Flow & Queueing Theory
The joy of engineering is to find a straight line on a double logarithmic diagram.
—Thomas Koenig
Queueing theory offers insight into why traditional development is unnecessarily slow—and what to do about it. In large-scale development, it’s common that ‘one’ feature (before splitting) is staggeringly gigantic. In such domains, it is particularly helpful to see that large batches and long queues actually exist and the problems they cause. It’s hard to fix a problem you don’t know you have. And queueing theory points to some ways to improve. This thinking tool is especially relevant for the large scale because big variable batches of work—so common in the traditional model—have a nonlinear impact on cycle time—they can really mess things up,

An interesting incongruity: Queueing theory—the mathematical analysis of how stuff moves through a system with queues—was developed to understand and improve throughput in telecommunication systems—systems with lots of variability and randomness similar to product development. As a consequence, telecommunication engineers understand the basic insights. And yet, telecom infrastructure development people (telecom is a domain of large products) rarely see that it applies to their system to reduce the average cycle time in their development processes.
Toyota people learn about statistical variation and the implications of queueing theory; this is reflected in the lean leveling principle to reduce variability and more generally in the lean focus on smaller batches and cycle times to move toward flow.
Before diving directly into the subject, note that lean is sometimes described as focusing on smaller batch (work package) size , shorter queues , and faster cycle time . Delivering value quickly. Lean is much more than this—the pillars are respect for people and continuous improvement resting on a foundation of manager-teachers in lean thinking. Queue management (WIP limits, …) is useful but is a mere tool far from the essence of lean thinking.
As will become evident, LeSS supports the management implications of queueing theory.
Little’s Law Myth Alert
Before getting deeper into queueing theory, there’s a widespread queueing-theory-related myth promulgated in the lean and agile development community (even in some scaling approaches), that should be cleared up quickly. You can find a gazillion article’s claiming that Little’s Law proves that reducing WIP levels will reduce average cycle time. Oh but were it so! Unfortunately, Little’s proof is dependent on a set of conditions/assumptions which must be true for the dynamic to hold true. And unfortunately, those conditions are in no way guaranteed to be or even commonly true in high-variability domains such as software development. The naive promotion or justification of Little Law’s in software development is well deconstructed in Daniel Vacanti’s analysis called Little’s Flaw.
Reducing WIP levels is a worthy goal and important in LeSS. WIP is one of the wastes in lean thinking, because it delays a return on investment, hides defects, reduces transparency, among other problems. And reducing WIP levels exposes weaknesses. But, unfortunately, there is no guarantee in software development that reducing WIP will automatically reduce average cycle time.
Compete on Shorter Cycle Times
A lean product development organization is focused on value throughput in the shortest possible sustainable cycle times , focused on the system throughput rather than the busyness of people. Toyota people, the progenitors of lean thinking, are masters of faster and faster (shorter) cycle times without overburdening people.
What are some process cycles or cycle times in product development?
- “concept to cash” for one release
- “concept to done” for one feature
- potentially shippable time; how frequently could you ship?
- compile time (of all the software)
- “ready to pilot” to delivery time
- deployment time for testing (into embedded hardware)
- analysis and design times
Key performance indicators (KPIs) in lean are not focused on the utilization or busyness of workers doing these processes. Rather, lean KPIs focus more on throughput cycle times.
That said, a caution: Measurement usually generates dysfunction or ‘gaming’ of the system by sub-optimizing to appear to achieve a good score [Austin96]. This is especially true on ‘lower’ process cycles. Higher-level cycle times such as potentially shippable cycle time and “order to cash” or “order to delivery” (the quintessential cycle times) are most relevant.
What would it mean if you could deliver in half or a quarter of the time at a sustainable pace without overburdening people? And on the other hand, what is the cost of delay?
Consider the benefits of delivering fast in terms of life cycle profits, opportunities gained, response to competition, and innovation. For most companies—not all—it would be an extraordinary advantage.
Half the time is not half the cost—When people hear “half the time” they may think, “Twice as many products, features, or releases—twice the old efficiency.” But there could be more transaction cost, the overhead for each cycle. Shipping more frequently might increase testing or deployment costs—or not, as will be seen.
Half the time is not twice the cost—Before you put away your spreadsheet on the transaction cost analysis, hold on. There is a subtle connection between cycle time, transaction cost, and efficiency that will soon be explored—a secret behind the impressive efficiency of Toyota and other lean thinking enterprises…
Queue management—There are plenty of strategies to reduce cycle time; both lean and agile practices offer a cornucopia of skillful means. One tool is the subject of this section—queue management.
Queue Management to Reduce Cycle Time
“Queues only exist in manufacturing, so queueing theory and queue management don’t apply to product development .” This is a common misconception. As mentioned, queueing theory did not arise in manufacturing but in operations research to improve throughput in telecom systems with high variability. Furthermore, many development groups—especially those adopting lean or agile practices—have adopted queue management based on queueing theory insight for both product development and portfolio management . One study from MIT and Stanford researchers concluded:
Business units that embraced this approach [queue management for portfolio and product management] reduced their average development times by 30% to 50%. [AMNS96]
Queues in Product Development and Portfolio Management
Example queues in development and portfolio management?
