Теория Массового Обслуживания
Удовольствие от инжиниринга - это найти прямую линию на графике логарифма в квадрате.
—Томас Кёниг
Теория массового обслуживания позволяет разобраться, почему традиционная разработка чрезмерно медленная — и что с этим делать. В крупномасштабной разработке довольно распространено, что “одна” фича (до разделения) может быть ошеломляюще гигантской. В таких областях особенно хорошо заметно, что большие партии и длинные очереди действительно существуют и какие проблемы они вызывают. Сложно решить проблему, о существовании которой вы не знаете. И теория массового обслуживания указывает на некоторые способы улучшения. Этот инструмент мышления особенно релевантен для крупных масштабов, поскольку большие, меняющиеся партии работы — столь распространенные в традиционной модели — имеют нелинейное воздействие на время цикла — они действительно могут всё испортить.

Интересное несоответствие: Теория массового обслуживания — математический анализ того как вещи двигаются сквозь систему с очередями — была разработана, чтобы понимать и улучшать пропускную способность в телекоммуникационных системах — системах с большой вариативностью и хаотичностью близкой к продуктовой разработке. Как следствие, телеком инженеры понимают основные идеи. Но по-прежнему, люди, занимающиеся развитием телеком инфраструктуры (телеком - это область больших продуктов) редко замечают, что это применимо к их системе, чтобы сократить среднее время цикла в их производственном процессе.
Люди из Тойота изучают статистическую вариацию и влияние теории массового обслуживания; это отражается в выравнивающем принципе бережливого подхода, который уменьшает вариативность и в целом в фокусе бережливого подхода на уменьшении размера партии и времени цикла прохождения потока.
Прежде чем погружаться в тему, отметим, что бережливый подход иногда описывается как концентрация на меньших размерах партии, более коротких очередях, и сокращении времени цикла. Быстрая поставка ценности. Бережливый подход существенно больше этого — его столпы - уважение к людям и непрерывное улучшение, которые опираются на основы в виде руководителей-учителей в бережливом мышлении. Управление очередями (ограничение НЗР, …) эффективная практика, но это лишь инструмент, далекий от глубинной сути бережливого мышления.
Как станет очевидно, управленческие принципы теории массового обслуживания во многом поддерживаются в LeSS.
Миф Закона Литтла
Прежде чем дальше погружаться в теорию массового обслуживания, несколько слов о широко распространённом мифе, относящемся к теории массового обслуживания, известном в сообществах гибкой разработки и бережливого подхода (и даже в нескольких подходах к масштабированию), который следует незамедлительно прояснить. Закон Литтла доказывает, что уменьшение уровня НЗР (WIP) уменьшает среднее время цикла. О, если бы это было так! К сожалению, доказательство Литтла зависит от ряда условий/предположений, которые должны соблюдаться для того, чтобы динамика оставалась положительной. И, к сожалению, эти условия никак не гарантируются или даже не являются как-правило-истинными в областях с высокой степенью изменчивости, таких как разработка программного обеспечения. Наивность продвижения или обоснования Закона Литтла в разработке программного обеспечения хорошо разобрана в анализе Даниэля Ваканти (Daniel Vacanti), названном Little’s Flaw
Уменьшение уровня НЗР - достойная цель и считается важным в LeSS. НЗР - одна из потерь в бережливом мышлении, потому что это, помимо прочих проблем, задерживает возврат инвестиций, скрывает дефекты, уменьшает прозрачность. И уменьшение уровня НЗР выявляет недостатки. Но, к сожалению, в разработке программного обеспечения нет гарантии, что уменьшение НЗР автоматически уменьшит среднее время цикла.
Конкурировать за счёт Укорачивания Времени Цикла
Бережливая организация разрабатывающая продукты сосредоточена на пропускной способности при поставке ценности в стабильных циклах за кратчайшее возможное время, она сосредоточена прежде всего на пропускной способности, а не на занятости людей. Люди из Тойота, прародители бережливого мышления, являются мастерами во всё большем и большем ускорении (укорачивании) времени цикла без перегрузки людей.
Рассмотрим некоторые процессные циклы или что есть время цикла в продуктовой разработке:
- “от идеи до прибыли” за один релиз
- “от идеи до готовности” в одной фиче
- время до потенциальной готовности к поставке; как часто вы можете поставлять?
- время компиляции (для всего программного продукта)
- время от “готово к пилоту” до поставки
- время развертывания для тестирования (на интегрируемом оборудовании)
- время на анализ и проектирование
Ключевые показатели эффективности (КПЭ) в бережливом подходе не сосредоточены на утилизации или занятости рабочих, выполняющих вышеописанные процессы. Скорее, КПЭ бережливого подхода фокусируются больше на пропускной способности и времени цикла.
Тем не менее, предупреждение: Измерение обычно приводит к дисфункции или к попыткам ‘обыграть’ систему путем локальной оптимизации для того, чтобы создать видимость, как будто достигаются хорошие показатели. [Austin96]. Это особенно справедливо для ‘низкоуровневых’ процессных циклов. Показатели времени цикла более высокого уровня, такие как время цикла до потенциальной готовности к поставке и “от заказа до прибыли” или “от заказа до поставки” (наиболее существенные показатели времени цикла), являются более актуальными.
Что бы могла значить для вас возможность поставлять в два или четыре раза быстрее в устойчивом темпе без перегрузки людей? И с другой стороны, какова стоимость задержки?
Рассмотрите преимущества быстрой поставки с точки зрения жизненного цикла, полученных возможностей, реакции на конкуренцию и инноваций. Для большинства компаний — не для всех — это будет выдающееся преимущество.
В два раза быстрее - это не в два раза дешевле — Когда люди слышат “в два раза быстрее” они возможно думают: “В два раза больше продуктов, функциональностей или релизов — вдвое эффективнее.” Но здесь могут скрываться операционные издержки, накладные расходы в каждом цикле. Более частая поставка может увеличить расходы на тестирование или установку — или нет, как будет видно далее.
В два раза быстрее - это не в два раза дороже — Не торопитесь убирать свои таблицы для анализа операционных расходов. Существует тонкая связь между временем цикла, операционными расходами и эффективностью, как вскоре будет прояснено — секрет, стоящий за впечатляющей эффективностью Toyota и других предприятий, использующих бережливое мышление …
Управление очередями — существует множество стратегий, нацеленных на уменьшение времени цикла; приверженцы и бережливого производства и практики гибкой разработки предлагают нам рог изобилия различных практичных средств. Один из таких инструментов является темой настоящего раздела — управление очередями.
Управление Очередями для Уменьшения Времени Цикла
“Очереди существуют только в производстве, так что теория массового обслуживания и управление очередями неприменимы к продуктовой разработке.” Это распространенное заблуждение. Как упоминалось ранее, теория массового обслуживания зародилась не в производстве, а при исследованиях операций для повышения пропускной способности в телекоммуникационных системах с высокой вариативностью. Тем не менее, многие группы разработки — особенно те, которые внедряют практики гибкой разработки или бережливого мышления — приняли управление очередями, основанное на понимании теории массового обслуживания как для разработки продуктов, так и для управления портфелем. Авторы одного исследования в МТИ (Массачусетский технологический институт, MIT) и Стэнфордском университете, пришли к следующему выводу:
Бизнес подразделения, которые приняли этот подход [управление очередями для продуктового портфеля и управления продуктами] уменьшили среднее время разработки на 30-50% [AMNS96]
Очереди в Разработке Продукта и Управлении Портфелем
Примеры очередей в разработке и управлении портфелем?
- продукты или проекты в портфеле
- новые функциональности для одного продукта
- подробные спецификации требований, ожидающие проектирования
- проектные документы, ожидающие разработки
- код ожидающий тестирования
- код одного разработчика ожидающий интеграции с другими разработчиками
- большие компоненты, ожидающие интеграции
- большие компоненты и системы ожидающие тестирования
В традиционной последовательной разработке существует множество очередей с частично сделанной работой, известные как не-завершенная-работа очереди НЗР; например, документы со спецификацией, ожидающие начала программирования или код, ожидающий начала тестирования.
В добавлении к очередям НЗР , существуют ограниченные-ресурсы или очереди разделяемых-ресурсов такие, как бэклог запросов на использование дорогостоящей тестовой лаборатории или оборудования для тестирования.
