase, the line manager was also responsible to maintain the Scrum team’s (fake) product backlog for their component and decide on priorities as far as it did not affect the department Sprint backlog. This mix of responsibilities decreased ownership in the teams and inhibited self-organization.
All people in the Scrum team are peers, there is no difference in authority.
The improvements in the adoption of Scrum led line management to take a step back from the daily coordination and to pick up more of a team coach role. Management stopped working the backlogs and interfering with the details of the work. Their focus moved to ensuring the teams would never be blocked, and to coaching them on problem solving and improvement. For example, a team was having trouble resolving an internal conflict about how to handle disturbances and interruption from higher ranked people and other departments. The team members felt uncomfortable rejecting these people. A line manager had various coaching session with the teams and its members to develop communication skills and clear thinking to handle such requests. Line management also had various session with the people making the requests so that they realized the impact their requests were having on the teams’ performance. Nowadays the teams are able to handle any requests from outside.
What are the results?
The benefits so far
- As hoped with the introduction of Scrum and then towards LeSS, TU Processing achieved that the various stakeholders have clearer and more reliable steering information. Not only for the current Sprint but based on the feature point backlog estimation and the velocity, also for the future deliveries. This enables them to act on this.
- Also the expected knowledge sharing was achieved. The number of critical individuals is reduced. In addition the unexpected disturbance for key individuals is significantly reduced which make that they can work more focused in the Scrum teams.
- In addition, now the whole department focuses on the highest priority work, on the next delivery.
- Over a period of two years the number of people in the integration team have gradually been reduced. They either joined a regular Scrum team or started acting as coaches to raise awareness of dependencies and help integrating the work of the various teams. The goal is that the integration test team will eventually cease to exist as a separate team, but if that is the best solution remains to be seen.
- Last but not least, the quality of the work has increased. As a concrete example the integration of the integrated processing chain on the radar system could be achieved in a few days instead of numerous weeks. The total number of defects found after delivery has also decreased significantly.
Progress in agile engineering practices
Agile development only works with the right engineering practices in place. Moving to agile development means delivering high quality software every Sprint. Software that can be changed fast and at low cost. The introduction and further use of practices like pair programming, test driven development, automated testing, continuous integration and shared code ownership were an essential first step to produce working product across all teams every Sprint.
Some remaining problems
Unnecessary Coordination
The different teams are not full feature teams yet. Especially in the beginning of a project when for example the electronics, the analog parts and the hardware is being developed. There is for example an FPGA component team and they do not work on end-to-end sensor features. On the other hand, there are teams that are heavily mathematics focussed. These teams focus on tracking and grouping information over scans or work on trajectory prediction. These teams do work on customer centric features. Furthermore, we see that once there is a minimal working processing chain, more and more teams can work on customer centric features.
Developing Low Value Features
None the less, over the whole development cycle quite some features still need more than one team to deliver it. Therefore, the teams still needs lots of coordination and their dependencies need to be managed at the features level. The good point is that the teams themselves now manage these dependencies at the level of requirements and also at the code level.
What are the current steps we are working on?
Increase Cross Component Teams
Most teams already work on more then one component. The current challenge is to increase the number of components being worked on by a single team. It is very unlikely that in the future a single team will be able to work in all components. But at this moment we feel that we can still benefit from an grow cross component knowledge in teams.
Increase Whole Product Focus
The challenge is to move towards better feature teams. One step is to increase the teams’ Definition Of Done with Processing testing so that they are available to deliver more customer centric features. At this moment the processing testing is done by a separate team still.
Introduce Team based incentives
To increase the teams’ focus on teamwork and cooperation, the current individual incentives are not enough. Experiments to introduce a team based incentive system where not only individual performance but also the importance of team performance is promoted are being done.
Product Owner from Product Management
The current product owner is actually a Temporary Fake Product Owner that does not collaborate with the end customers. Obviously this is not ideal. The good thing is that the actual prioritization is more and more done by a person at the program level. And this is a good thing because he has a focus across all the disciplines of software hardware, mechanics etc. Finding the right PO is still ongoing.
References:
- 1. Cesario Ramos., 2014. EMERGENT - Lean & Agile adoption for an innovative workplace., CreateSpace Independent Publishing Platform.
- 2. Feature Team Adoption on LeSS Site.
About the authors
Cesario Ramos
Sandra Roijakkers
Sandra graduated in Mathematics, and worked for over 10 years in various research projects in defense mission management and telecommunications. She gradually moved from doing technical work herself to project management and later on line management. She currently works as cluster manager at Thales, and she believes that the empowerment and stimulation of a team of capable people is the key to success