- products or projects in a portfolio
- new features for one product
- detailed requirements specifications waiting for design
- design documents waiting to be coded
- code waiting to be tested
- the code of a single developer waiting to be integrated with other developers
- large components waiting to be integrated
- large components and systems waiting to be tested
In traditional sequential development there are many queues of partially done work, known as work-in-progress or WIP queues; for example, specification documents waiting to be programmed and code waiting to be tested.
In addition to WIP queues , there are constrained-resource or shared-resource queues , such as a backlog of requests to use an expensive testing lab or piece of testing equipment.
Queues Are a Problem
First, if there are no queues—and no multitasking that artificially makes it appear a queue has been removed—then the system will move toward flow, the lean principle and perfection challenge that value is delivered without delay. Every queue creates a delay that inhibits flow. More specifically, why are queues a problem?
WIP Queues
WIP queues in product development are seldom seen as queues for several reasons; perhaps chief among these is that they tend to be invisible —bits on a computer disk. But they are there—and more importantly they create problems. Why?
WIP queues (as most queues) increase average cycle time and reduce value delivery, and thus may lower lifetime profit.
In lean thinking, WIP queues are identified as waste —and hence to be removed or reduced—because:
- WIP queues have the aforementioned impact on cycle time.
- WIP queues are partially-done inventory (of specifications, code, documentation, …) with an investment of time and money for which there has been no return on investment.
- As with all inventory, WIP queues hide—and allow replication of—defects because the pile of inventory has not been consumed or tested by a downstream process to reveal hidden problems; for example, a pile of un-integrated code.
- A story: We saw a traditional product group that spent about one year working on a “deal breaker” feature. Then product management decided to remove it because it threatened the overall release and the market had changed. Replanning took many weeks. In general, WIP queues affect the cost and ability to respond to change (deletions and additions) because (1) time and money were spent on unfinished deleted work that will not be realized, or (2) the WIP of the deleted item may be tangled up with other features, or (3) a feature to add can experience a delayed start due to current high WIP levels.
As will be explored, there is a subtle but potentially powerful systems-improvement side effect that can occur through the process of eliminating WIP queues.
Shared-Resource Queues
In contrast to WIP queues (which are not seen for what they are), shared-resource queues are more often seen as queues—and seen as a problem. They clearly and painfully slow people down, delay feedback, and stretch out cycle times. “We need to test our new code on that target printer in the test lab. When will it be free?”
Plan A: Eliminate (rather than manage) Queues
The bottom line is that (usually) queues are a problem . Given that, you may jump to the conclusion that the first line of defense against this problem is to reduce the batch and queue size , because these are classic queue-management strategies. Yet, there is a Gordian Knot solution that should be considered first…
The remainder of this chapter will indeed explore reducing cycle time through batch- and queue-size management. But that entire management strategy should be Plan B. Rather, start with Plan A:
Plan A in fixing the queue problem is to completely eradicate the queue, forever, by changing the system: the system of the organization, the system of development, tools, processes, practices, policies, etc.
Think outside the current box and shorten cycle times by changing the system so that queues no longer exist—by removing bottlenecks and other forces that create the queues. These constraints and the queues they spawn may be created or eradicated by the very nature of a development system and its tools.
Suppose the existing system is based on sequential development with single-specialist/function workers or groups. There will be WIP queues: The analyst group hands off specification work packages to the programming group that hands off code work packages to the testing group that hands off code to a deployment group. An inside-the-box response to improving with queue management is to reduce WIP limits and queue sizes. But that approach is merely dealing with the secondary symptoms of the existing system.
There is a deeper alternative that will more dramatically improve cycle time: Discard that system and the bottlenecks and WIP queues it spawns. If you adopt cross-functional feature teams that do complete features (analysis, programming, and testing) without handing off work to other groups, and that apply automated acceptance test-driven development and automated continuous deployment, the above WIP queues vanish by moving from serial to parallel development.
This approach reflects the fix-the-root-causes vision of LeSS: Change the organizational design to address the core problems.
Fake Queue Elimination
Suppose you are busy working on item A, and items B, C, D, and E are in your queue. Fake queue reduction is to work on all these items at more or less the same time—a high level of multitasking and utilization. Multitasking is one of the lean wastes because as will be soon seen, queueing theory shows that this would increase average cycle time, not reduce it. And that fake approach actually increases WIP, in the name of reducing it! Bad idea.
Do not increase multitasking or utilization rates to create the illusion that queues have been reduced and the system has improved; rather, improve the system so that the bottlenecks and other forces that create queues are removed.
Plan B: Manage Queues When You Can’t Eliminate Them
Traditional WIP queues can be eliminated by the move to LeSS with cross-functional feature teams, the use of acceptance TDD, and continuous deployment. Banished and vanished via Plan A—change the system. That’s the ideal solution recommended in LeSS.
Still, queues can and do remain, such as:
- shared-resource queues, such as a testing lab
- the queue of feature requests in the Product Backlog
- WIP queues because (1) Plan A is not yet possible (deep change in large groups takes time), or (2) tools and techniques, such as moving from manual to fully automated testing, are weak and slow to improve
Whatever queues remain—and at the very least, the Product Backlog will remain—you can improve average cycle time by Plan B in queue management:
Plan B: For queues that cannot be eradicated, improve average cycle time by reducing the batch size in the queues, reducing WIP limits and queue sizes, and by making each batch more-or-less equally sized.