Очереди Являются Проблемой
Во-первых, если не существует очередей — и нет многозадачности, которая искусственно создаёт видимость, что очередь устранена — тогда система двигается в направлении потока, принцип бережливого подхода и стремления к совершенству заключается в том, что ценность поставляется без каких-либо задержек. Каждая очередь создаёт задержку, которая является препятствием для потока поставки ценности. Если говорить более конкретно, почему очереди являются проблемой?
Очереди НЗР
Очереди НЗР в разработке продуктов редко рассматриваются как таковые по нескольким причинам; возможно главная среди них в том, что они, как правило, незаметны — набор битов на диске компьютера. Но они действительно существуют — и что более важно, они создают проблемы. Почему?
Очереди НЗР (как и большинство очередей) увеличивают среднее время цикла и ухудшают поставку ценности и тем самым могут сократить общую прибыль.
В бережливом мышлении, очереди НЗР классифицируются как потери — и следовательно, должны быть устранены или сокращены — потому, что:
- Очереди НЗР имеют вышеупомянутое воздействие на время цикла.
- Очереди НЗР являются полуготовой продукцией (спецификациями, кодом, документацией, …) с вложенными в них временем и деньгами, которые ещё не имеют возврата на инвестиции.
- Так же как и все запасы, очереди НЗР скрывают ошибки — и способствуют их распространению — поскольку груда запасов ещё не была использована или проверена на следующем шаге процесса, чтобы проявить скрытые проблемы; например, большое количество ещё не-интегрированного кода.
- Одна история: Мы видели продуктовую группу, использующую традиционные подходы к разработке, которая потратила около года, работая над функциональностью “завершение сделки”. Затем руководство продукта решило удалить её, потому что она поставила под угрозу весь релиз, а рыночные условия изменились. Перепланирование заняло много недель. В целом, очереди НЗР влияют на стоимость и способность реагировать на изменения (удаления и добавления) потому, что: (1) время и деньги были потрачены на незавершенную удалённую работу которая не будет в конечном итоге реализована, или (2) НЗР, связанная с удалёнными элементами, может быть тесно переплетена с другой функциональностью, или (3) выпуск новой добавляемой функциональности может быть отложен из-за высокого уровня текущей НЗР.
Как будет рассмотрено далее, существует тонкий, но потенциально очень мощный побочный эффект улучшения систем, который может возникнуть в процессе устранения очередей НЗР.
Очереди Общих Ресурсов
В противоположность очередям НЗР (которые на первый взгляд не кажутся тем, чем являются), очереди общих ресурсов чаще всего выглядят, как очереди — и выглядят, как проблема. Они действительно заметно и болезненно замедляют людей, задерживают обратную связь и растягивают время цикла. “Нам нужно протестировать свой новый код на том целевом принтере в тестовой лаборатории. Когда он будет свободен?”
План А: Ликвидация Очередей (а не управление ими)
В итоге суть такова, что (как правило) очереди являются проблемой. Исходя из этого, вы можете сделать поспешный вывод, что первая линия обороны против этой проблемы - уменьшить объёмы партий и размер очереди , потому, что таковы классические стратегии управления очередью. Однако существует решение, позволяющее “разрубить Гордиев Узел”, которое следует рассмотреть первым…
В оставшейся части этой главы мы, несомненно, рассмотрим уменьшение времени цикла путём управления размерами партий и очередей. Но вся эта стратегия управления должна быть Планом Б. Будет правильнее начать с Плана А:
План А в исправлении проблемы очереди заключается в полном искоренении этой очереди, навсегда, изменив саму систему: организационную систему, систему разработки, инструменты, процессы, практики, политики, и т.п.
Превзойдите границы мышления и сократите время цикла, изменив саму систему так, чтобы очередей больше не существовало — устраняя узкие места (bottleneck) и другие причины появления очередей. Эти ограничения и очереди, которые они порождают, могут быть как созданы, так и уничтожены самой природой системы разработки и её инструментами.
Предположим существующая система основывается на последовательной разработке, каждым этапом которой является работа одного или группы рабочих одной специализации. В такой системе будут существовать очереди НЗР: Группа аналитиков передаёт пакеты рабочих спецификаций группе разработчиков, которая передаёт пакеты рабочего кода группе тестирования, которая передаёт код группе внедрения и эксплуатации. Мерой, лежащей в пределах традиционного мышления, по улучшения с помощью управления очередями, является уменьшение максимального размера НЗР и очередей. Но такой подход имеет дело всего лишь со вторичными симптомами существующей системы.
Существует более фундаментальная альтернатива, которая может радикально улучшить время цикла: Откажитесь от существующей системы, от её узких мест и очередей НЗР, которые они порождают. Если вы внедрите кросс-функциональные продуктовые команды, которые поставляют полностью готовую функциональность (включая аналитику, программирование и тестирование), без передачи работы другим группам, и которые применяют автоматизированную разработку через приёмочное тестирование и автоматизированную непрерывную поставку, то вышеупомянутые очереди НЗР исчезнут благодаря переходу от последовательной к параллельной разработке.
Этот подход отражает видение LeSS, основанное на устранении корневых причин: Измените организационную структуру для решения ключевых проблем.
Ложная Ликвидация Очереди
Предположим вы заняты работой над элементом А, а элементы Б, В, Г и Д находятся в вашей очереди. Ложным сокращением очереди было бы работать над всеми этими элементами в примерно одно и то же время — высокий уровень многозадачности и утилизации. Многозадачность считается одной из потерь в бережливом подходе, потому что, как мы вскоре увидим, теория массового обслуживания показывает, что это способствует увеличению среднего времени цикла, а не его уменьшению. И этот ложный подход фактически увеличивает уровень НЗР, во имя его уменьшения! Плохая идея.
Не увеличивайте многозадачность или уровень утилизации для создания иллюзии, что очередь была уменьшена, а система была улучшена; скорее, улучшайте саму систему, чтобы узкие места и другие причины возникновения очередей были устранены.
План Б : Управляйте Очередями Когда Вы Не Можете Ликвидировать Их
Распространённые очереди НЗР могут быть ликвидированы переходом к LeSS с кросс-функциональными продуктовыми командами, применением разработки через приёмочное тестирование (A-TDD) и непрерывной поставки. Изгнанные и исчезнувшие благодаря Плану А — изменение самой системы. Это идеальное решение, рекомендованное в LeSS.
Однако по-прежнему очереди могут оставаться и остаются, такие, как:
- очереди таких общих ресурсов, как тестовая лаборатория
- очередь запросов на новую функциональность в Бэклоге Продукта
- очереди НЗР потому, что: (1) План А пока ещё не осуществим (глубокие изменения в больших продуктовых группах требуют времени), или (2) инструменты и техники, такие как переход от ручного к полностью автоматизированному тестированию, пока слабы и улучшаются медленно.
По какой бы причине очереди не оставались — и в конце концов, Бэклог Продукта останется всегда — вы можете улучшить средне время цикла благодаря Плану Б, управляя очередями:
План Б: Для очередей, которые не могут искоренены, улучшайте среднее время цикла путём уменьшения объёмов партий в очередях, уменьшения лимитов НЗР и размеров очередей, стараясь делать все партии более или менее одинакового размера.
В LeSS, меньший объём партии означает меньший рабочий пакет элементов или функциональности для разработки в Спринте. Выровненные по размеру партии подразумевают, что каждая такая порция работ оценивается примерно в одинаковое количество затрат.
Как конкретно применить это в LeSS? Это будет раскрыто чуть позже, а сначала, погрузимся в область теории массового обслуживания…
Теория Массового Обслуживания
Это могло бы потребовать тяжелой работы или какого-то нового подхода, но не нужно много теории для того, чтобы “управлять очередями” путём их ликвидации. С другой стороны, когда они должны существовать ни смотря ни на что, полезно знать, как иметь с ними дело с помощью инструментария теории массового обслуживания.
Формальная Модель для Оценки Процессов
Вы можете принять за чистую монету, что очереди из небольших партий функциональности одинакового размера улучшают среднее время цикла. Или нет. В любом случае, полезно знать, что эта рекомендация не основывается на чьём-либо мнении, а опирается на формальную математическую модель, которая может быть подтверждена. Некоторые аспекты процесса разработки действительно возможно аргументировать с помощью такой формальной модели. Рассмотрим пример:
- Гипотеза : Наиболее верный способ - последовательная (‘водопадная’ или V-модель) разработка с передачей больших объёмов партий между специализированными функциональными группами.