In LeSS, a smaller batch means a smaller work package of items or features to develop in a Sprint. Equally-sized batches imply that each is estimated to be roughly equal in effort.
Concretely, how to apply this in LeSS? That will be explored later, but first, on to the field of queueing theory…
Queueing Theory
It might take hard work or a new perspective, but it doesn’t take much theory to “manage queues” by eradicating them. On the other hand, when they must still exist, it is helpful to know how to deal with them with the thinking tool of queueing theory.
A Formal Model for Evaluating Processes
You may accept at face value that queues with smaller feature-batches of equal size improve average cycle time. Or not. In any event, it is useful to know that this suggestion is not based on opinion but is grounded in a formal mathematical model that can be demonstrated. It is possible to reason about some aspects of a development process, using a formal model. For example:
- Hypothesis : It is fastest to do sequential (‘waterfall’ or V-model) development with large-batch transfers between groups.
- Hypothesis : It is fastest for people or groups to have high utilization rates and multitask on many projects at the same time.
An understanding of queueing theory, independent of opinion, can reveal if these hypotheses help reduce average cycle time.
The topic is relatively simple; a scenario captures key elements…
Qualities of a Stochastic System with Queues
Consider Los Angeles or Bengaluru at rush hour. By some miracle there are no accidents and all lanes are open. Traffic is tight and slow, but moving. Over a short period of time, there are accidents on three different major four-lane highways (twelve lanes), and three lanes are closed—only nine lanes are still open. Boom! Before you can say, “Why didn’t I buy a helicopter?” much of the city does a phase shift into gridlock . When the accidents are finally cleared (ranging from thirty to sixty minutes later), the massive queue buildup takes forever to clear. Observations:
- Nonlinear—When the highway is from zero to fifty percent loaded, it is smooth sailing—virtually no queues or delays. But between fifty and one-hundred percent, slowdown becomes noticeable, queues build up. The relation of utilization to queue size is nonlinear, not a smooth linear increase from zero.
- Delay and overload does not start at 99.99% utilization—It is not the case that everything goes fast and smooth on the highway until just before 100 percent capacity of cars on the road. Rather, things slow down and gridlock happens well before capacity is reached.
- Clearing the queue takes longer than making it—Forty-five minutes of blockage in Los Angeles at rush hour creates queues that take more than forty-five minutes to clear.
- Stochastic, not deterministic—There is variation and randomness with probabilities (it is astochastic system): arrival rates of cars, time to remove blocks, exit rate of cars.
This is worth spelling out if you wish to grasp how systems behave, because it seems all us humans do not have an intuitive sense of the stochastic and nonlinear quality of systems with queues. Gut instinct may be that they are deterministic and behave linearly. This incorrect “common sense” leads to thinking mistakes in analyzing problems and managing product development. These observations—and thinking mistakes—apply to WIP queues in traditional product development and to virtually all other queues.
One common thinking mistake in product development is that the queues, delay, and the people that serve them behave as in Figure 1—the misunderstanding of “delay only starts when the highway is 100 percent full. ” But slowdown starts happening on the highway long before it is 100 percent full. Perhaps at 60 percent capacity, you start to notice slowdown—a longer average cycle time.
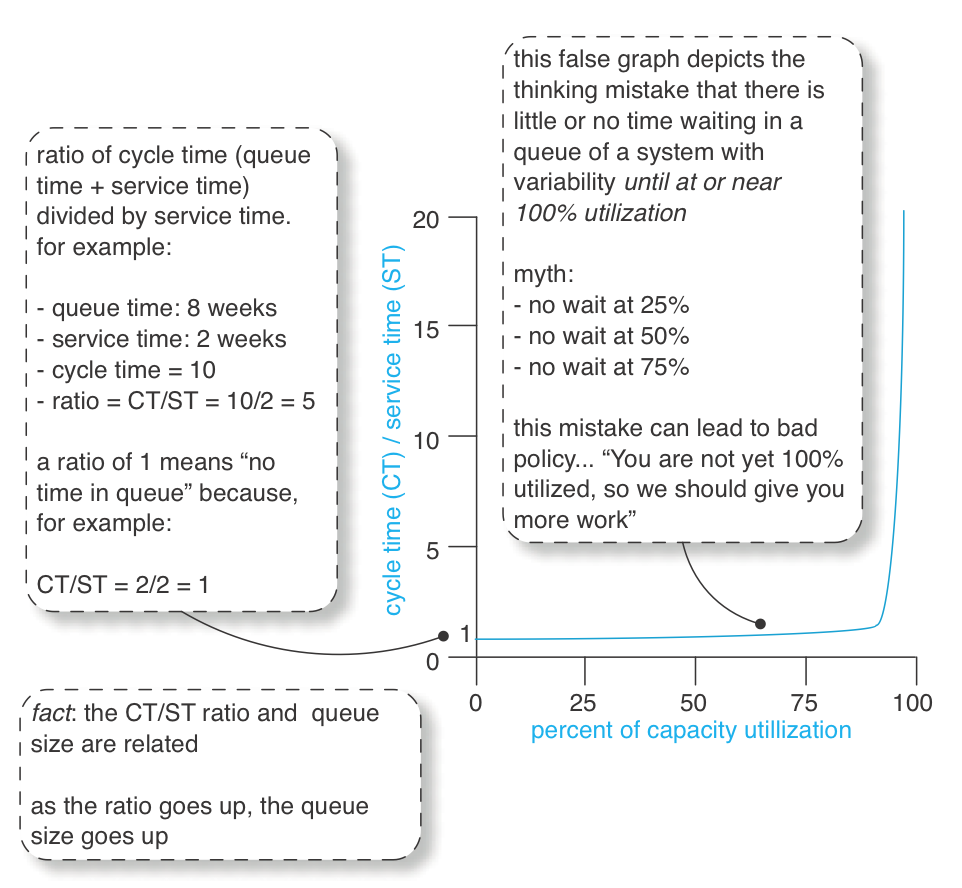
With the misunderstanding “delay only starts when the highway is 100 percent full, ” there is a misguided focus on trying to improve cycle time by increasing resource utilization—getting the people in product development to be more busy, usually by more multitasking. This is the local-optimization thinking mistake.
What really happens to average cycle time when one increases the utilization level of things or people in a system with variability?
At Xerox they have expensive, large digital print presses in a test lab. There is often a shared-resource queue of testing requests for one of these devices. Without understanding how queues really work (that is, believing they work as in Fig. 1) the management approach would be to encourage that these expensive systems are reserved and utilized close to 100 percent of the time. But the reality is that there is variability all over the place—a stochastic system. Tests arrive randomly, some fail quickly, some take forever to complete, sometimes the equipment breaks, and so forth. This same variability of behavior applies to people and the queues of work that they work on .

Modeling a Basic Single-Arrival System with Queues
How do these systems behave—in traffic, test labs, or traditional development with people working on WIP queues? You have a sense of it from the traffic story. Mathematically, the behavior may be modeled as variations of M/M systems. M/M means that the inter-arrival rate into the queue is Markovian and the service rate is Markovian. (Markovian: A simple concept—a random process with probabilities (stochastic) in which the future state cannot be deterministically known from the present state; that is, similar to “messy reality.”)
A common, basic queueing model is M/M/1/∞ —it has one server (for example, one test printer or team) and an infinite queue. (Development queues are not normally infinite, but this simplification does not impact the basic pattern of how the systems behave.)
Now it starts to get interesting… In a M/M/1/∞ system, how does cycle and service time relate to utilization of the server—be it a test printer or people working on WIP queues? See waiting behavior for a basic M/M/1/∞ system. shows the behavior [Smith07].
These are averages in See waiting behavior for a basic M/M/1/∞ system, because elements have random variability, such as:
- requests arrive at different times with different effort
- tests or programming effort take variable time
- people work faster or slower, get sick, or work longer or shorter

The essential point to grasp is that an item (such as a requirement request) starts sitting in a queue waiting for service long before people are 100 percent utilized. It is also fascinating to see the impact of increased utilization of people on cycle time: As utilization goes up in a system with lots of variability, average cycle time gets worse, not better. This is counterintuitive to an average accountant or management consultant who has been taught to “improve productivity by increasing utilization of resources.” Most have not been exposed to queueing theory—how to understand stochastic systems with queues (people doing work with variability)—and so demonstrate a thinking mistake.
It is this real-world variability that creates, on average, this increased queue size and waiting time in product development.
It is this real-world variability that creates, on average, this increased queue size and waiting time in product development.
Modeling a Batch System with Queues (Traditional Development)
It gets even more interesting (if you could believe that)… The basic M/M/1/∞ system assumes that a single item (for testing, analysis, programming, …) arrives in isolation—that arriving items are never clumped (or batched). Yet in traditional product development, work packages do arrive in big clumpy batches, such as sets of requirements or testing work or code to be integrated. Or an apparent ‘single’ requirement is received such as “handle Brazil-market bond derivatives trades” that is in fact itself a batch of sub-requirements. This last point is very important to note, because a big requirement inevitably does not flow through the system as one work package, although it is incorrectly viewed as one work package “from a distance.”
“One big requirement is itself a batch” is a critical point that will be revisited later.
So, instead of the simpler single-arrival M/M/1/∞ model (a single work item arrives), consider a M[x]/M/1/∞ system (a batch of items arrive). This model is a better analogy to traditional product development.

At first glance, people may not grasp the startling and counterintuitive implication of what just happened to their cycle time.
A scenario may help: Suppose a person or team is currently 50 percent utilized and you usually give them single small-sized requirements now and then that arrive with some randomness and some variability in size. Assume it will take them two weeks of hands-on work to complete a particular requirement-X. And assume it is the simple single-arrival system. As a table, here is an approximation of the average situation:
| Arrival | Utilization | Queue Time | Service Time | Cycle Time | Ratio CT/ST |
|---|---|---|---|---|---|
| single arrival | 50% | 2 weeks | 2 weeks | 4 weeks | 2 |
Next, instead, suppose that you are typically giving the 50-percent-utilized team significantly bigger batches of requirements, or ‘one’ giant requirement that actually encompasses a big batch of sub-requirements; these arrive with some randomness and size differences. Assume it will take twenty weeks of hands-on service time to complete some particular batch-X or ‘single’ big requirement.