- Гипотеза : Наиболее правильно для людей или групп - иметь высокие показатели утилизации и многозадачности на многих проектах в одно и то же время.
Понимание теории массового обслуживания, свободной от чьих-либо мнений, поможет выявить действительно ли эти гипотезы помогают уменьшить среднее время цикла.
Данная тема относительно проста; пример сценария, охватывающего ключевые аспекты …
Качества Стохастической Системы с Очередями
Рассмотрим Лос-Анджелес или Бангалор в час пик. Пока каким-то чудом здесь нет аварий, и все полосы открыты. Поток плотный и медленный, но движется. Затем за короткий промежуток времени происходят три аварии, перекрывая по одной полосе из четырёх на каждом из основных шоссе (которые составляют в сумме двенадцать полос) — только девять полос остаются по-прежнему открытыми. Буум! Прежде чем вы успеете сказать: “Почему я не купил вертолёт?” на большей части города происходит сдвиг фазы в состояние пробка. Когда последствия аварий окончательно устранены (в последующем промежутке от тридцати до шестидесяти минут), проходит вечность, прежде чем расчистится огромная очередь из автомобилей. Наблюдения:
- Нелинейность — Когда шоссе загружено от нуля до пятидесяти процентов, оно плавно плывёт — практически нет задержек или очередей. Но между пятьюдесятью и ста процентами, замедление становится заметным, начинают выстраиваться очереди. Связь загрузки шоссе с размером очереди нелинейная, нет плавного линейного увеличения от нуля.
- Задержки и перегрузка не начинаются с 99.99% загрузки — Это не тот случай, когда всё на шоссе двигается быстро и плавно, до тех пор пока не достигнута 100-процентная загрузка машин на дороге. Напротив, всё замедляется, и появляются пробки задолго до того, как достигнута максимальная загрузка.
- Расчистка очереди занимает больше времени, чем её создание — сорокапятиминутный затор в Лос-Анджелесе в час пик создаёт очереди, расчистка которых занимает более сорока пяти минут.
- Стохастичность, не детерминированность — Существует вариация и беспорядочность в вероятности (это стохастическая система): прибытия машин, времени устранения заторов, скорости выхода автомобилей из пробок.
Это стоит прояснить, если вы хотите разобраться в поведении системы, поскольку, судя по всему, все мы, люди, не имеем интуитивного понимания стохастических и нелинейных качеств систем с очередями. Наоборот, внутренний инстинкт говорит, что они детерминированы и ведут себя линейно. Этот ложный “здравый смысл” приводит к ошибкам мышления при анализе проблем и управлении разработкой продуктов. Эти наблюдения — как и ошибки мышления — применимы также и к очередям НЗР в традиционной продуктовой разработке и практически ко всем другим очередям.
Одна распространённая ошибка мышления в разработке продуктов заключается в том, что очереди, задержки и люди, которые их обслуживают, ведут себя как на Рисунке 1 — это заблуждение “задержки начинаются только тогда, когда шоссе заполнено на 100 процентов. ”На самом деле задержки начинают возникать на шоссе задолго до того, как оно заполнится на 100 процентов. Может быть, вы начнёте замечать задержки при 60-процентной загрузке — что значит более длинное среднее время цикла.
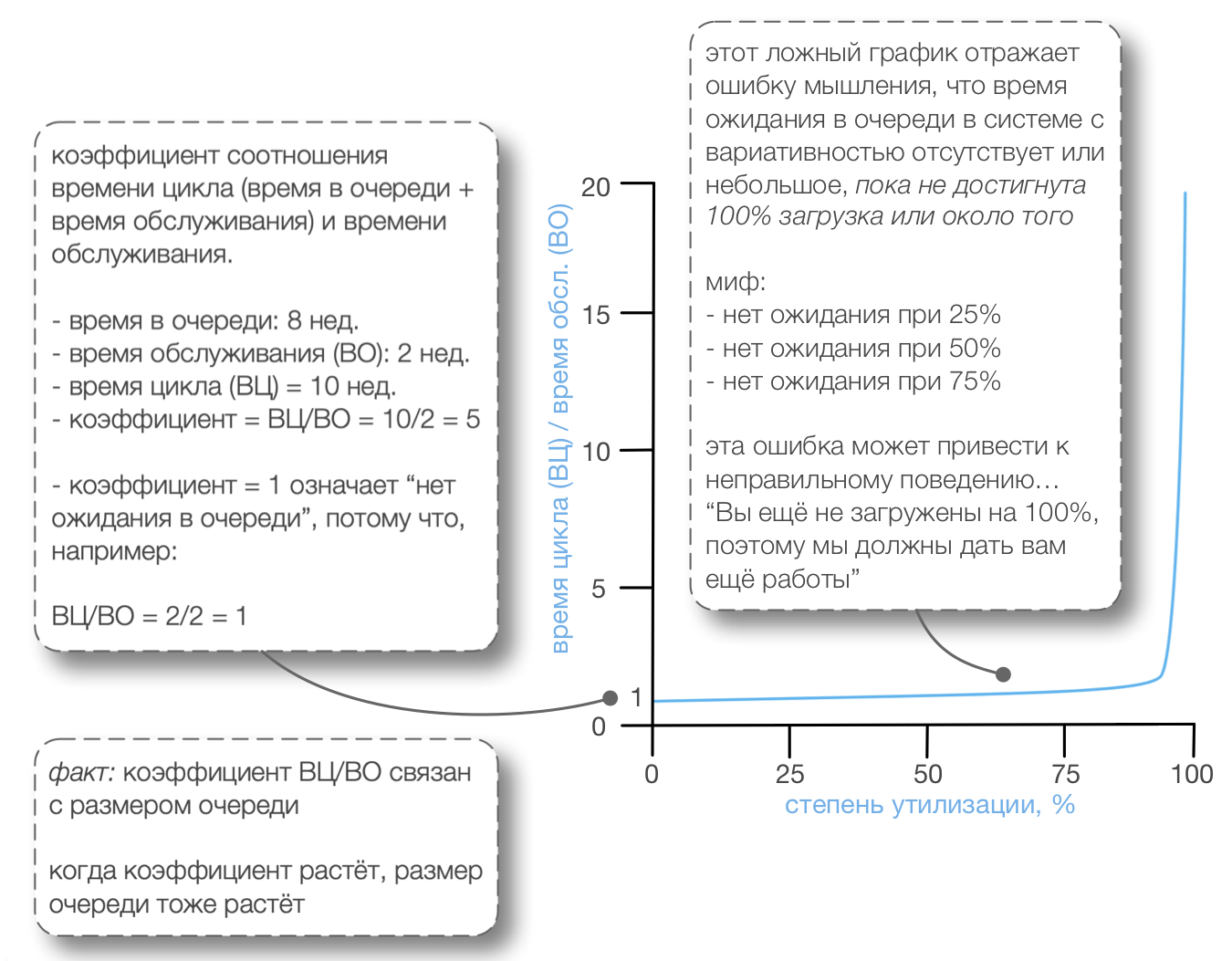
Из-за заблуждения “задержки начинаются только тогда, когда шоссе заполнено на 100 процентов, ” возникает неправильный фокус на попытках улучшить время цикла путём увеличения утилизации ресурсов — заставляя людей, разрабатывающих продукт, быть более загруженными, как правило, за счёт увеличения многозадачности. Это ошибка мышления, основанного на локальной оптимизации.
Что на самом деле происходит, когда кто-то увеличивает уровень утилизации инструментов или людей в системах с вариативностью?
В Xerox есть дорогие большие цифровые печатные прессы в тестовой лаборатории. Часто возникает очередь общего ресурса из запросов на тестирование на одном из этих устройств. Без понимания того, как на самом деле работают очереди (точнее, вера в то, что они работают как на Рис. 1), подход к управлению должен был бы заключаться в том, чтобы способствовать резервированию и утилизации этих дорогостоящих систем, близкой к 100 процентам. Но реальность такова, что повсюду существует вариативность — стохастическая система. Тесты поступают случайно, некоторые быстро завершаются с ошибкой, выполнение некоторых занимает целую вечность, иногда ломается оборудование и тому подобное. Такая же вариативность существует и в поведении людей и в очередях работы, которую они выполняют .