Knowing the prior table, this is what some people will predict for big-batch arrivals:
| Arrival | Utilization | Queue Time | Service Time | Cycle Time | Ratio CT/ST |
|---|---|---|---|---|---|
| single arrival | 50% | 2 weeks | 2 weeks | 4 weeks | 2 |
| if big batch? | 50% | 20 weeks | 20 weeks | 40 weeks | 2 |
A gut instinct prediction is a linear increase in the cycle-time impact. Ten times as much work on average being pushed through the system, so ten times the cycle time. Four weeks versus 40 weeks.
But it does not work that way, because more variability is introduced into the system. So what happens?
At 50 percent utilization, the cycle-to-service-time ratio is ‘5’ in the M[x]/M/1/∞ example. This approximates the contrasting situations:
| Arrival | Utilization | Queue Time | Service Time | Cycle Time | Ratio CT/ST |
|---|---|---|---|---|---|
| single arrival | 50% | 2 weeks | 2 weeks | 4 weeks | 2 |
| big batch | 50% | 80 weeks | 20 weeks | 100 weeks | 5 |
Things just got a lot worse. Of course, these are averages and cannot be assumed for any one real case, and this model is a simplified abstraction of development. But this is why understanding—and acting on the insight—of queueing theory is useful for large-scale development, because large systems are often associated with big requirements, and big work (requirements, testing, integration, …) in big batches arriving at variable times, with workers that are expected to be 100% utilized (busy) at all times. That can have an astonishing impact on average cycle time.
So pushing for high utilization rates of workers in this situation with big batches of work is a recipe for… sloooow. The reality will be a super-linear increase in cycle time. This impact on delay and queue size defies our instinct because people are not used to analyzing stochastic systems with queues. One might think, “If I make the work package ten times bigger, it will take ten times as long to exit the system.” Do not count on it.
And these delays are further aggravated in traditional sequential development because there are a series of processes with WIP queues in front of them; this compounds the variability and adds more negative impact to the overall average cycle time. The Law of Variability Placement [HS08] reveals that the worst place for variability (in terms of negative cycle-time impact) is at the front end of a multi-stage system with queues. This is what happens in phase-one requirements analysis with large batches of specifications.
Conclusion
So, what has been learned?
- product development is a stochastic system with queues; it is nonlinear and non-deterministic
- behavior of a stochastic system with queues defies our instincts
- batch size, size of requirements, and utilization levels affect queue size and cycle time in nonlinear random ways that are not obvious—throughput can get slow if not understood
- queue size affects cycle time
- in a variable system, high utilization increases cycle time and lowers throughput—it does not help; a traditional resource management approach [for example, McGrath04] can make things worse by focusing on the local optimization of worker busyness rather than system throughput
- a system with variability and a series of processes and WIP queues further aggravates the delay; this situation describes traditional sequential development
- variability at the front end of multi-step system with queues has the worst impact
Hidden Batches: Eyes for Batches
If you bake three cherry pies at the same time, then it is clear that there is a batch of three items. Things are not so clear in product development: What exactly is ‘one’ requirement? At one level, “handle bond derivative trades” is one requirement, but it is also a composite requirement or a batch of sub-requirements that can be split. These hidden batches need to be seen.

As we’ve seen, a system with queues behaving like a M[x]/M/1/∞ model and high utlization rates means that variable-sized big batches are bad for cycle time. And so-called single large items with variability are bad for cycle time, as they are hidden big batch. So, the implication for queue management in LeSS is this:
To reduce average cycle time, maintain slack in the system (not “100% busy”) and (eventually, incrementally) reduce all apparently ‘single’ big items (requirements) in the Product Backlog to small and roughly equal-sized items.
Hidden Queues: Eyes for Queues
When people join Toyota, they learn “Eyes for Waste.” They learn to see things as waste that they had not considered, such as inventory —queues of stuff. Now, queues of physical things are easy for people to perceive, and to perceive as a problem… My goodness, there’s a gigantic pile of Stuff queuing up over there! Making any money from the pile? Are there defects in there? Does it need to be combined with other stuff before we can ship it? Do we need—and will we make money with—each and every item in the pile?
Invisible queues—In traditional development there are also all kinds of queues, but because they are invisible they are not seen as queues or keenly felt as problems. If you are a business person who has invested ten million euros to create a gigantic pile of partially done Stuff sitting on the floor, not making any money, you walk by it and see it and you feel the pain and urgency to get it moving. And you think about no longer making big piles of partially done stuff. But product development people do not really see and feel the pain of their queues.
Yet, they are there. Queues of WIP—information, documents, and bits on a disk. Invisible queues. Product development people need a lesson in “Eyes for Queues” so that they can start to perceive what is going on, and develop a sense of urgency about reducing queue sizes.
Visual management for tangible queues—To develop “eyes for queues” and a sense of attention, one lean practice is visual management, making physical tokens (not tokens in a computer program) for these queues. For example, a popular technique is to represent all the tasks for a Sprint on paper cards that are placed on the wall and moved around as tasks are completed. Similarly for the high-priority top of the Product Backlog. These physical tangible cards make truly visible the invisible queues that are hidden away inside computer. Hiding this information into computers defeats the purpose of lean visual (physical) management and the way humans—with countless eons of evolutionary instinct working with concrete things—need to see and feel tangible queues .
Indirect Benefits of Reducing Batch Size and Cycle Time
“Why bother? Our customers don’t want a release every two weeks, nor do they want just a sub-requirement.”
We get this question regularly from product groups and business people. They do not yet appreciate the advantages of small batches in short cycles:
- The overall larger release-cycle-time reduction that can come by eradicating queues and by applying queue management so that many development cycles are shorter.
- The elimination of batch delay , where one feature is unnecessarily held back because it is moving through the system attached to a larger batch of other requirements. Eliminating this provides another degree of freedom for the business to ship a smaller product earlier with the highest-priority features.
- And last but not least, there are indirect benefits due to the “lake and rocks ” effect described next.
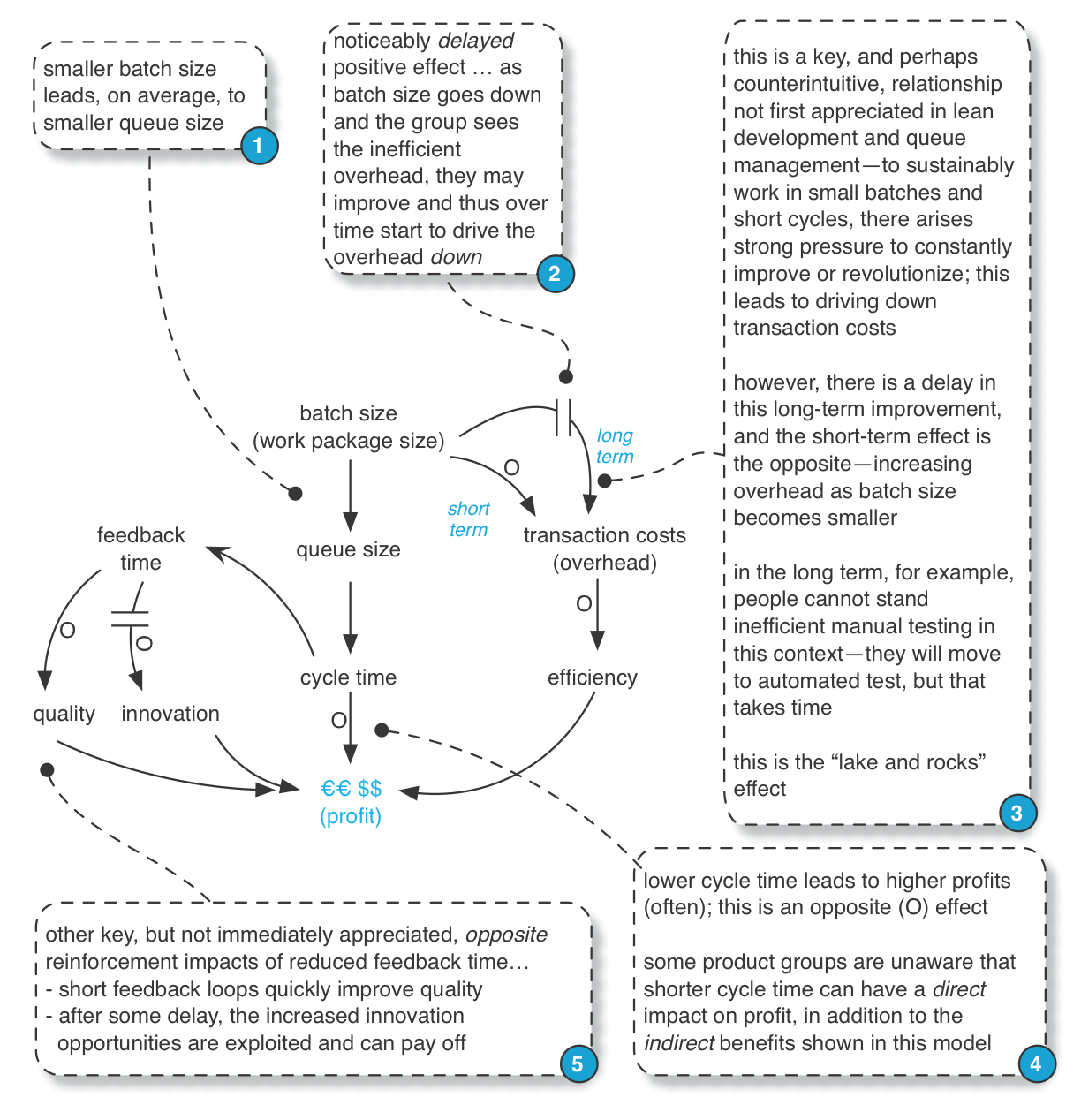
Indirect Benefits: The Lake and Rocks Metaphor
A metaphor shared in lean education: the lake and rocks. The depth of the water may represent the inventory level, batch size, iteration length, or cycle time. When the water is high (large batch or inventory size, or iteration length), many rocks are hidden. These rocks represent weaknesses. For example, consider an eighteen- month sequential release cycle with a massive batch transfer; inefficient testing, integration, and poor collaboration are all hidden below the surface of such a long cycle and such a large batch. But if we work with that group and ask, “Please deliver a small set of small features that is potentially shippable in two weeks, every two weeks,” then suddenly all the ineffective practices become painfully obvious.

Said another way, the transaction cost (overhead cost) of the old process cycle becomes unacceptable. That pain then becomes a force for improvement, because people cannot stand re-experiencing it each short cycle, and indeed it may simply be impossible to the iteration goals with the old inefficient system of development.