Моделирование Базовой Системы с Очередями и Единичным-Поступлением
Как ведут себя эти системы — в дорожном трафике, в тестовых лабораториях, или в традиционной разработке, где люди сталкиваются с очередями НЗР? У вас уже сложилось понимание этого из истории о трафике. Математически, это поведение может быть моделировано в виде вариаций систем М/М. М/М означает, что порядок поступления в очередь является Марковским, а также порядок обработки элементов очереди тоже Марковский. Что такое Марковский: Простая концепция — некий случайный (стохастический) процесс, в котором состояние в будущем не может быть детерминировано на основании его прошлых состояний (см. Цепь Маркова прим. переводчика); то есть, похоже на “беспорядочную реальность.”
Наиболее распространённую, базовую модель очереди можно обозначить так: М/М/1/∞ — она имеет один обработчик (например, один тестовый принтер или команду) и бесконечную очередь. (Очереди в разработке, как правило, не бесконечны, но это упрощение не повлияет на базовый паттерн поведения системы.)
Теперь становится интереснее… Как в системе М/М/1/∞, соотносится время цикла и время обслуживания с загрузкой обработчика — будь то тестовый принтер или люди, работающие с очередями НЗР? График “Ожидание в базовых системах М/М/1/∞.” показывает это [Smith07].
На графике “Ожидание в базовых системах М/М/1/∞.” показаны примерные значения, поскольку факторы имеют случайную вариативность, например:
- запросы поступают в разное время с разной интенсивностью
- усилия, необходимые на тесты или программирование, занимают разное время
- люди могут работать быстрее или медленнее, заболеть, работать больше или меньше
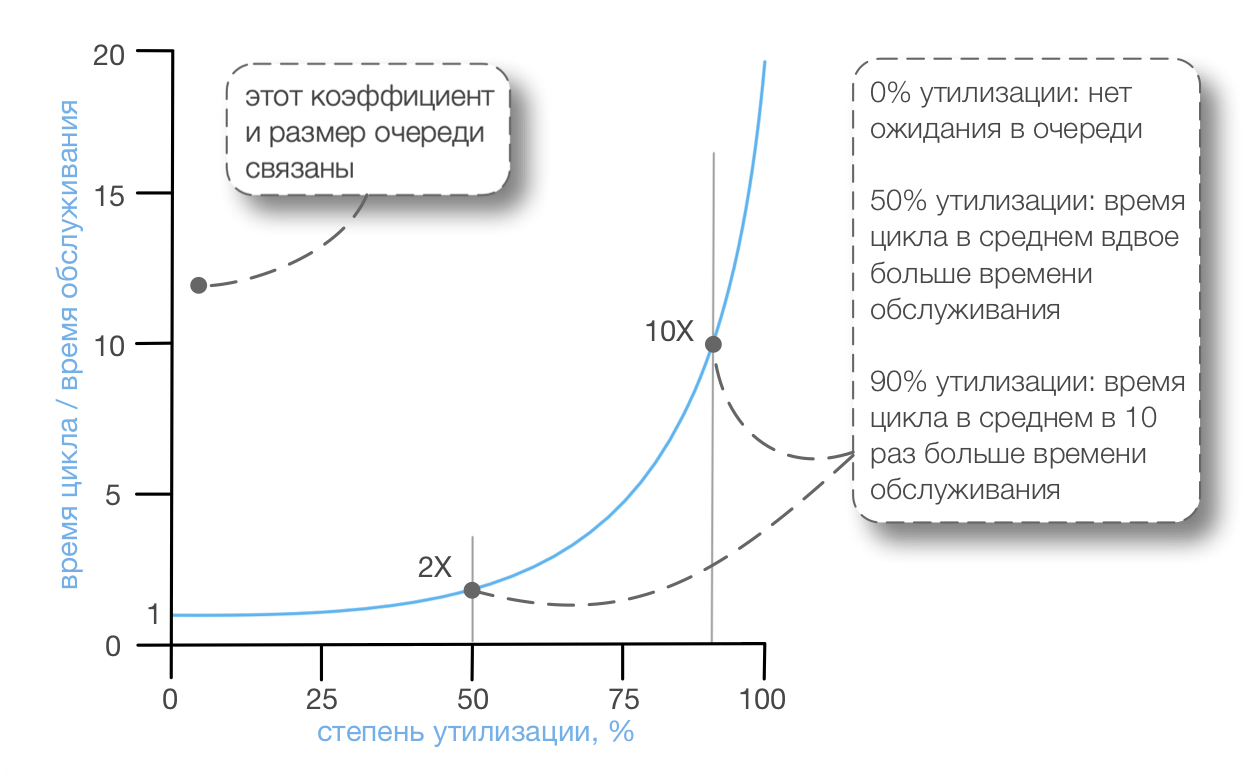
Существенный момент, который следует осознать, заключается в том, что элемент (например, такой, как новое требование) осядет в очереди, ожидая обслуживания, задолго до того, как люди будут загружены на 100 процентов. Также удивительно видеть влияние увеличения загрузки людей на время цикла: Когда загрузка возрастает, в системе с большой вариативностью, среднее время цикла ухудшается, а не улучшается. Это контринтуитивно для заурядного бухгалтера или консультанта по вопросам управления, которые были обучены “улучшать продуктивность путём увеличения утилизации ресурсов.” Большинство из них не были знакомы с теорией массового обслуживания — как понимать стохастическую систему с очередями (людей, выполняющих работу с вариативностью) — и поэтому демонстрируют распространённое заблуждение.
Именно эта изменчивость реальной жизни, в основном, и увеличивает размер очереди и время ожидания при разработке продуктов.
Моделирование Пакетной Системы с Очередями (Традиционная Разработка)
Становится ещё более интересно (если вы сможете в это поверить)… Базовая система М/М/1/∞ подразумевает, что элементы (на тестирование, анализ, разработку, …) прибывают изолированно, по одному — что прибывающие элементы никогда не группируются (не объединяются в пакеты). Однако в традиционной разработке продуктов, пакеты работ в действительности прибывают такими большими объёмными партиями, как набор требований или задач на тестирование или большой партии кода, которая должна быть интегрирована. Или ‘единственное’, как предполагается, требование может быть получено в форме: «обработка сделок с деривативами на рынке Бразилии», но что по факту тоже является пакетом подтребований. Этот последний момент очень важно отметить, поскольку большое требование никогда не проходит через систему, как один пакет требований, хотя “со стороны” это и может ошибочно казаться одним цельным пакетом требований.
“Одно большое требование само по себе является пакетом” - это критически важный момент который будет рассмотрен далее.
Итак, вместо более простой системы с поэлементным поступлением по модели М/М/1/∞ (на вход поступают отдельные, атомарные элементы работы), рассмотрим систему М[x]/М/1/∞ (на вход которой поступают пакеты элементов). Эта модель является лучшей аналогией традиционной продуктовой разработке.
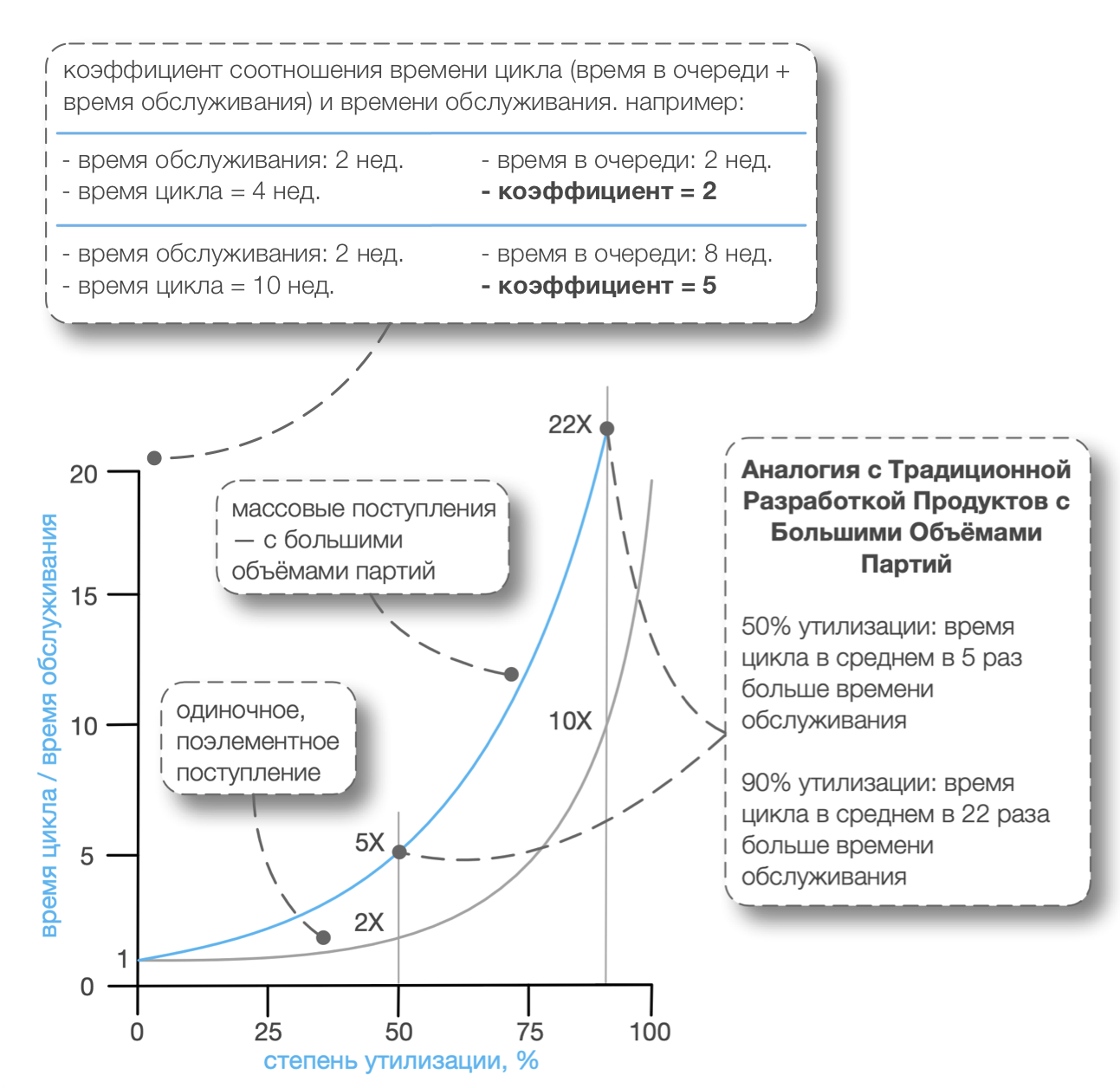
С первого раза, люди могут не осознать такого поразительного и кажущегося нелогичным влияния на их время цикла.
Следующая история поможет разобраться: Представим человека или команду, загруженных на текущий момент на 50 процентов, вы обычно даёте им по одному требованию небольшого размера время от времени, которые поступают с некоторой случайностью и могут несколько отличаться в размере. Предположим что им потребуется две недели фактической работы, чтобы выполнить некое требование X. И предположим, что это простая система с поэлементным пополнением. В таблице ниже приведена аппроксимация типовой ситуации:
| Пополнение | Утилизация | Время в Очереди (Ожидания) | Время Обработки (Обслуживания) | Время Цикла | Коэффициент ВремяЦикла/ВремяОбработки |
|---|---|---|---|---|---|
| поэлементное | 50% | 2 недели | 2 недели | 4 недели | 2 |
Далее, наоборот, предположим что вы обычно даёте на 50 процентов загруженной команде существенно бóльшие пакеты требований или по ‘одному’ гигантскому требованию, которые фактически включают в себя большой пакет подтребований; такие пакеты поступают с некой случайностью во времени и могут отличаться по размеру. Предположим, что непосредственно на обслуживание некоего пакета X или одиночного требования уходит двадцать недель.
Основываясь на предыдущей таблице, вот какие значения некоторые люди прогнозировали бы для ситуации с пополнением большими партиями:
| Пополнение | Утилизация | Время в Очереди | Время Обработки | Время Цикла | Коэффициент ВремяЦикла/ВремяОбработки |
|---|---|---|---|---|---|
| поэлементное | 50% | 2 недели | 2 недели | 4 недели | 2 |
| а если большой партией? | 50% | 20 недель | 20 недель | 40 недель | 2 |
Предсказание, основанное на внутреннем ощущении линейно увеличивает воздействие на время цикла. В среднем в десять раз возросло количество работы “пропущенной” через систему, значит в десять раз должно возрасти время цикла. Четыре недели вместо сорока недель.
Но так это не работает, потому что в систему введено больше вариативности. Что же в таком случае происходит на самом деле?
При 50-процентной утилизации, коэффициент времени цикла к обслуживанию на самом деле ‘5’ в примере М[x]/М/1/∞. Это приблизительно соответствует следующей ситуации, сильно отличающейся от предыдущего предположения:
| Пополнение | Утилизация | Время в Очереди | Время Обработки | Время Цикла | Коэффициент ВремяЦикла/ВремяОбработки |
|---|---|---|---|---|---|
| поэлементное | 50% | 2 недели | 2 недели | 4 недели | 2 |
| большой партией | 50% | 80 недель | 20 недель | 100 недель | 5 |
Всё стало намного хуже. Конечно, это некие усреднения, и они не могут быть приняты ни для какого реального случая, и эта модель является упрощённой абстракцией реальной продуктовой разработки. Но вот почему понимание — и действие в соответствии с этим пониманием — теории массового обслуживания применимо для крупномасштабной разработки. Потому что большие системы часто связаны с масштабными требованиям, и большим количеством работы (разработка требований, тестирование, интеграция, …) в больших партиях, прибывающих в случайное время, с работниками, утилизация (загрузка) которых ожидается около 100% на протяжении всего времени. Это может оказать невероятное влияние не среднее время цикла.
Таким образом, если настаивать на высоких уровнях загрузки для сотрудников в этой ситуации с большими партиями работы, то это будет рецептом для замедлееения. В реальности произойдёт “гиперлинейное” увеличение времени цикла. Это воздействие на задержки и размер очереди не поддаётся нашему инстинктивному ощущению потому, что люди не привыкли анализировать стохастические системы с очередями. Кто-то может подумать, “Если я сделаю пакет работы в десять раз больше, потребуется в десять раз больше времени, для того чтобы он вышел из системы обработанным.” Даже не рассчитывайте на это.
И эти задержки ещё более усугубляются в традиционной последовательной разработке, поскольку существуют серии процессов с очередями НЗР перед ними; это усугубляет вариативность и добавляет больше негативного влияния на общее среднее время цикла. Закон Распределения Вариативности [HS08] показывает, что худшее место для вариативности (в плане негативного воздействия на время цикла) - в самом начале многоступенчатой системы с очередями. Это как раз то, что происходит в традиционной разработке на первой фазе анализа требований с большими порциями спецификаций.
Заключение
Итак, что мы узнали?
- разработка продуктов - это стохастическая система с очередями; она нелинейна и не детерминирована
- поведение стохастической системы с очередями противоречит нашим инстинктивным, внутренним ощущениям
- размер партии, размеры требования и степень утилизации влияют на размер очереди и время цикла нелинейным, случайным способом, который не является очевидным — другими словами, пропускная способность может уменьшаться
- размер очереди влияет на время цикла
- в изменчивой системе, высокая утилизация увеличивает время цикла и снижает пропускную способность — традиционный подход к управлению ресурсами здесь не помогает [например, McGrath04] и может, наоборот, усугубить ситуацию если сосредоточиться на локальной оптимизации загрузки рабочих вместо пропускной способности системы
- система с вариативностью и серией процессов с очередями НЗР еще больше усугубляет задержку; эта ситуация характеризует традиционную последовательную разработку ПО
- высокая вариативность на входе многоступенчатой системы с очередями имеет наиболее пагубные последствия
Скрытые Партии: Чутьё на Партии
Если вы печёте три вишнёвых пирога в одно и то же время, то очевидно, что это партия из трёх пирогов. Но в разработке продуктов не всё так очевидно: Что в точности из себя представляет ‘одно’ требование? На каком-то уровне, “обработка сделок с облигациями и ценными бумагами” является одним требованием, но на другом уровне это также и составное требование или партия (пакет) подтребований, которое может быть разделено. Нужно научиться распознавать такие скрытые партии.

Как мы увидели, в системе с очередями, ведущей себя в соответствии с моделью М[x]/М/1/∞ и с высоким коэффициентом утилизации, большие партии переменного размера пагубно влияют на время цикла. И, так называемые, одиночные большие элементы с вариативностью также ухудшают время цикла, поскольку на самом деле за ними скрываются большие партии. Таким образом, выводы об управлении очередями в LeSS заключаются в следующем:
Чтобы уменьшить среднее время цикла, поддерживайте некоторое бездействие в системе (не допускайте “100% загрузки”) и (со временем, постепенно) сокращайте все якобы ‘одиночные’ большие элементы (требования) в Бэклоге Продукта до небольших и примерно одинаковых по размеру элементов.