Tip: Not all ‘rocks’ are big or immediately visible. The lean journey—and the journey of Scrum—is to start with the big rocks that are most painfully obvious yet movable, and over time work on smaller impediments.
This causal loop diagram (the notation is explained in Systems Thinking) illustrates this lake and rocks effect in terms of a system dynamics model:
Applying Queue Management in LeSS
There are dozens of strategies to manage queues. Managing the Design Factory by Don Reinertsen explains many. However, we want to focus on a few key steps in a LeSS context:
- change the system to utterly eradicate queues
- learn to see remaining queues with visual management
- reduce variability
- limit queue size
Change the system—Must you manage existing queues? Step outside the box. For example, feature teams and acceptance TDD and continuous deployment eliminate many queues in traditional development.
Reduce variability—Some people first try to reduce work queues by increasing utilization or multitasking (with negative results), or by adding more developers. True, adding people—if they are talented—can help (there are exceptions), but it is expensive and takes time. People who have grasped queue management recognize a simpler place to start: Reduce special-cause variability, which includes reduction in batch size.
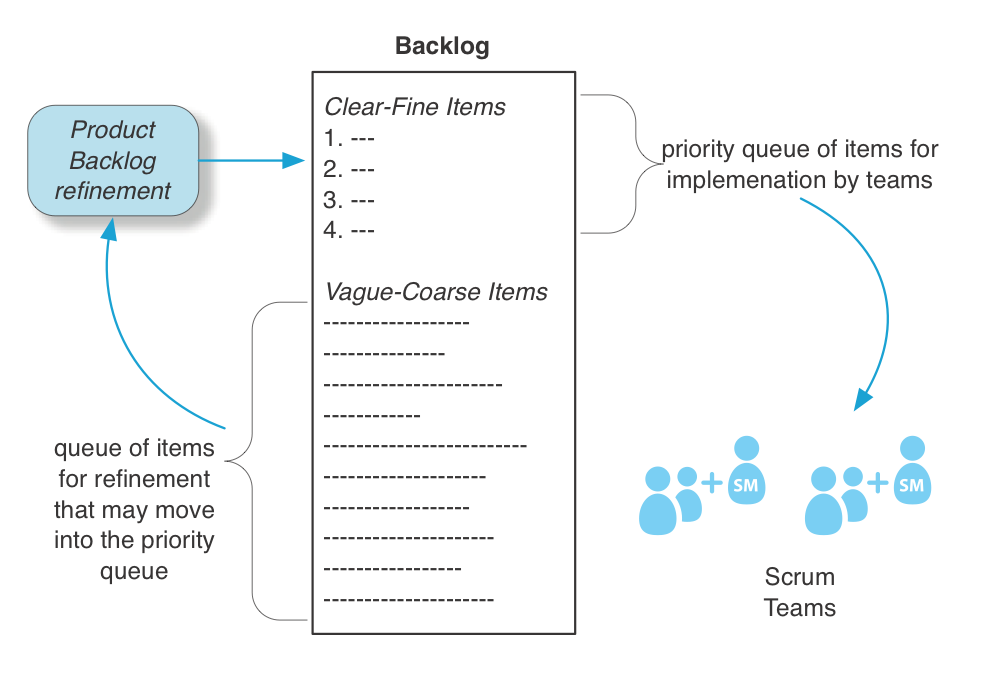
It is possible to view the Product Backlog as one big near-infinite priority queue, but we suggest a more fine-grained view. It has distinct subsets. One view is that it contains two subsets: (1) the list for the current release (which ideally is every Sprint), and (2) the “future backlog.” A second perspective is that the Product Backlog contains the following two subsets:
- the clear-fine subset of items that are clearly analyzed, well estimated, and fine grained enough to do in much less than Sprint for one team
- the vague-coarse subset of coarse-grained items needing more analysis, estimation, and splitting before entering the clear-fine subset
The “current release” and “future” subsets may both contain clear-fine and vague-coarse items. At the start of a release cycle, the “current release” typically contains mostly vague-coarse items, and Sprint by Sprint they are refined into clear-fine items, and then implemented.
This leads to some key points:
- It is common—and advisable—in LeSS to prioritize only the clear-fine subset of the “current release”.
- In LeSS, this “clear-fine priority queue” is the critical queue of implementation work before the teams.
- The vague-coarse subset is a feeding queue of items into a Product Backlog Refinement process that adds high-quality small items to the clear-fine subset.
Before getting carried away with the idea of variability reduction…new development is not manufacturing; without variation nothing new happens or is discovered. It is both appropriate and inevitable that there is variability in research and development. However, there are indeed varieties of variability than can be diminished—the topic of this section. In the terminology of Edwards Deming, there is common-cause variation and special-cause variation . The first category is common noise variation in the process, and not easy to assign a specific cause. On the other hand, special-cause variation—also known as assignable variation—can be identified. For example, variation in feature-request size is special-cause variation. And working on poorly analyzed unclear requirements is special-cause variation. By reducing identifiable special-cause variation—in Less or work processes—a system with queues has improved average throughput.
Variability is one of the three sources of waste in lean thinking (the other two are overburden and non-value-add actions ). With an understanding of queueing theory, it may be clearer why variability is considered a source of waste.
What are some sources or kinds of variability in LeSS?