Скрытые Очереди: Чутьё на Очереди
Когда люди приходят в Toyota, их учат тренировать “Чутьё на Потери.” Они учатся находить потери в тех вещах, которые ранее они не считали таковыми, таких как запасы — например, очереди товара или деталей. После такого обучения, людям легко заметить очереди из физических вещей, и распознать это как проблему… Боже мой, да там гигантская груда всякого Барахла стоящего в очереди! Делаются ли какие-то деньги из этой кучи? Кто знает, есть ли там дефекты? Нужно ли объединить это с какими-то другими деталями, для того чтобы мы смогли поставить это? Действительно ли нам нужны — и мы сможем сделать из этого деньги — все без исключения вещи в этой груде?
Незаметные очереди — В традиционной разработке также существуют все виды очередей, но из-за того что они незаметные, они не выглядят, как очереди или не ощущаются остро, как проблемы. Если вы бизнесмен, который инвестировал десять миллионов евро для создания гигантской груды частично сделанных каких-то Вещей, лежащих на полу, не приносящих никаких денег, то вы пройдёте мимо них, физически ощутите их, и тогда вы почувствуете всю боль и срочность, достаточную для того, чтобы заставить это двигаться. И тогда вы подумаете о том, что больше никогда не будете создавать такие большие груды частично сделанных вещей. Но люди в продуктовой разработке не видят и не ощущают настолько сильно всю боль от их очередей.
Но всё же, они там есть. Очереди НЗР — информация, документация и биты на диске. Незаметные очереди. Люди из разработки продуктов нуждаются в хорошем уроке по “Чутью на Очереди”, чтобы они начали ощущать что происходит и вырабатывать ощущение срочности в отношении уменьшения размеров очередей.
Визуальное управление для осязаемых (материальных) очередей — Чтобы развить“Чутьё на Очереди” и внимательность, существует одна практика в бережливом подходе визуальное управление, создание физических жетонов (не в компьютерной программе) для этих очередей. Например, популярная практика - представить все задачи в Спринте в виде бумажных карточек, которые располагаются на стене и перемещаются по мере выполнения задач. Аналогично для высокоприоритетных задач в Бэклоге Продукта. Эти физические, ощутимые карточки делают по-настоящему видимыми незаметные очереди которые скрыты где-то внутри компьютера. Сокрытие этой информации внутри компьютеров противоречит этому стремлению бережливого подхода к визуальному (физическому) управлению и тому, как люди — с бессчётным количеством эпох эволюции вырабатывающие инстинкт работать с конкретными, ощутимыми вещами — нуждаются в том чтобы видеть и чувствовать осязаемые очереди .
Косвенные Преимущества Уменьшения Размеров Партий и Времени Цикла
“К чему беспокоиться? Наши клиенты не хотят обновлений каждые две недели, также как они не хотят получать только результаты подтребований вместо масштабных обновлений.”
Мы слышим такой вопрос регулярно от продуктовых групп и людей, приближенных к бизнесу. Они еще не оценили преимущества небольших партий в коротких циклах:
- Общее глобальное сокращение времени релизного цикла, которое может случиться благодаря ликвидации очередей и применению практик управления очередями, таким образом циклы разработки становятся короче.
- Устранение пакетной задержки, когда одна небольшая новая функциональность неоправданно сдерживается из-за того, что она связанна с большой партией других требований. Устранение этого переводит вас на следующую ступень свободы, что позволяет поставлять меньший продукт раньше с выскоприоритетной функциональностью.
- Последнее, но при этом не менее важное, существуют косвенные преимущества благодаря эффекту “камни в озере ”, описанному ниже.
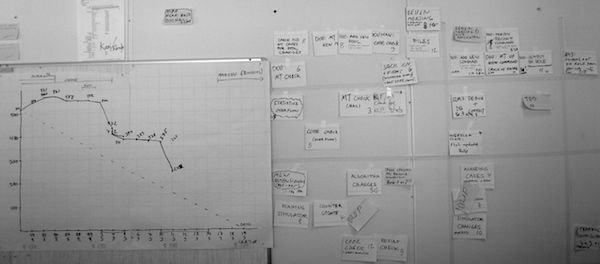
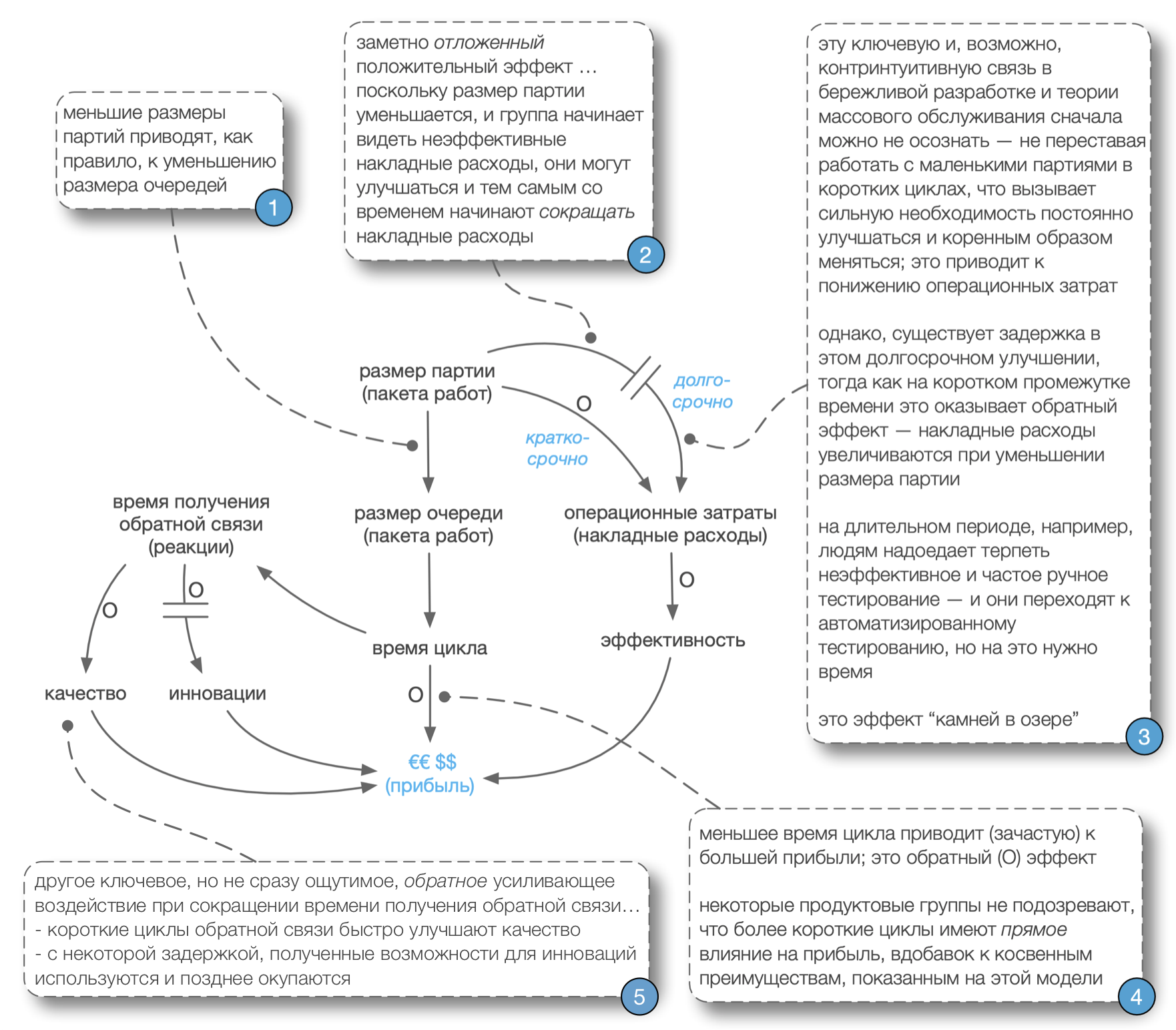
Косвенные Преимущества: Метафора о Камнях в Озере
Метафора из бережливого подхода: камни в озере. Глубина озера представляется в виде количества запасов, размеров партий, длины итерации, или времени цикла. Когда вода в озере высока (большие объёмы партий, или количество запасов, или длина итерации), многие подводные камни скрыты на дне озера. Эти камни представляют собой недостатки. Например, рассмотрим восемнадцатимесячный цикл релиза с масштабным пакетом изменений; неэффективное тестирование, интеграция, плохое взаимодействие скрыты под “поверхностью” такого длинного цикла и такого огромного пакета требований. Но если бы мы работали с этой группой и попросили бы их: “Пожалуйста, создавайте готовый к поставке небольшой набор новой функциональности каждые две недели,” то все неэффективные практики неожиданно стали бы болезненно очевидными.

Говоря другими словами, операционные затраты (накладные расходы) из предыдущего цикла процесса становятся неприемлемыми. Эта боль затем станет позывом к улучшению, поскольку люди не смогут вынести повторения этого снова и снова, в каждом коротком цикле, и на самом деле это может быть просто недопустимо для целей итерации: оставаться в рамках старой неэффективной системы разработки.
Совет: Не все ‘камни’ достаточно большие, чтобы быть замеченными сразу. Путь бережливого подхода — и путь Скрама — заключается в том, чтобы начать с больших камней, которые наиболее болезненны, однако, по всей видимости, подвержены устранению, и со временем уже работать с меньшими препятствиями.
Эта диаграмма причинно-следственных циклов (нотация диаграммы объясняется в Системном Мышлении) иллюстрирует эффект камней на дне озера в терминах модели системной динамики:
Применение Управления Очередями в LeSS
Существуют десятки стратегий для управления очередями. Managing the Design Factory Дональда Рейнертсена рассказывает о многих из них. Однако, в контексте LeSS мы хотели бы сфокусироваться на нескольких ключевых шагах:
- измените саму систему, чтобы полностью ликвидировать очереди
- научитесь обнаруживать оставшиеся очереди с помощью визуального управления
- уменьшайте вариативность
- ограничивайте размер очереди
Измените систему — Должны ли вы управлять существующими очередями? Шагните за границы привычного мышления. Например, фича-команды, приёмочное TDD, непрерывная поставка - всё это помогает избавиться от многих очередей в традиционной разработке.
Уменьшайте вариативность — Некоторые люди сначала пытаются уменьшить рабочие очереди через увеличение утилизации или многозадачность (с отрицательным результатом), или добавляя больше разработчиков. Действительно, добавление людей — если они талантливы — может помочь (за некоторыми исключениями), но это дорого и требует времени. Люди, которые достаточно понимают в управлении очередями, осознали более простую отправную точку: Уменьшайте вариативность особого характера, которая включает в себя сокращение размера партии.
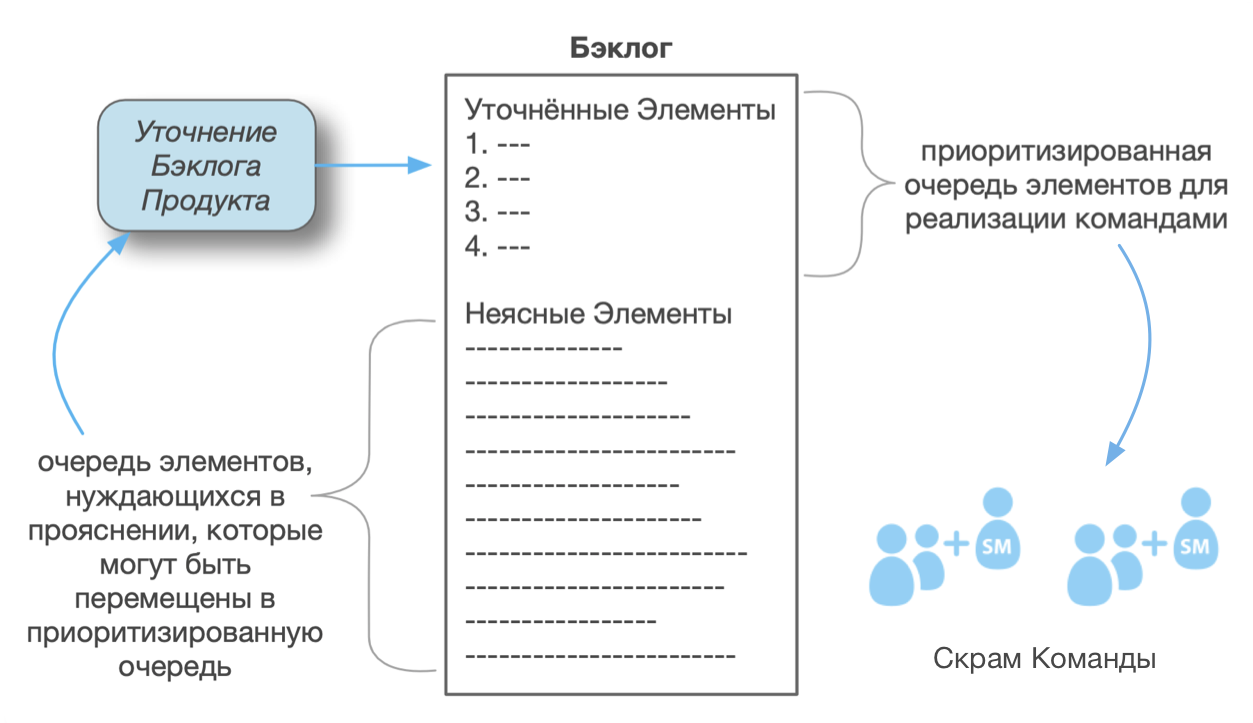
Можно представить Бэклог Продукта, как некую большую почти бесконечную приоритизированную очередь, но мы рекомендуем более детальный взгляд. Он имеет различные подмножества. Согласно одной точке зрения он содержит два подмножества: (1) список элементов, входящих в текущий релиз (который в идеале должен быть каждый Спринт), и (2) “будущий бэклог”. Другой взгляд заключается в том, что Бэклог Продукта содержит два следующих подмножества:
- уточнённое подмножество элементов, которые детально проанализированы, хорошо оценены, прекрасно раздроблены и сбалансированы (выровнены) так, чтобы их можно было сделать за гораздо меньшее время, чем длится Спринт для одной команды
- неясное подмножество крупно-дроблёных элементов разного размера, нуждающихся в более детальном анализе, оценке и разделении на более мелкие, для того чтобы попасть в “уточнённое” подмножество
Оба подмножества “текущий релиз” и “будущий бэклог” могут содержать уточнённые и неясные элементы. В начале релизного цикла, “текущий релиз” как правило содержит, в основном, неясные элементы, и Спринт за Спринтом они проясняются, пока не станут уточнёнными, а затем реализованными.
Это подводит к некоторым ключевым моментам:
- В LeSS принято — и рекомендуется — приоритизировать только уточнённое подмножество “текущего релиза”.
- В LeSS, такая “уточнённая приоритизированная очередь” является критически важной очередью работы, стоящей перед командами.
- Неясное подмножество является некой очередью подачи элементов в процесс Уточнения Бэклога Продукта, который добавляет высококачественные небольшие элементы в уточнённое подмножество.
Прежде чем чересчур увлечься идеей уменьшения вариативности… современная разработка программного обеспечения не является промышленным производством; без вариаций ничего нового не происходит или не открывается. Существование вариативности в исследованиях и разработке как свойственно так и неизбежно. Однако действительно, есть некоторые виды изменчивости, которые могут быть снижены — тема текущей главы. В терминологии Эдварда Деминга существует вариативность (вариабельность) общего характера и вариативность особого (специального) характера. Первая категория - это вариация общего шума (системные отклонения, прим. переводчика), присущие самому процессу, связь которой с каким-либо специфичным (внешним) случаем сложно определить. С другой стороны, вариабельность особого характера (случайные внешние вмешательства, прим. переводчика) — также известная как определяемая вариабельность — может быть идентифицирована. Например, вариативность размера запроса на новую функциональность является вариативностью особого характера. А также работа с плохо проанализированными, нечёткими требованиями - это тоже вариативность особого характера. Путём сокращения поддающейся идентификации вариативности особого характера — в LeSS или в рабочих процессах — в системе с очередями улучшается средняя пропускная способность.
Вариативность является одним из трёх источников потерь в бережливом мышлении (оставшиеся два - это перегрузка и не приносящие ценности действия ). Понимание теории массового обслуживания помогает прояснить, почему вариативность расценивается как источник потерь.