- big batches and big items
- ambiguity of what items mean
- ambiguity of how to design/implement items
- different (estimated) efforts for different items
- number of items in the “current release” clear-fine priority queue
- estimate-versus-actual effort variance, which can reflect what/how ambiguity, unskillful estimation, learning, and much more
- the arrival rate of items into the clear-fine priority queue of the current release
- team and individual variability
- overloading or failure of shared resources, such as a testing lab
… and more. In queueing-model terminology, they usually boil down to variability in the service and arrival rate .
In lean thinking, flow is a key principle—and flow requires reduction or elimination of variability. That is why leveling is also a lean principle; it is an antidote to variability and helps move toward flow.
Reducing Special-Cause Variability in LeSS
This leads to some special-cause-variability-reduction suggestions in LeSS:
Reduce variability by a small queue (buffer) of clear-fine, similar-sized user stories in the Release Backlog—In Toyota, a small buffer of high-quality inventory is used to smooth or level the introduction of work to a downstream process. This inventory (a temporarily necessary waste) positively supports level pull because the LeSS feature teams now have a queue of similar-sized items to work on; no waiting and fewer surprises. Item in the vague-coarse subset of the current release have high what/how ambiguity and are large; so choosing those for implementation is unskillful because it increases variability.
Reduce variability by holding a Product Backlog Refinement (PBR) workshop each Sprint–In LeSS, each Sprint must include PBR to prepare items so that they are ready for future Sprints. This reduces what/how ambiguity or variability, plus reduces estimation variability because re-estimation may improve as people learn. During this activity, split items into small and roughly equally items. This reduces batch size and its attendant variability. It also reduces batch delay—the artificial holding back of an important sub-feature because it was stuck to a larger batch of features, some of which are less important. These repeating workshops also creates a regular cadence of adding clear-fine items to the queue, reducing variability in arrival rate.
Reduce variability by stable feature teams—Use stable long-lived feature teams in LeSS to reduce the variability in the ‘servers’—the teams. Also, the cross-functional, cross-component feature teams increase parallelism and flow because an item can flow to any one of several available teams.
Reduce variability by timeboxed effort-boxed learning goals—This tip is most useful in domains with large research-oriented requirements. It reduces what/how ambiguity and variability. Sometimes non-trivial investigation is needed just to start to understand a feature. For example, we were once consulting at a site in Budapest; the mobile-telecom product group wanted to provide “push to talk over cellular.” The international standards document for this is thousands of pages. Just to vaguely grasp the topic is a formidable effort. One approach is to ask a team to “study the subject.” Yet, that is fuzzy unbounded work that will introduce more service variability and may expand into the lean waste of over-processing. An alternate approach—a suggestion in LeSS—is to offer a team a timeboxed and effort-boxed goal to learn. Perhaps the concrete goal is to present a research report at the end of the Sprint, in addition to their work implementing items. For example, “introductory report on push to talk, maximum 30 person hours .” A leveled amount of effort is put into the research and learning, balanced with the team also implementing items. The Product Owner may then decide to invest more bounded effort into another cycle of research in a future Sprint (probably more focused as the subject clarifies), until finally the subject is clear enough for people to start writing, splitting, and estimating items.
Reducing Queue Sizes in LeSS
Another queue-management technique is to limit queue size. This does not necessarily reduce variability, but it has other virtues. In a traditional development first-in first-out (FIFO) WIP queue, a long queue is a problem because it will take forever for an item to move forward through the queue and eventually be finished—a straightforward reason to limit FIFO WIP queue size.
That problem is less pernicious in a Product Backlog priority queue, since it can be re-sorted—something just added can move to the head of the list. Still, there are good reasons to limit the number of items in the clear-fine priority queue of the current release:
- A long list of fine-grained complex features is hard to understand and prioritize. In large-product development, we regularly hear complaints from the Product Owner that the backlog is too big for them to “get their head around.”
- A big backlog of clearly analyzed, finely split and well-estimated items has usually had some investment in it, proportional to its size. It is WIP with no return on that investment. As always with WIP or inventory, that is a financial risk.
- People forget details over time. All the items in the clear-fine subset have been through in-depth analysis in Product Backlog Refinement workshops. If that list is short, there is a good chance that the team implementing the item has recently analyzed it in a workshop, perhaps within the last two months. If the queue is very long and growing, there is a greater chance the team will take on an item analyzed long ago. Even though there will probably be written documentation that was generated long ago in the workshop, it will of course be imperfect, and their grasp of the details will be hazy and stale.
Conclusion
Queue management can become a hammer so that you go looking for queue nails . Resist the temptation to manage existing queues—that is an inside-the-box response to the problem. Rather, consider doing system kaizen so that the underlying system is changed in some way so that queues can no longer form or exist. Parallelizing with cross-functional teams and acceptance test-driven development are common examples, but there are more. Only apply queue management—a point kaizen tactic—when you cannot eradicate a queue.
Recommended Readings
There are dozens, if not hundreds, of general texts on queueing theory. More specifically, we suggest readings that make the connection between this subject and product development:
-
Managing the Design Factory by Don Reinertsen is a classic introduction on queueing theory and product development.
-
Flexible Product Development by Preston Smith was the first widely-popular general product development book that introduced agile software development concepts—including Scrum and Extreme Programming—to a broader audience. This text includes an analysis of queueing theory and variability, and their relationship to development.