Каковы некоторые источники и качества вариативности в LeSS?
- большие партии и большие элементы
- неоднозначность понимания элементов
- неоднозначность в том, как спроектировать/реализовать элементы
- различающиеся затраты (оценка) для разных элементов
- количество элементов в уточнённой приоритизированной очереди “текущего релиза”
- различие между ожидаемыми и фактическими затратами, которое может быть следствием неоднозначности что/как, неумелой оценки, обучения и прочего
- скорость поступления элементов в уточнённую приоритизированную очередь текущего релиза
- вариативность команды и её отдельных членов
- перегрузка или отказ общих ресурсов, таких как тестовая лаборатория и т.п.
… и тому подобное (список не полон). В терминологии моделирования очередей, все они обычно сводятся к вариативности на уровне обслуживания или скорости поступления.
В бережливом мышлении, поток является ключевым принципом — и поток требует уменьшения или устранения вариативности. Вот почему балансировка (выравнивание) также является и принципом бережливого подхода; это антидот для вариативности и помогает двигаться в направлении потока.
Уменьшение Вариабельности Особого Характера в LeSS
Вышесказанное приводит к некоторым советам по уменьшению вариабельности особого характера в LeSS:
Уменьшайте вариативность с помощью небольшой очереди (играющей роль буфера) уточнённых пользовательских историй в Бэклоге Релиза, примерно одинакового размера — В Toyota, небольшой буфер высококачественных запасов деталей используется, чтобы сгладить или выровнять передачу работы в последующий связанный процесс. Эти запасы (являющиеся временно необходимыми потерями) поддерживают сбалансированное вытягивание потому, что продуктовые команды LeSS теперь имеют очередь элементов для работы, примерно одинакового размера; никаких ожиданий и меньше неожиданностей. Элемент в неясном подмножестве текущего релиза имеет высокую неоднозначность что/как и довольно крупный; поэтому выбор его для реализации - это непрофессионально, так как увеличивает вариативность.
Уменьшайте вариативность, проводя совместную сессию по Уточнение Бэклога Продукта (PBR) каждый Спринт — В LeSS, каждый спринт должен включать PBR для уточнения элементов, таким образом они становятся готовыми для будущих Спринтов. Это уменьшает неоднозначность или вариативность что/как, а также уменьшает вариативность в оценке, потому что точность при переоценке может улучшаться по мере того, как люди учатся. На протяжении этой активности разбивайте элементы на небольшие и примерно одинаковые. Это сокращает размер партии и сопутствующую ему вариативность. Это также сокращает пакетную задержку — искусственная задержка важной функциональности потому, что она застряла в большей партии изменений, часть которых являются менее важными. Эти повторяющиеся сессии совместной работы также создают регулярную каденцию по добавлению уточнённых элементов в очередь, уменьшая вариативность в скорости поступления.
Уменьшайте вариативность благодаря стабильным продуктовым командам — Используйте стабилизировавшиеся, работающие совместно на протяжении долгого времени продуктовые команды в LeSS, чтобы уменьшить вариативность на уровне ‘обслуживания’ — в командах. Также, кросс-функциональные, кросс-компонентные продуктовые команды увеличивают параллелизм и улучшают поток потому, что элемент может быть передан в любую из нескольких доступных команд.
Уменьшайте вариативность с помощью ограниченных по времени и затратам исследовательских задач — Этот совет наиболее пригоден в областях с крупными исследовательски-ориентированными требованиями. Это уменьшает неоднозначность что/как и вариативность. Иногда нетривиальное исследование необходимо для того, чтобы только начать понимать исследуемую тему. Например, однажды мы занимались консультацией в офисе у заказчика в Будапеште; продуктовая группа мобильных телекоммуникаций собиралась начать разрабатывать сервис “рации” на базе сотовой сети. Документация по международному стандарту в этой области насчитывает тысячи страниц. Чтобы только поверхностно понять эту тему, требуются колоссальные усилия. Один из подходов - это попросить команду “изучить предметную область.” Однако это работа, не имеющая чётких границ, способная привнести больше вариативности в обслуживании и может привести к потерям, которые в бережливом подходе классифицируются как переработка. Альтернативный подход — то, что рекомендуется в LeSS — предложить команде ограниченную по времени и по затратам цель для изучения. Возможно, конкретной целью могло бы быть предоставление отчёта об исследовании в конце Спринта, в дополнении к работе по реализации элементов бэклога. Например, “подготовить вводный доклад про конференц-связь, за максимум 30 человеко-часов.” Некое ограниченное количество затрат отводится на исследование и изучение, сбалансированное с некоторым количеством реализуемых командой элементов. Затем Владелец Продукта мог бы принять решение инвестировать ещё некоторое количество ограниченных усилий в следующий цикл исследований в будущем Спринте (вероятно уже более сфокусированных по мере прояснения предмета исследований), до тех пор пока предмет не был бы окончательно понятен для людей в достаточной степени, чтобы начать формировать, разделять и оценивать элементы бэклога.
Сокращение Размеров Очередей в LeSS
Другая техника управления очередями - ограничение размеров очередей. Это не всегда уменьшает вариативность, но при этом имеет некоторые другие достоинства. В традиционной разработке очереди НЗР функционируют по принципу: “первым пришел - первым ушёл” (first-in first-out, FIFO), длинная очередь является проблемой, потому что может пройти вечность прежде чем элемент продвинется в очереди и в конечном счёте будет завершен — очевидная причина, чтобы ограничивать размер FIFO очереди НЗР.
Эта проблема менее пагубна в приоритизированной очереди Бэклога Продукта, поскольку он может быть пересортирован — только что добавленный элемент может быть перемещён вверх списка. Но, несмотря на это, существуют веские причины ограничивать количество элементов в уточнённой приоритизированной очереди текущего релиза:
- Длинный список уточнённых комплексных историй тяжело понять и приоритизировать. В крупномасштабной разработке продуктов, мы регулярно слышим жалобы Владельца Продукта, что бэклог слишком большой, чтобы осознать его.
- Большой бэклог чётко проанализированных, мелко поделённых и хорошо оценённых элементов обычно требует инвестиций на всё это, которые пропорциональны его размеру. Это НЗР с неполученным возвратом этих инвестиций. Как обычно, в случае с НЗР или запасами, это является финансовым риском.
- Люди забывают подробности с течением времени. Все элементы в уточнённом подмножестве прошли через углубленный анализ на совместных сессиях по Уточнению Бэклога Продукта. Если этот список короткий, то велик шанс того, что команда реализует элемент, который был недавно проанализирован в рамках совместной работы, может быть в течение последних двух месяцев. Если очередь очень длинная и растущая, существует больше шансов, что команда возьмёт элемент, проанализированный достаточно давно. Даже несмотря на то, что вероятно была создана документация, сформированная давным-давно на совместной сессии, она, конечно, будет неполноценной и их понимание деталей будет туманным и устаревшим.
Заключение
Управление очередями может стать “молотком”, с которым вы можете ходить и искать “гвозди” - очереди. Но сопротивляйтесь искушению в первую очередь управлять существующими очередями — что является ответом на проблему, лежащим в рамках привычных границ мышления. Скорее, рассмотрите возможность применения системного кайдзена так, чтобы сама система была изменена некоторым образом, из-за чего очереди больше не могли бы формироваться и существовать. Распараллеливание с кросс-функциональными командами и разработкой через приёмочное тестирование являются распространёнными примерами, но есть и другие. Применяйте управление очередями только тогда — кайдзен-направленная тактика — когда вы не можете ликвидировать саму очередь.
Рекомендованная Литература
Существуют десятки, если не сотни, основополагающих текстов о теории массового обслуживания. Мы предлагаем более конкретную литературу, в которой раскрывается связь этого предмета с разработкой продуктов:
-
Managing the Design Factory Дона Рейнертсена, является классическим введением в теорию массового обслуживания и разработку продуктов.
-
Flexible Product Development Престона Смита, была первой массово-популярной книгой по основам продуктовой разработки, которая представила широкой аудитории концепцию гибкой разработки — включая Скрам и Экстремальное Программирование. Этот текст включает анализ теории массового обслуживания и вариативности, и их взаимосвязи с разработкой.
Перевод статьи осуществлён Романом Лапаевым, Дмитрием Емельяновым и Кротовым Артёмом.